文章目录(Table of Contents)
简介
这里介绍一个可以一键生成数据报告的库, Pandas Profiling. 他可以生成一份pandas DataFrame的报告. 用他自己的介绍就是, "Create HTML profiling reports from pandas DataFrame objects".
他最终生成的内容会包含以下的内容:
- Essentials: type, unique values, missing values (最基本的信息, 数据类型, 出现不同值的占比, 缺失值的信息)
- Quantile statistics like minimum value, Q1, median, Q3, maximum, range, interquartile range (统计性信息, 最小值, 1,3分位数, median, 最大值, 取值范围, 四分位数)
- Descriptive statistics like mean, mode, standard deviation, sum, median absolute deviation, coefficient of variation, kurtosis, skewness (描述性统计, Mean, Standard deviation标准差, Variance方差, Coef of variation, Kurtosis, MAD, Skewness, Sum)
- Most frequent values (最常出现的values)
- Histogram (数据的直方图)
- Correlations highlighting of highly correlated variables, Spearman, Pearson and Kendall matrices (会将一些有高相关性的变量标亮出来)
- Missing values matrix, count, heatmap and dendrogram of missing values
参考链接
- Github链接: Pandas Profiling
- 样例展示: Pandas Profiling样例展示
样例展示
下面我们使用实际的数据, 来看一下最终生成的report的效果. 我们首先按步骤来生成一份report.
- import numpy as np
- import pandas as pd
- import pandas_profiling
接着我们导入要生成report的数据集.
- # 导入训练集
- training = pd.read_csv('./data/training-set.csv', delimiter=',')
- training.shape
最后就是进行report的生成即可, 我们将report保存为html.
- profile = training.profile_report(title='Training Data')
- profile.to_file(output_file="Training_Data.html")
最后, 我们来看一下生成的report中包含的内容.
Essentials
对于每一个变量, report中会包含一些基础的信息. 如下图所示, 对于一个数值型变量, 他会包含总的个数, 不同value的data的占比, 是否包含缺失值.

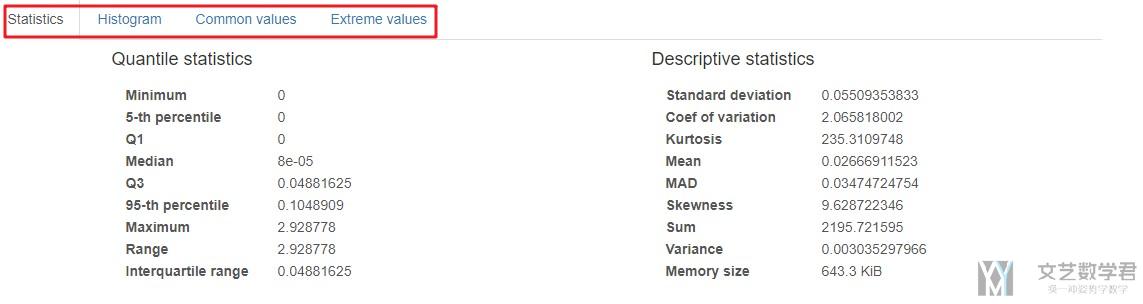
Quantile statistics&Descriptive statistics
我们点击上图中的Toggle details, 可以查看到这个变量中更加详细的信息. 这里左侧是Quantile Statistics, 右侧是Descriptive Statistics.
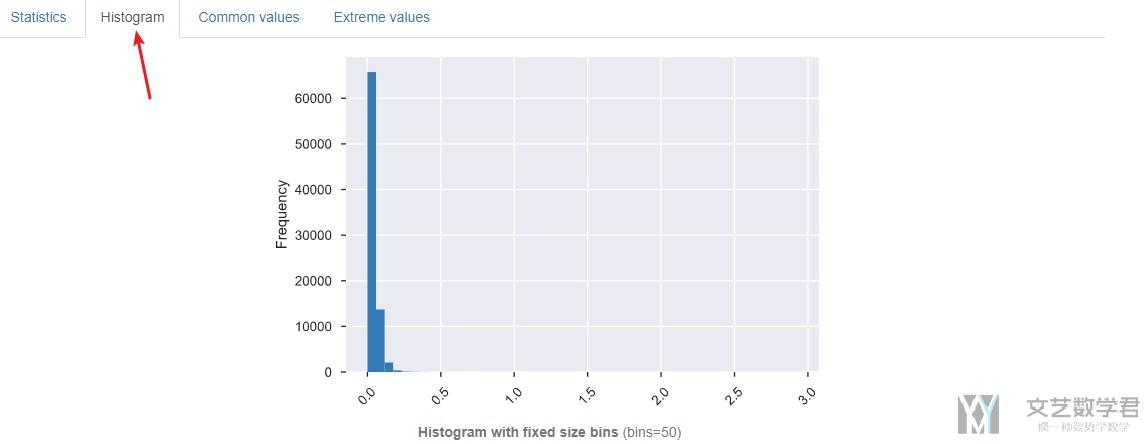
Most frequent values&Histogram
我们可以从直方图这很明显的看出数据的分布.
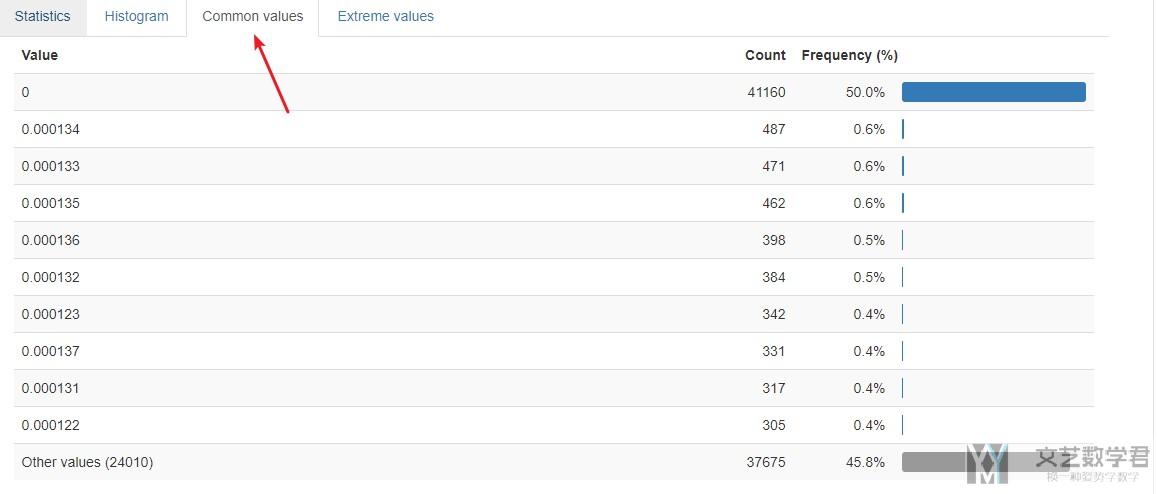
我们也是可以通过common values来查看不同values出现的频率.
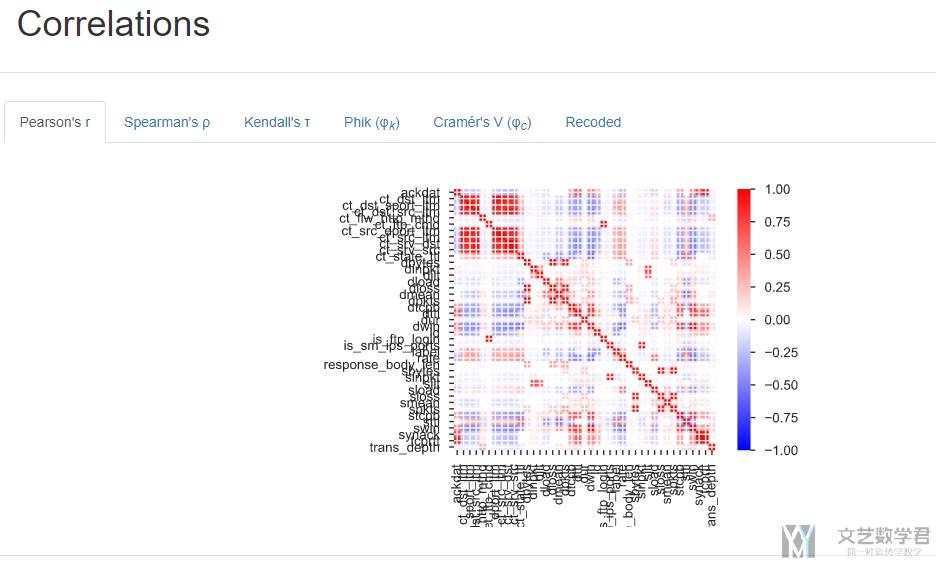
Correlations
对于一些有高相关性的变量, report中也是会给出提示.

同时, 也会给出变量的相关性矩阵的可视化.
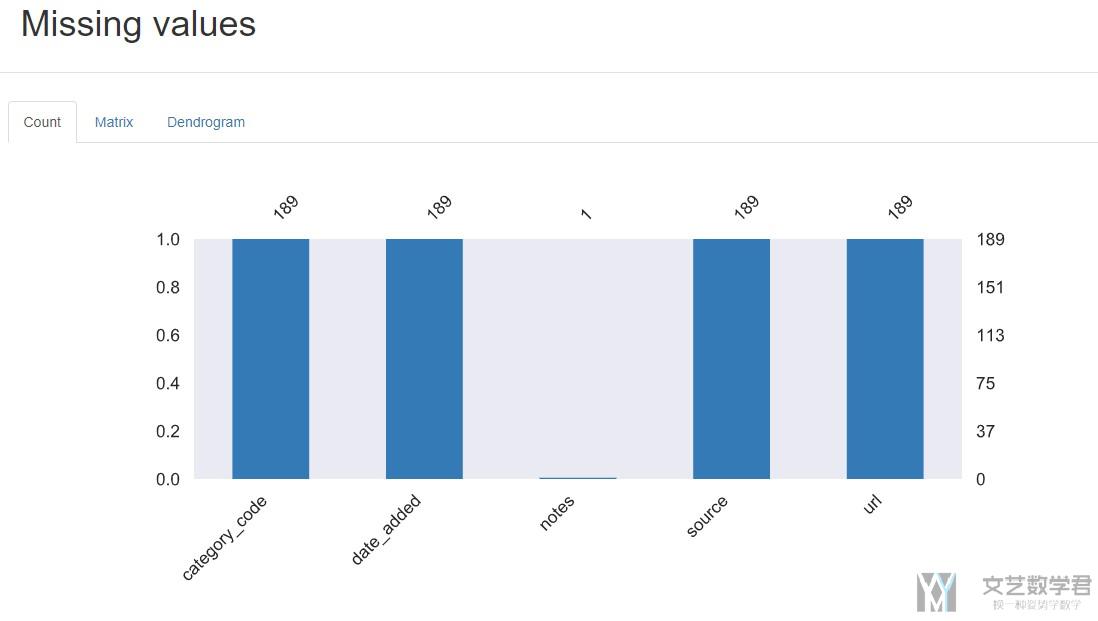
Missing values
对于各个变量的缺失值, 也是有一个直方图来进行了解. 如下图中notes只出现了1次, 其他变量都出现了189次.
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论