这一部分我们将会介绍NumPy的基础知识。NumPy (Numerical Python 的简称),是高性能科学计算和数据分析的基础包。
文章目录(Table of Contents)
Numpy介绍
NumPy (Numerical Python 的简称),是高性能科学计算和数据分析的基础包。
NumPy 提供了对多维数组(矩阵)的高效支持,同时还有以下优点:
- ndarray, 核心数据结构,支持矢量运算的多维数组,在内存中进行连续存储;
- 各种操作多维数组和进行数组间运算的数学函数(不需要编写循环);
- 用于集成其他编程语言的各种接口;
NumPy 本身没有提供高级的数据分析功能,但理解 NumPy 数组以及面向数组的各种计算有助于更加高效使用其他数据分析工具。
多维数组的创建
Numpy的核心是多维数组,通过ndarray对象做到,ndarray对象是一个灵活的数据容器,可以基于此数据容器对数据进行各种运算。
关于ndarray这个名字,写全的话应该是The N-dimensional array,即nd是N-dimensional的缩写。
通过np.array创建数组
好了,下面正式开始来讲多维数组的创建。
首先我们通过import导入numpy,之后我们就不在写这句了。
- import numpy as np
我们首先创建二维数组a1
a1 = np.array([[1,2,3,4],[5,6,7,8]])
a1.shape # 输出数组的形状
>> (2,4)
a1.ndim # 输出数组的维度,这里是二维数组
>> 2
a1.size # 输出数组中一共有多少元素,这里是4*2
>> 8
a1.max() # 输出a1中最大的元素
>> 8
a1
>> array([[1, 2, 3, 4],
[5, 6, 7, 8]])其他更多的方法,我们可以在ipython终端中,通过输入ndarray对象后,输入.,再按下tab键进行查看。
其他创建数组的方法
除了前面介绍的直接使用np.array创建数组外NumPy还有多种方法可以创建多维数组:
np.arange类似于 Python 内置的 range,创建一维数组;np.ones创建元素值全部为 1 的数组;np.zeros创建元素值全为 0 的数组;np.empty创建空值多维数组,只分配内存,不填充任何值;np.random.random创建元素值为随机值的多维数组;
我们依次看一下上面创建数组的方法
np.arange创建数组
a1 = np.arange(1,4)
>> array([1,2,3])我们可以通过help(np.arange)来进行查看如何使用。
np.ones创建数组
生成一个全1的数组
a1 = np.ones((4,4),dtype=np.int64)
>> array([[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1]])np.zeros创建数组
a1 = np.zeros((3,3))
>> array([[ 0., 0., 0.],
[ 0., 0., 0.],
[ 0., 0., 0.]])np.random.random创建数组
a1 = 3*np.random.random((3,3))+3
>> array([[ 4.88904983, 5.16038279, 3.10275584],
[ 5.28394531, 5.50129641, 5.97119755],
[ 3.10108378, 3.4346571 , 4.25520641]])这里写出np.random.random的原因是因为np.random后面可以跟除了random以外的其他方法,如np.random.shuffle,具体可以使用help(np.random)来进行查看。
使用reshape创建数组
reshape方法并不能直接创建数组,而是可以将一个数组变成其他维度的数组。
其实,这一种方法配合np.arange还是很常用的。之后举例子的时候我们会看到具体的用法。
多维变成一维
a1 = np.ones((2,2))
a1.reshape(4)
>> array([ 1., 1., 1., 1.])
a1.reshape((1,4))
>> array([[ 1., 1., 1., 1.]])一维变成多维
a1 = np.arange(12)
a1.reshape((3,4))
>> array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])多维数组索引
在python中,可以使用:来进行选择部分元素:
l = [1,2,3,4,5]
l[:2] #选择前两个元素
>> [1,2]
l[1:5:2]
>> [2,4]关于这部分的内容,可以查看之前写得python基础,Python入门教程[2]–列表,元祖,集合,字典
在NumPy中的多维数组中,也支持类似上面的索引方式,下面我们来看一下。
一维数组切片
a1 = np.arange(7)
a1
>> array([0, 1, 2, 3, 4, 5, 6])
a1[:3] #取前三个数
>> array([0, 1, 2])
a1[0:6:2]
>> array([0,2,4])多维数组切片
对于二维数组,可以通过 a[x, y] 的方式进行索引,三维数组可以通过 a[x, y, z] 的方式进行。
a1 = np.arange(12).reshape((3,4))
>> array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
a1[1,1] #这个是选取第2行第2列的元素,因为下标是从0开始的
>> 5
a1[1] # 这个是选取第2行的元素a1
>> array([4, 5, 6, 7])
a1[:,1] # 这个是选取第1列的内容
>> array([1,5,9])下面我们来看一下三维数组的操作,如果能理解上面的,下面的也就是巩固一下自己的理解。
a1 = np.arange(12).reshape((2,2,3))
>> array([[[ 0, 1, 2],
[ 3, 4, 5]],
[[ 6, 7, 8],
[ 9, 10, 11]]])
a1[1,1,1]
>> 10
a1[1] # 注意和下面的进行比较
>> array([[ 6, 7, 8],
[ 9, 10, 11]])
a1[:,1] # 选取第二个维度的内容,可以理解为在第一个和第二个数组里的第二行
>> array([[ 3, 4, 5],
[ 9, 10, 11]])
a1[:,:,1] # 选取第三个维度的内容
>> array([[ 1, 4],
[ 7, 10]])numpy进行倒序输出
有的时候我们需要对numpy中的数据进行从后往前的输出, 于是可以使用下面的方式进行操作:
- np.array([1,2,3,4,5,6])[::-1]
最终的效果如下所示:

数组的合并
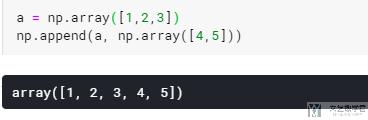
append 进行添加
- a = np.array([1,2,3])
- np.append(a, np.array([4,5]))
最终的结果显示如下:
concatenate 进行合并
在 numpy 中,我们可以使用 concatenate 来进行合并:
- a1 = np.array([1,2,3])
- a2 = np.array([4,5,6])
- # numpy进行合并
- np.concatenate([a1, a2])
- """
- array([1, 2, 3, 4, 5, 6])
- """
当数组是2维的时候, 我们合成的数组也是按照堆叠的方式进行合并, 如下面的例子.
- test = np.array([[1,2,3]])
- np.concatenate((test, test))
- """
- array([[1, 2, 3],
- [1, 2, 3]])
- """
在list的时候,我们可以直接使用+来进行合并(使用append会有一些问题)
- a1 = [1,2,3]
- a2 = [4,5,6]
- # list进行合并
- a1+a2
- """
- [1, 2, 3, 4, 5, 6]
- """
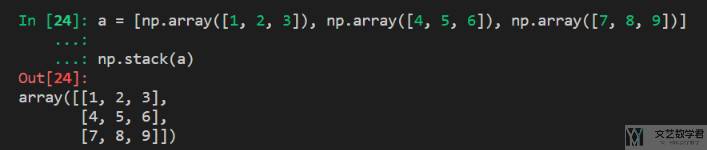
stack 进行合并
除了使用 concatenate 来进行合并之外,还可以使用 stack 来进行堆叠。下面看一个例子:
- a = [
- np.array([1,2,3]),
- np.array([4,5,6]),
- np.array([7,8,9])
- ]
- np.stack(a)
最终的结果如下所示,可以看到将多个 np.array 合并为一个(此时需要 array 的长度是一样的):
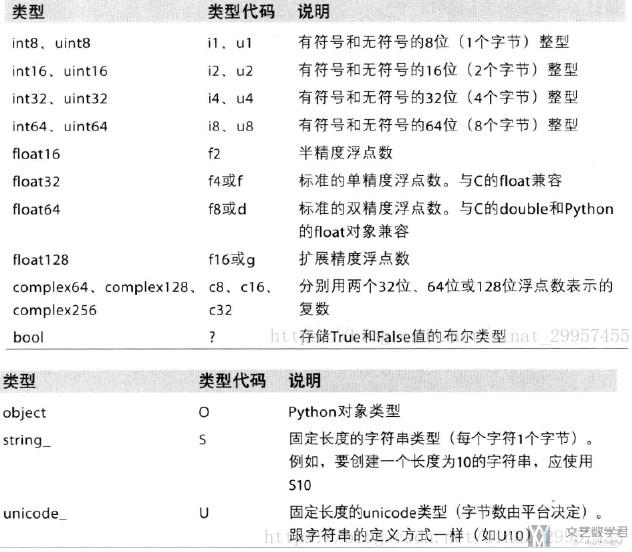
numpy 中的数据类型
参考资料: numpy的数据类型
内容来源于上面的链接, 对于numpy的数据类型还是整理的很好的.
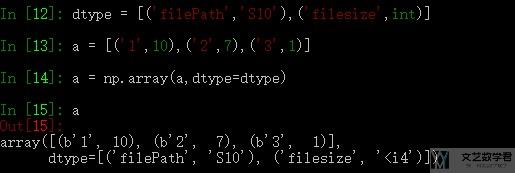
数组的排序
我们可以使用np.sort来对numpy的数组进行排序. 详细的例子可以查看官网的Example, numpy.sort. 下面放一个简单的例子.
我们生成的时候可以固定他的type和name, 之后可以按照name进行排序
下面就是使用np.sort进行排序后的结果.

多维数组的基础运算
在python自带的列表中,如果想要使得数组中每个元素都加上同一个数,需要使用便利来实现
l = [1,2,3]
[i+1 for i in l]
>> [2,3,4]但是在Numpy中,就不需要这么复杂,我们可以直接像普通的加减法一样简洁。
多维数组与标量的运算
a1 = np.arange(12).reshape((3,4))
>> array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
a1+1
>> array([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])
a1*2
>> array([[ 0, 2, 4, 6],
[ 8, 10, 12, 14],
[16, 18, 20, 22]])多维数组间的运算
普通的加减乘除是数组元素两两进行运算,若要进行矩阵乘法,我们可以使用a.dot(b)进行矩阵乘法。
a1 = np.arange(1,5).reshape((2,2))
>> array([[1, 2],
[3, 4]])
a2 = np.arange(5,9).reshape((2,2))
>> array([[5, 6],
[7, 8]])
a1+a2
>> array([[ 6, 8],
[10, 12]])
a1*a2 # 这里不是矩阵乘法,是元素两两相乘
>> array([[ 5, 12],
[21, 32]])
a1.dot(a2) # 这个才是矩阵乘法
>> array([[19, 22],
[43, 50]])多维数组的逻辑运算
除了上面讲到的简单的数学运算,多维数组还是支持逻辑运算的,我们看一下下面的应用。
a1 = np.random.random(9).reshape(3,3)
>> array([[ 0.92924529, 0.68050394, 0.09914842],
[ 0.5489492 , 0.05738463, 0.35223837],
[ 0.43749942, 0.81850431, 0.75036973]])
b = a1 > .5
a1[b]
>> array([ 0.92924529, 0.68050394, 0.5489492 , 0.81850431, 0.75036973])上面的代码中,我们首先通过a1>.5生成一个和a1形状一致的多维数组,所有为True的元素位置在a1中都大于.5,之后我们就可以使用a1[b]这种方式列出a1中大于0.5的元素。
一些统计方法
做数据处理的时候,我们经常需要用到一些统计方法,下面就介绍一些常用的统计方法。
- a.sum 计算多维数组的所有元素的和;
- a.max 最大值计算;
- a.min 最小值计算;
- a.mean 平均值计算;
- a.std 标准差计算;
- a.var 方差计算;
以上所有方法,都可以接受一个axis参数,用于指定具体统计哪根轴上的数据。比如二维数组,可以理解为有x, y两根轴,分别代表行和列.
- 指定
axis=0时代表分别统计每列上的数据; - 指定
axis=1时,代表分别统计每一行上的数据; - 没有指定
axis参数时,代表统计所有元素。
我们看一下下面的例子
- a1 = np.arange(9).reshape((3,3))
- >> array([[0, 1, 2],
- [3, 4, 5],
- [6, 7, 8]])
- a1.var() # 计算方差
- >> 6.66667
- a1.std() # 计算标准差
- >> 2.58198
- a1.std()**2 # 标准差的平方为方差
- >> 6.6667
- a1.sum(axis=0) # 每一列求和
- >> array([ 9, 12, 15])
- a1.sum(axis=1) # 每一行求和
- >> array([ 3, 12, 21])
每n个元素进行运算
参考链接: Averaging over every n elements of a numpy array
有的时候我们会遇到需要每次对array中的n个元素进行操作, 下面就简单说明一下操作的方式. 其实也是很简单, 只需要使用reshape即可. 下面看一个例子.
我们需要达到下面的要求, 也就是没三个元素进行求平均值.
- """
- Input: np.array([1,2,3,1,2,3,1,2,3])
- Output: np.array([2,2,2])
- """
其实方法也是很简单, 只需要使用reshape即可, 如下所示:
- np.mean(arr.reshape(-1, 3), axis=1)
这样就可以得到上面的要求了.
找出数据中的指定值的位置
我们可以使用np.where来找出指定元素在array中出现的位置, 如下面的例子.
- a = np.array(['a', 'b', 'c'])
- np.where(a=='b')
- """
- (array([1], dtype=int64),)
- """
找出最大元素的位置
有的时候我们需要找出array中最大元素的index, 特别是在分类问题的时候, 由于输出的是每一类的概率, 所以我们要看最大的概率是在哪一类. 我们可以使用下面的方式来找出最大值的index.
- b = np.array([[1,2,30,5,3],[4,5,6,8,10]])
- # 找出最大元素的值
- b.max(axis=1)
- """
- array([30, 10])
- """
- # 找出最大元素的index
- b.argmax(axis=1)
- """
- array([2, 4], dtype=int64)
- """
我们来使用a.argmax来完成找出最大值的index的任务.
统计每一个元素出现的次数
有的时候, 我们需要统计array中不同元素出现的次数, 就可以使用下面的方式.
- a = numpy.array([0, 3, 0, 1, 0, 1, 2, 1, 0, 0, 0, 0, 1, 3, 4])
- unique, counts = numpy.unique(a, return_counts=True)
- dict(zip(unique, counts))
- # >>> {0: 7, 1: 4, 2: 1, 3: 2, 4: 1}
参考资料, How to count the occurrence of certain item in an ndarray in Python?
其他
交换axis
有的时候我们会有如下的需求, 原本的大小为(70, 70, 3), 我们想要将shape变为(3, 70, 70), 可以使用numpy.transpose来完成我们需要的工作. 参考文档: numpy.transpose
下面我们看一个例子.
- a = np.array([[[1,2],[5,6],[8,9]], [[1,2],[5,6],[8,9]],[[2,3],[5,6],[8,9]],[[2,3],[5,6],[8,9]]])
- a.shape
- """
- (4, 3, 2)
- """
我们进行交换, 使其从(4, 3, 2)=>(2, 3, 4)
- b = np.transpose(a, (2,1,0))
- b.shape
- """
- (2, 3, 4)
- """
看一下最终的结果.
- array([[[1, 1, 2, 2],
- [5, 5, 5, 5],
- [8, 8, 8, 8]],
- [[2, 2, 3, 3],
- [6, 6, 6, 6],
- [9, 9, 9, 9]]])
产生随机数
产生指定区间的随机数,例如下面的例子,会生成范围在 1.1 到 2.1 之间的随机数。np.random.uniform(1.1, 2.1)

关于取整
四舍五入,np.around(a, decimals=0, out=None), 可以使用 decimals 来指定精度。

下取整,np.floor 返回不大于输入参数的最大整数。
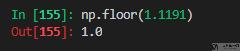
上取整,np.ceil 函数返回输入值的上限,即对于输入 x ,返回最小的整数 i ,使得 i> = x。
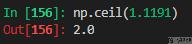
设置显示精度
- np.set_printoptions(suppress=True)
- np.set_printoptions(precision=5) #设精度为5
以上就是关于numpy的介绍,放在这里方便自己查阅。
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-










2019年5月15日 上午2:38 1F
很有帮助,赞