文章目录(Table of Contents)
Request 的简单使用
Request构造请求参数
这里介绍一个例子,进行 url 的构造后进行请求(常用语请求一些 api 的接口,如历史天气)。这里会使用 Request 进行完成。
- #coding:utf-8
- import json,urllib
- try:
- from urllib.parse import urlencode
- except ImportError:
- from urllib import urlencode
- #from urllib.request import urlopen
- import requests
- def get_message(find_date):
- url = 'http://api.k780.com'
- params = {
- 'app' : 'weather.history',
- 'weaid' : '1',#城市id
- 'date' : find_date,#查询日期
- 'appkey' : '33690',
- 'sign' : 'bdcf684483992488f5d296a53b846283',
- 'format' : 'json',
- }
- params = urlencode(params)
- try:
- f = requests.get('%s?%s' % (url, params))
- while f.status_code != 200: # 重复请求
- f = requests.get('%s?%s' % (url, params))
- html=f.content # 获取请求内容
- nowapi_call=str(html)
- a_result = json.loads(nowapi_call)
- return a_result
上面的代码作为一个小的样例,可以在params中定制自己需要的参数。
使用 Requests 下载文件
我们可以使用 request 下载图片或是一些文本,直接使用 get 即可。下面是一个例子,使用request 下载并保存图片。
- # 下载图片内容
- _iamge_data = requests.get(image_url) # 图片内容
- while _iamge_data.status_code!=200:
- _iamge_data = requests.get(image_url) # 图片内容
- time.sleep(5)
- # 保存图片
- with open(_tmp.jpg', "wb") as text_file:
- text_file.write(_iamge_data.content)
使用 Request 下载大文件
我们可以使用 request 下载一些比较大的视频。参考自下面的链接,How to download large files with requests in Python
我们使用 requests.get(url, stream) 来从一个链接下载文件,同时设置 stream 是 True 来在 Response object 中可以使用 iter_content 同时保持 connection 是 open 的。接着使用 Response.iter_content(chunk_size) 来 load 一个固定大小的 chunk_size。下面看一个简单的例子。
- url = 'xxxx'
- # 设置 stream=True
- response = requests.get(url, stream = True)
- with open('{}.txt'.format(file_name), "wb") as text_file:
- for chunk in response.iter_content(chunk_size=1024):
- text_file.write(chunk)
Request 登陆 Basic Access Authentication
有的时候我们爬取网页的时候需要一个简单的登陆。例如下所示,在登陆网站的时候,会弹出一个需要登陆的框。这种形式的验证是 HTTP Basic 的身份验证,关于 HTTP Basic 的身份验证的详细说明,可以查看链接,一文读懂HTTP Basic身份认证
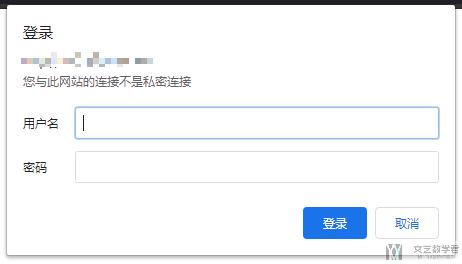
要登陆这种类型的网站,只需要在 request 中设置 auth 即可。主要这里我们使用的是 requests.get 而不是 post.
- import requests
- from requests.auth import HTTPBasicAuth
- url='xxxx'
- r = requests.get(url=url, auth=HTTPBasicAuth('admin', 'admin'))
- print(r.status_code)
如果用户名和密码正确的话,请求时会自动认证成功,返回 200 状态码;如果认证失败,则返回 401 状态码。
当然,如果参数都传一个 HTTPBasicAuth 类,就显得有点烦琐了,所以 requests 提供了一个更简单的写法,可以直接传一个元组,它会默认使用 HTTPBasicAuth 这个类来认证。所以上面的代码可以直接简写如下:
- import requests
- url='xxxxxx'
- r = requests.get(url, auth=('admin', 'admin'))
- print(r.status_code)
参考资料,爬虫中的身份认证问题
Requests-HTML的使用
加上header和使用代理
有的时候我们需要模拟浏览器的结果, 所以我们需要加上header. 有的时候我又需要使用代理. 这两个功能在request-HTML都是很方便的进行实现的.
- session = HTMLSession()
- proxie = {
- 'http': 'http://127.0.0.1:1080',
- }
- headers = {
- 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36',
- # 'Cookie': '__cfduid=d38a3b9c5846e5db96ef23a5eb78642e91530061695'
- }
- # 进行爬取
- r = session.get(url,proxies=proxie,headers=headers)
数据提取CSS Selector
我们使用百度首页做一个例子,我们想要获得value中的值, 我们分别可以使用下面两种方式。

- from requests_html import HTMLSession
- session = HTMLSession()
- url = 'https://www.baidu.com/'
- r = session.get(url)
根据 ID 进行提取
- # 通过ID的方式搜索
- for i in r.html.find('span input#su'):
- print(i.lxml.xpath('//@value'))
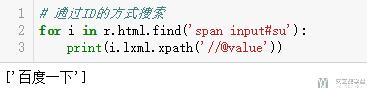
我们可以看到上面id为su的input,被span包裹,所以提取的时候写法为:span input#su.
根据 class 进行提取
- # 通过class的方式搜索
- for i in r.html.find('span input.s_btn'):
- print(i.lxml.xpath('//@value'))
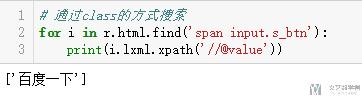
通过class进行提取的时候,使用.的记号进行提取,如这里的input的class是s_btn,就可以写成input.s_btn来进行提取。
数据提取 Xpath
XPath 是一门路径提取语言,常用于从 html/xml 文件中提取信息。它的基规则如下:
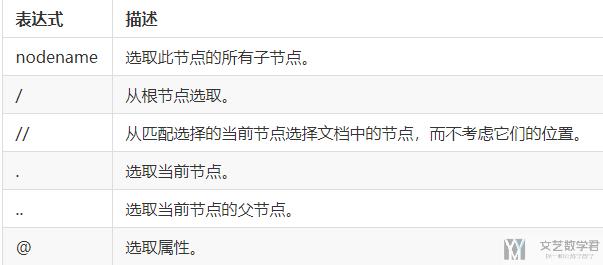
我们在上面的提取中,为了提取 input 中 value 属性的值,就已经使用了 xpath 了,具体可以看重新看一下上面的例子。
下面讲两个上面没有讲到的,可以利用 text() 来从 element 中提取文本,如下所示:
- dom_tree.xpath("//div[@class='b-content corner']//text()"):
或是使用 tostring 的方式来将 element 显示出来:
- for i in dom_tree.xpath("//div[@class='b-content corner']"):
- print(etree.tostring(i, pretty_print=True, encoding="utf8").decode('utf-8'))
自动解析js代码
在request-html中提供了解析js代码的操作. 我们可以进行如下的操作来进行提取:
- r = session.get(url,headers=headers)
- r.html.render()
我们也可以直接解析js代码, 直接提取了相应的js代码进行解析
- # 提取js代码
- result = re.search('<script>(.*)</script>', js)
- js = result.group(1)
- # 运行js代码
- val = r.html.render(script=js, reload=False)
如果出现一些比较复杂的js的情况, 比如返回状态码是521, 爬取巴比特快讯遇到状态码“521”, 我们可以尝试使用selenium来进行操作, 相关的内容介绍参考: python selenium介绍
这里简单说明一下遇到521的情况的原因:
这时浏览器访问网站时:
- 第一次请求:返回521状态码和一段js代码。js会生成一段cookie并重新请求访问;
- 第二次请求:带着第一次得到的cookie去请求然后正确返回状态码200;
Cannot use HTMLSession within an existing event loop. Use AsyncHTMLSession instead
如果出现报错信息为"Cannot use HTMLSession within an existing event loop. Use AsyncHTMLSession instead.", 这是由于jupyter notebook造成的, 只需要不使用jupyter notebook即可.
一个Requests-HTML的例子
上面只是简单讲了一下Request-HTML的用法, 下面看一个具体的例子. 也是看一下爬虫通常会有哪些步骤, 一个好的代码(比较规范)会写成什么样子的.
下面的一个例子是获取网站上每一页图片的例子, 主要的步骤如下所示:
- 读取想要爬取的网页的url
- 获得所有的页面(如果可以, 一下获得所有的连接, 不要每次判断是否翻页)
- 获取每一页图片的链接
- 图片的下载
创建session, 进行初始化
导入需要的库.
- from requests_html import HTMLSession
- from multiprocessing import Pool
- import os, threading, time
- import random
接着我们创建session, 并定义header和proxy.
- session = HTMLSession()
- proxie = {
- 'http': 'http://127.0.0.1:1080',
- }
- headers = {
- 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36',
- # 'Cookie': '__cfduid=d38a3b9c5846e5db96ef23a5eb78642e91530061695'
- }
获取需要爬取的链接
有的时候, 我们会将我们需要爬取的链接写入文本, 这样可以方便我们进行修改. 我们可以使用下面的方式进行读取.
- # --------------
- # 读取文件中的url
- # --------------
- def duqu():
- with open('list.txt', 'r') as f:
- url_list = f.readlines()
- return url_list
获取所有的链接
我们一次把获取要爬取的所有页面的链接(如果可以的话), 后面就不用进行翻页的判断了.
- # --------------------
- # 获得漫画所有页面的链接
- # --------------------
- def get_page_list(url):
- print('开始获取漫画分页列表')
- firstPage = session.get(url,proxies=proxie)
- container = firstPage.html.find('.entry-content .page-links', first=True).links
- title = firstPage.html.find('header h1.entry-title', first=True).text
- num = len(container) # 漫画链接的数量
- link_list = [url+'/'+str(x) for x in range(1,num+2)] # 生成所有需要的链接
- print("漫画链接: \n{}".format(link_list))
- print("漫画标题: \n{}".format(title))
- print('获取漫画分页列表完成')
- return title,link_list
获得图片链接
上面我们获取了每一页的链接, 下面我们获取每一页图片的链接, 我们暂时只把图片的链接保存下来, 先不对图片进行保存, 保存在后面进行操作.
- # ----------------
- # 获得图片所有的链接
- # ----------------
- def get_img_list(page_list):
- """
- 按顺序获得每一页的所有图片链接
- """
- img_list = []
- for page in page_list:
- r = session.get(page,proxies=proxie)
- time.sleep(random.random()*5) # 每次获得图片的时候停顿一下, 不要跑太快了
- single_page_list = r.html.find('.entry-content div.single-content p')
- img_list += [img.find('p img')[1].attrs['src'] for img in single_page_list]
- # print(img_list)
- print('获取图片列表完成')
- return img_list
图片的保存
有了图片的链接之后就是进行图片的保存了, 我们加入了一个文件夹是否存在的判断. 这里图片的保存我们使用多线程来进行操作.
- # ---------
- # 图片的保存
- # ---------
- def mkdir(path):
- # 引入模块
- import os
- # 去除首位空格
- path=path.strip()
- # 去除尾部 \ 符号
- path=path.rstrip("\\")
- # 判断路径是否存在
- # 存在 True
- # 不存在 False
- isExists=os.path.exists(path)
- # 判断结果
- if not isExists:
- # 如果不存在则创建目录
- # 创建目录操作函数
- os.makedirs(path)
- print(path+' 创建成功')
- return True
- else:
- # 如果目录存在则不创建,并提示目录已存在
- print(path+' 目录已存在')
- return False
- def saver(mkpath, img_url, n ,total):
- """
- mkpath: 图片保存的文件夹
- img_url: 要保存的图片的url
- n: 要保持的图片的编号
- total: 所有的图片的数量
- """
- img_url = img_url.strip()
- res = session.get(img_url,proxies=proxie,headers=headers)
- # print(res.content)
- with open(mkpath + '\\%03d.jpg' % n,'wb') as f:
- f.write(res.content)
- print('第%03d张图片下载完成/共%03d张图片' % (n,total))
- def save(img_urls,title):
- n = 1
- mkpath = './comic/' + title # 漫画保存的路径
- total = len(img_urls)
- mkdir(mkpath) # 如果没有对应文件夹就进行创建
- for img_url in img_urls:
- t = threading.Thread(target=saver,args=(mkpath,img_url,n,total))
- t.start()
- t.join()
- n += 1
主程序
把上面所有需要的东西都定义好之后, 我们把他们按顺序组合起来. 这样写方便后面使用多进程.
- # -------
- # 主程序
- # ------
- def run(url):
- title,page_list = get_page_list(url)
- imgurls = get_img_list(page_list)
- save(imgurls,title)
开始爬取
最后一步就是开始爬取了, 我们在这里使用了多进程的方式, 可以同时爬取多个链接.
- if __name__ == '__main__':
- url_list = duqu()
- p = Pool(2)
- print('begin')
- for url in url_list:
- url = url.strip()
- p.apply_async(run,args=(url,))
- p.close()
- p.join()
- print('All finished!!!')
参考链接

- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












2021年3月6日 下午6:53 1F
“Cannot use HTMLSession within an existing event loop. Use AsyncHTMLSession instead”
能详细讲一下怎么操作吗?我现在也遇到了这个问题,html.render()方法一运行就报错,github上也没有合适的解决方案(已经把Jupyter Notebook从Anaconda里面卸载了,还是有问题)
2021年3月22日 上午11:02 B1
@ geada 你好,你现在解决了嘛。我当时是不使用 jupyter notebook 就可以解决,直接使用脚本来运行。