文章目录(Table of Contents)
简介
这一篇会介绍一下Python中Pillow的简单使用. Pillow是在Python中常见的图像处理的库. 我们在这里会通过例子, 介绍一下常见的功能.
参考资料
- Python OpenCV 的相关说明,Python OpenCV 使用介绍
- Pillow官方文档, Image Module, Pillow, Image Module
- 关于palette的各种用法的说明, Convert image to specific palette using PIL without dithering
- 关于Dither的一些说明, 从仿色图案(Dither Pattern)到半调(Halftone)
Pillow常见功能介绍
我们使用如下的图片进行所有功能的测试.

打开图片并显示
- from PIL import Image
- im = Image.open("./test.jpg")
- im.rotate(45).show()
这里我们不仅打开了图片, 还对其进行旋转. 最终得到了如下的效果.

获取图像大小与获得缩略图
下面的代码可以将图片大小转换为128×128.
- from PIL import Image
- im = Image.open("./test.jpg")
- print(im.size) # (414, 338)
- # 获得缩略图
- im.thumbnail((128, 128), resample=Image.NEAREST)
- im.save("test_thumbnail.jpg", "JPEG")
从 Numpy 导入并保存
假设下面 A 是 numpy array,那么就可以按照下面来将其转换为图片:
- from PIL import Image
- im = Image.fromarray(A)
- im.save("your_file.jpeg")
图像大小的放缩-resize
我们可以使用 resize 对原始的图像进行放缩。下面的代码,可以将原始图像转换为指定的 width 和 height 大小的图像。
- img = img.resize((width, height), Image.ANTIALIAS)
图片的融合-blend
我们可以使用 pillow 来对两张图片进行融合(需要注意的是,这里 Image.blend 合并时候需要两个图片大小相等,且是对整个图片进行融合,如果想要有更加复杂的操作,可以使用 Image.composite,这个会在后面有讲到)。如下有两张图片,分别是一头牛的轮廓:

和按照这个牛生成的字符画,字符画的生成方式如下面链接所示,Python生成字符画

我们可以将上面的两张图融合在一起,这样可以更好看出字符画是什么动物,使用 blend 来进行融合,如下所示:
- img = Image.open('./niu_2.png')
- background = Image.open('niu_1.jpg')
- background = background.convert('RGBA') # 两个图片的格式需要相同
- img = Image.blend(background, img, 0.7)
- img.save('out_with_background.png')
最终的效果如下所示,可以看出这个时候效果会更加明显:

参考资料,ValueError: images do not match when blending pictures in PIL
JPEG 与 PNG 之间的转换
首先是将 png 的图像转换为 jpeg。
- from PIL import Image
- im = Image.open("Ba_b_do8mag_c6_big.png")
- rgb_im = im.convert('RGB')
- rgb_im.save('colors.jpg')
接着是将 jpeg 的图像转换为 png,只需要将上面的 RGB 替换为 RGBA 即可。
- im = im.convert("RGBA")
Image.Crop
使用Image.Crop来进行图像的裁剪. 图像的坐标如下图所示:
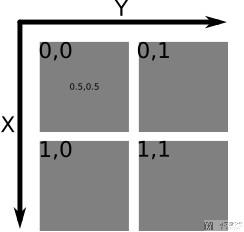
我们首先获得图像的长和宽, 之后通过除2, 获得图像的左上角.
- from PIL import Image, ImageOps
- img = Image.open('./profile_color.jpg')
- width, height = img.size
- new_img = img.crop((0, 0, width/2, height/2))
- new_img.show()
Image.putpalette
在说这个函数之前, 我们首先介绍一下什么是一个图像的palette. Palette相当于是一个图像的所使用的颜色的集合, 类似于画家手中的颜色盘 (An image palette is a collection of colors that an image uses — similar to a painter's palette).
一个图像的 palette 表示我们在显示器上能看到的所有颜色, 只有在 16-256 色之间的图片会有palette. (An image palette is a subset of all the colors your monitor can display. Not all images have image palettes — only images with color depths between 16 and 256 colors have palettes that you can fine-tune and edit)
Images with a color depth of 16 million colors do not have an image palette because they can contain all the colors your computer can display. For these images, you can load an image palette to decrease the image's color depth to 256 colors (8-bit). (对于一些图片, 我们可以减少palette的格式)
下面我们自定义一个 palette, 然后将其应用到一张图片上. 我们会使用 putpalette 来完成. 下面是putpalette 的详细介绍.
Attaches a palette to this image. The image must be a "P" or "L" image, and the palette sequence must contain 768 integer values (这里是256色, 每一个颜色有RGB三通道, 所以一共是768个整数), where each group of three values represent the red, green, and blue values for the corresponding pixel index. Instead of an integer sequence, you can use an 8-bit string.
我们在这个 palette 里面只使用 4 种颜色, 对于的 RGB 分别是:
- (0, 0, 0)
- (102, 102, 102)
- (176, 176, 176)
- (255, 255, 255)
- from PIL import Image
- oldimage = Image.open("./test.jpg")
- palettedata = [0, 0, 0, 102, 102, 102, 176, 176, 176, 255, 255, 255]
- newimage = Image.new('P', oldimage.size) # 创建一个和oldimage一样大的图像, 模式为P
- newimage.putpalette(palettedata * 64) # 指定palette, 这里需要将palette变换为768长度的list
- newimage.paste(oldimage, (0, 0) + oldimage.size) # 将原始图片粘贴过来
- newimage.show()
于是, 还是使用上面的图像, 我们可以将其转换为只包含四种颜色.

Image.quantize
除了上面的方式进行转换外, 我们可以使用 quantize 来完成相同的工作.
Convert the image to 'P' mode with the specified number of colors.
在这里我们的 palette 里面还是只使用 4 种颜色. 我们是直接用过 quantize 进行转换, 而不需要新建一个图像, 然后通过 paste 来完成。
- from PIL import Image
- image = Image.open("./test.jpg")
- palettedata = [0, 0, 0, 102, 102, 102, 176, 176, 176, 255, 255, 255]
- palimage = Image.new('P', (16, 16))
- palimage.putpalette(palettedata * 64)
- newimage = image.quantize(palette=palimage)
- newimage.show()
最终的效果图如下所示:

Image.convert
同样的功能, 我们可以使用 Image.convert 来完成. 在这里会遇到 ImageCore 的相关问题. 下面做一些简单的说明.
The parts of PIL implemented in C are in the PIL._imaging module, also available as Image.core after you from PIL import Image. Current versions of Pillow give every PIL.Image.Image instance a member named im which is an instance of ImagingCore, a class defined within PIL._imaging. You can list its methods with help(oldimage.im), but the methods themselves are undocumented from within Python.
The convert method of ImagingCore objects is implemented in _imaging.c. It takes one to three arguments and creates a new ImagingCore object (called Imaging_Type within _imaging.c).
mode(required): mode string (e.g."P")dither(optional, default 0): PIL passes 0 or 1paletteimage(optional): AnImagingCorewith a palette
下面是完整的代码:
- def quantizetopalette(silf, palette, dither=False):
- """Convert an RGB or L mode image to use a given P image's palette."""
- silf.load()
- # use palette from reference image
- palette.load()
- if palette.mode != "P":
- raise ValueError("bad mode for palette image")
- if silf.mode != "RGB" and silf.mode != "L":
- raise ValueError(
- "only RGB or L mode images can be quantized to a palette"
- )
- im = silf.im.convert("P", 1 if dither else 0, palette.im)
- # the 0 above means turn OFF dithering
- # Later versions of Pillow (4.x) rename _makeself to _new
- try:
- return silf._new(im)
- except AttributeError:
- return silf._makeself(im)
- if __name__ == "__main__":
- # 读取图像
- from PIL import Image
- image = Image.open("./test.jpg")
- palettedata = [0, 0, 0, 102, 102, 102, 176, 176, 176, 255, 255, 255]
- palimage = Image.new('P', (16, 16))
- palimage.putpalette(palettedata * 64)
- newimage = quantizetopalette(image, palimage, dither=False)
- newimage.show()
同时, 这里我们可以选择是否要dither, 我们分别来看一下True和False时候的效果. 当dither=False的时候, 是没有散的色块的, 都是大的色块.

当dither=True的时候, 得到的图像就是会有小的散点状.

转换为灰度图
上面提到了的convert, 还可以将图像转换为灰度图. 灰度图使用L来表示. 计算公式如下所示:
L = R * 299/1000 + G * 587/1000 + B * 114/1000
- from PIL import Image
- img = Image.open('test.jpg').convert('L')
- img.show()
Image.point
还有一个比较常用的函数就是point, 它可以依次对图像中的像素点进行处理. 我们看下面的一个例子.
- from PIL import Image
- img = Image.open('test.jpg').convert('L')
- img = img.point(lambda color: color > 100 and 255)
- img.show()
该段语句的作用就是, 对每个像素点进行判断, 如果大于100, 那么就是0, 否则就是255. 于是, 最终得到的图像如下所示:

参考资料, How to I use PIL Image.point(table) method to apply a threshold to a 256 gray image
不同的滤波
- from PIL import Image, ImageFilter
- im = Image.open('./test.jpg')
- # im = im.filter(ImageFilter.BLUR) # 模糊
- # im = im.filter(ImageFilter.SMOOTH_MORE) # 平滑
- im = im.filter(ImageFilter.CONTOUR) # 边缘提取
- im.show()
例如上面的滤波可以对图像进行边缘检测, 结果如下所示:

- 不同滤波的说明, 中文博客, Python图像处理库PIL的ImageFilter模块介绍
- 不同种类的滤波, 官方文档, ImageFilter Module
OpenCV 格式与 Pillow 格式互相转换
有一点需要牢记:
OpenCV中图像的颜色空间是BGR;Pillow中的颜色空间是RGB;
OpenCV 格式到 Pillow 格式
图片通过 OpenCV 读取是 numpy 的格式,通过 Image.fromarray() 将其转换为 pillow 的格式:
- img = cv2.imread("./cat.png")
- img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
- print(type(img)) # <class 'numpy.ndarray'>
- im_pil = Image.fromarray(img) # 转换为 pillow 格式
- print(type(im_pil)) # <class 'PIL.Image.Image'>
参考资料,Convert opencv image format to PIL image format?
Pillow 格式到 OpenCV 格式
将 pillow 格式转换为 OpenCV 格式其实就是转换为 numpy 的格式。我们只需要使用 np.array(或是 np.asarray,这个节约内存) 即可。注意下面进行了颜色空间的转换(转换到了 OpenCV 使用的 BGR 颜色空间)。
- pil_image = Image.open('./cat.png').convert('RGB')
- open_cv_image = cv2.cvtColor(np.array(pil_image), cv2.COLOR_RGB2BGR) # 转换为 opencv 的格式
参考资料,Convert image from PIL to openCV format
图片的合并
有的时候我们需要将两张图片进行拼接(或是「横向拼接」,或是「纵向拼接」)。于是我们的想法是创建一个新的空白图片,将要拼接的图片粘贴上去即可:
首先导入需要使用的库:
- import numpy as np
- import copycopy
- from PIL import Image
将两个图像水平方向进行拼接,其中 ratio 表示拼接的时候留白,可以在 Image.new 中的 color 调整留白的颜色:
- def get_concat_h(im1, im2, ratio=0.05):
- """水平方向将两个 image 进行合并
- """
- _im1 = copycopy.deepcopy(im1)
- _im2 = copycopy.deepcopy(im2)
- if type(_im1).__module__ == np.__name__:
- _im1 = Image.fromarray(np.uint8((1-_im1)*255), 'L') # L 表示「灰度图」
- if type(_im2).__module__ == np.__name__:
- _im2 = Image.fromarray(np.uint8((1-_im2)*255), 'L')
- width = int(ratio*_im2.width)
- dst = Image.new(mode='L', size=(width + _im1.width + _im2.width, _im1.height), color=(0))
- dst.paste(_im1, (0, 0))
- dst.paste(_im2, (width + _im1.width, 0))
- return dst
将两个图像垂直方向进行拼接。其中 ratio 表示拼接的时候留白,可以在 Image.new 中的 color 调整留白的颜色:
- def get_concat_v(im1, im2, ratio=0.1):
- """垂直方向将两个 image 进行合并
- """
- _im1 = copycopy.deepcopy(im1)
- _im2 = copycopy.deepcopy(im2)
- if type(_im1).__module__ == np.__name__:
- _im1 = Image.fromarray(np.uint8((1-_im1)*255), 'L')
- if type(_im2).__module__ == np.__name__:
- _im2 = Image.fromarray(np.uint8((1-_im2)*255), 'L')
- height = int(ratio*_im2.height)
- dst = Image.new('L', (_im1.width, height + _im1.height + _im2.height), (255))
- dst.paste(_im1, (0, 0))
- dst.paste(_im2, (0, height + _im1.height))
- return dst
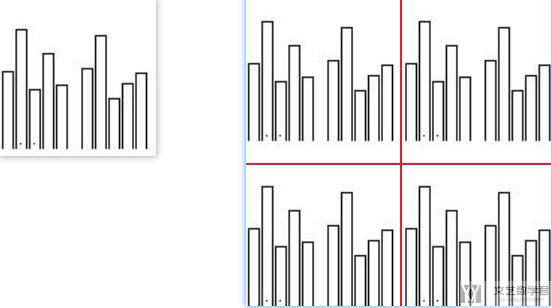
现在我们希望把一张图片变成四分,左右拼接,接着垂直拼接:
- _tmp_1 = get_concat_v(example_data, example_data)
- _tmp_2 = get_concat_v(example_data, example_data)
- _tmp = get_concat_h(_tmp_1, _tmp_2)
- _tmp.save('._tmp.jpg')
最终的效果如下所示:
参考资料,Concatenate images with Python, Pillow
合并两张图片-Image.composite
在 Pillow 中,我们可以使用 Image.composite 来合并两张图片。需要注意的是,Image.composite 需要两张相同大小的图像。
这一小节的内容,主要参考自链接,Composite two images according to a mask image with Python, Pillow
Image.composite 的简单使用
我们想要将以下的两张图像进行简单的合并:


我们首先导入这两张图片,并创建一个相同大小的 mask,这个遮罩就是一个灰色的图像。这里 mask 会对 im1 进行遮挡,接着和 im2 进行合并(如果把 mask 的 color 设置为 0,那么就只有 im2 的图像了):
- im1 = Image.open('./lena.jpg')
- im2 = Image.open('./rocket.jpg').resize(im1.size)
- mask = Image.new("L", im1.size, 128) # 创建遮罩
- im = Image.composite(im1, im2, mask)
- im.show()
上面的 mask 如果显示出来,则如下图所示:

最终上面的两幅图像合并的效果如下所示:

上面的操作和我们直接使用 Image.blend 的效果是一样的,如下所示:
- im = Image.blend(im1, im2, 0.5)
创建特定形状的 mask
上面我们是对全局图片做了合并,有的时候我们需要我们的这周为特殊的形状。如下所示我们创建一个在人脸部分有空白的遮罩:
- im1 = Image.open('./lena.jpg')
- im2 = Image.open('./rocket.jpg').resize(im1.size)
- # 创建 mask
- mask = Image.new("L", im1.size, 0) # 默认为黑
- draw = ImageDraw.Draw(mask)
- draw.ellipse((140, 50, 260, 170), fill=255) # 中间部分为白
- mask.show()
- # 进行合并
- im = Image.composite(im1, im2, mask)
- im.show()
遮罩的形状如下图所示:

最终两张图片合并的效果如下图所示,这个 mask 会首先和 im1 进行合并,然后在和 im2 进行合并,所以最终只会把人脸部分显示出来:

我们还可以对 mask 的边缘部分进行处理,加入一些透明度:
- mask_blur = mask.filter(ImageFilter.GaussianBlur(10))
- im = Image.composite(im1, im2, mask_blur)
最终的效果如下所示:

图片上添加文字
有的时候, 我们需要在图片上加上文字, 这个时候就需要使用 ImageDraw 来完成。下面看一个简单的例子, 我们使用 ImageDraw 将导入的图片当作背景,接着写入文字的内容。
- from PIL import Image, ImageDraw, ImageFont
- im = Image.open('./test.jpg')
- # initialise the drawing context with
- # the image object as background
- draw = ImageDraw.Draw(im)
- font_fname = './legofy/times.ttf'
- font_size = 50
- font = ImageFont.truetype(font_fname, font_size)
- (x, y) = (0, 0) # 文字显示位置
- message = "Hello World!"
- color = 'rgb(0, 0, 0)' # black color
- # draw the message on the background
- draw.text((x, y), message, fill=color, font=font)
- im.show()
最终的图片效果如下图所示:

有的时候, 我们的文字过长, 图片里面一行是放不下的, 我们需要进行换行, 于是我们需要对输入的一段文字, 按照长度进行划分. 首先我们定义一个函数, 用来对文字的长度进行划分.
- def text_wrap(text, font, max_width):
- lines = []
- # If the width of the text is smaller than image width
- # we don't need to split it, just add it to the lines array
- # and return
- if font.getsize(text)[0] <= max_width:
- lines.append(text)
- else:
- # split the line by spaces to get words
- words = text.split(' ')
- i = 0
- # append every word to a line while its width is shorter than image width
- while i < len(words):
- line = ''
- while i < len(words) and font.getsize(line + words[i])[0] <= max_width:
- line = line + words[i] + " "
- i += 1
- if not line:
- line = words[i]
- i += 1
- # when the line gets longer than the max width do not append the word,
- # add the line to the lines array
- lines.append(line)
- return lines
这里函数的输入分别是:
- text: 要分割的文字;
- font: 文字的大小, 字体, 用来计算一行可以放多少文字;
- max_width: 这里一般是图片的宽度;
接着我们定义绘图的函数, 借助上面的 text_wrap, 对较长的文字进行分割之后, 我们使用循环进行绘制. 这里只需要依次改变 y 轴的位置即可. 于是我们定义了 draw_text 函数, 如下所示.
- def draw_text(text):
- # open the background file
- img = Image.open('./test.jpg')
- draw = ImageDraw.Draw(img)
- # size() returns a tuple of (width, height)
- image_size = img.size
- # create the ImageFont instance
- font_file_path = './legofy/fonts/times.ttf'
- font = ImageFont.truetype(font_file_path, size=50)
- # get shorter lines (自动进行分割)
- lines = text_wrap(text, font, image_size[0])
- print(lines) # ['This could be a single line text ', 'but its too long to fit in one. ']
- x = 10
- y = 20
- color = 'rgb(0,0,0)'
- line_height = font.getsize('hg')[1] # 获得行间距
- for line in lines:
- # draw the line on the image
- draw.text((x, y), line, fill=color, font=font)
- # update the y position so that we can use it for next line
- y = y + line_height
最终, 我们来测试一下最后的效果.
- draw_text("This could be a single line text but its too long to fit in one.")
最终图像的效果如下所示:

参考资料
- 这一篇介绍基础的使用Pillow在图片上添加文字, PUTTING TEXT ON IMAGE USING PYTHON – PART I
- 这一篇介绍比较进阶的, 如何自动对文字进行换行, PUTTING TEXT ON IMAGES USING PYTHON – PART 2
添加水印
添加文字水印
这里我们利用前面介绍的 ImageDraw 在图片上添加指定的文字,来添加文字水印。
- from PIL import Image, ImageDraw, ImageFont
- def add_num_watermark(img,content):
- """加文字水印
- """
- draw = ImageDraw.Draw(img)
- myfont = ImageFont.truetype('./STKAITI.TTF', size=40)
- fillcolor = "#ff0000"
- width, height = img.size # 获得图片大小
- content_len = len(content) # 获得文字的长度
- draw.text((width-content_len*50, height-50), content, font=myfont, fill=fillcolor)
- img = img.convert("RGB") # 转换为 RGB, 用来保存为 jpeg 格式
- img.save('result_num.jpg', 'jpeg')
- return 0
我们使用下面的图像来进行测试(原始图片是没有下面的图片水印的):

我们使用下面的方式来在图像上添加「文艺数学君」的水印:
- content = '文艺数学君'
- image = Image.open('./62.png')
- add_num_watermark(image, content)
最终生成的效果如下图所示,可以看到图片的右下角有文字水印:

添加图片水印
所谓添加图片水印就是将想要的「水印图片」与原始图像进行合并。主要有以下的几个步骤:
步骤一:创建一个和原始图像一样大小的图像,并在右下角放置水印图像;

步骤二:创建一个 mask,只有在图像水印部分有灰度值(相当于透明度),其他位置都是黑色:

步骤三:将上面创建的两个图片,与原始图像进行合并即可。下面是完整的代码:
- def add_pic_waterMark(im,mark):
- """加图片水印
- """
- im = im.convert('RGBA')
- # 创建 layer, 原始图像大小, 但是右下角有水印
- mask_width, mask_height = mark.size # 获取水印的大小
- layer = Image.new('RGBA', im.size, (0, 0, 0, 0))
- layer.paste(mark, (im.size[0] - mask_width, im.size[1] - mask_height)) # 放置水印, 左下角位置
- layer.show()
- # 创建 mask, 只把「水印」部分显示, 同时加一些透明度
- mask = Image.new('L', im.size, 0)
- draw = ImageDraw.Draw(mask)
- draw.polygon([
- (im.size[0] - mask_width, im.size[1] - mask_height),
- (im.size[0] - mask_width, im.size[1]),
- (im.size[0], im.size[1]),
- (im.size[0], im.size[1] - mask_height)
- ], fill=77)
- mask.show()
- # 图像合并
- out = Image.composite(layer, im, mask)
- out = out.convert("RGB")
- out.save('result_pic.jpg', 'jpeg')
- return 0
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论