文章目录(Table of Contents)
简介
这里我们介绍 Python 来处理 xml 文件的方法。目前,有三种主要的读写 xml 文件的方式,分别如下所示:
- SAX (simple API for XML), python 标准库包含 SAX 解析器,SAX用事件驱动模型,通过在解析XML的过程中触发一个个的事件并调用用户定义的回调函数来处理
XML文件。 - DOM(Document Object Model), 将 XML 数据在内存中解析成一个树,通过对树的操作来操作XML。
- ElementTree(元素树), ElementTree 就像一个轻量级的 DOM,具有方便友好的 API。代码可用性好,速度快,消耗内存少。
参考资料
- 本文主要的内容参考自(这一篇还是写的非常详细的): 使用Python读写xml文件
- python 使用ElementTree解析xml
- Python xml.etree.ElementTree解析XML文件
测试文件
下面是本文会使用的 xml 的测试文件,后面的实验都会基于这个文件进行:
- <?xml version='1.0' encoding='UTF-8'?>
- <books>
- <book>
- <name>Python黑帽子</name>
- <date>2015</date>
- <price bookName="Python黑帽子">37</price>
- <description>用python写一些程序</description>
- </book>
- <book>
- <name>Web安全深度剖析</name>
- <date>2014</date>
- <price bookName="Web安全深度剖析">39</price>
- <description>讲述web渗透的基础知识</description>
- </book>
- <book>
- <name>白帽子讲web安全</name>
- <date>2013</date>
- <price bookName="白帽子讲web安全">44</price>
- <description>道哥力作</description>
- </book>
- </books>
使用SAX解析XML文件
SAX会在解析XML的过程中触发一个个的事件并调用用户定义的回调函数来处理XML文件. 我们常会用到:
- startElement(name, attrs)方法, 他在遇到XML开始标签时调用, name是标签的名字, attrs是标签的属性值字典.
- characters(content)方法, 他会提取每一个xml标签内的值. 每一次都会触发.
在有了ContentHandler的对象之后, 会使用parser方法来解析xml文档. 下面是完整的sax.parse的参数说明:
- xml.sax.parse( xmlfile, contenthandler[, errorhandler])
- - # 参数说明:
- - # xmlfile - xml文件名
- - # contenthandler - 必须是一个ContentHandler的对象
- - # errorhandler - 如果指定该参数,errorhandler必须是一个SAX ErrorHandler对象
计算图书的价格
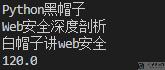
简单介绍了关于SAX的内容之后, 我们使用上面的例子简单做一下测试. 我们希望计算出上面这三本书的总的价格.
完整的代码如下所示. 因为我们希望计算每一本书的价格, 故我们在startElement中, 如果标签是price, 那么我们将is_element=True, 这样在characters的时候, 就可以将价格相加.
- from xml.sax import parse, handler
- class test_parse(handler.ContentHandler):
- """解析xml文件
- """
- def __init__(self):
- self.total_price = 0
- self.is_element = False
- def startElement(self, name, attrs):
- if name == 'price':
- print(attrs['bookName'])
- self.is_element = True
- def characters(self, content):
- if self.is_element:
- self.total_price = self.total_price + float(content)
- self.is_element = False
- def endDocument(self):
- """读取完整个xml文件后会触发
- """
- print(self.total_price)
- if __name__ == "__main__":
- testParse = test_parse()
- parse('./test.xml', testParse)
需要注意的是, 我们可以在startElement中的attrs获得标签内部的属性, 例如在上面例子中我们在price中定义的bookName这个属性.
上面运行的结果如下所示:
ElementTree解析XML文件
上面介绍的SAX其实在使用的时候不是很方便, 特别是当我们要对xml文件进行修改的时候. 所以这里我们介绍使用ElementTree来解析XML文件.
首先介绍一下每一个Element对象的属性:
- tag:string对象,表示数据代表的种类
- attrib:dictionary对象,表示附有的属性
- text:string对象,表示element的内容
- tail:string对象,表示element闭合之后的尾迹
- 若干子元素(child elements)
遍历 xml 文件-getroot
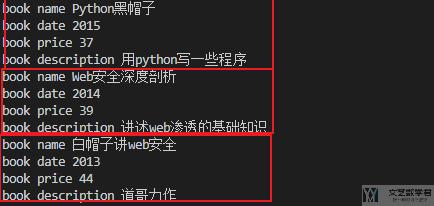
我们首先对xml文件进行简单的遍历.
- from xml.etree import ElementTree as ET
- if __name__ == "__main__":
- tree = ET.parse("./test.xml")
- root = tree.getroot()
- for children in root:
- for child in children:
- print(children.tag, child.tag, child.text)
遍历的结果如下所示, 上面的xml文件一共是三本书, 这里会逐个打印出每一个element的内容.
遍历 xml 文件-tree.getiterator
除了上面的遍历xml文件的方法之外, 我们还可以使用tree.getiterator来进行xml文件的遍历. 下面也是一个简单的例子说明:
- from xml.etree import ElementTree as ET
- if __name__ == "__main__":
- tree = ET.parse("./test.xml")
- for children in tree.iter():
- print(children.tag, children.text)
关于 find 的使用
有的时候我们需要访问特定的 tag 标签,这个时候可以使用 find 函数。这里用到Element类的几个函数,分别是
- Element.findall(),只查找直接的孩子,返回所有符合要求的Tag的Element;
- Element.find(),只返回符合要求的第一个Element;
还是使用上面的 xml 文件,我们找出每一本书的名字:
- from xml.etree import ElementTree as ET
- from xml.dom import minidom
- if __name__ == "__main__":
- tree = ET.parse("./test.xml")
- root = tree.getroot()
- for children in root.findall('book'):
- name_tag = children.find('name')
- print(name_tag.text)
- """
- Python黑帽子
- Web安全深度剖析
- 白帽子讲web安全
- """
当然上面 for 循环,不使用 findall 也是可以的,可以直接使用 for children in root:。
计算图书的总的价格
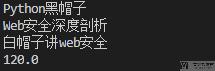
有了上面的遍历之后, 我们就可以很方便的计算这里图书的总的价格了.
- from xml.etree import ElementTree as ET
- if __name__ == "__main__":
- tree = ET.parse("./test.xml")
- total_price = 0
- for children in tree.iter():
- if children.tag == 'price':
- print(children.attrib['bookName'])
- total_price = total_price + float(children.text)
- print(total_price)
最后计算出来的结果也是120, 和上面的计算结果是一样的.
完成对 XML 文件的修改
有的时候我们需要对 xml 文件进行修改, 这个例子我们将这里书的价格都修改为20. 整体的思路是, 将 xml 文件读取, 然后修改 price, 最后再进行保存即可.
- from xml.etree import ElementTree as ET
- if __name__ == "__main__":
- tree = ET.parse("./test.xml")
- for children in tree.iter():
- if children.tag == 'price':
- children.text = str(20)
- tree.write('./test.xml', encoding='UTF-8')
这里我们将修改后的tree, 直接write到原始的文件, 这样所有的价格都会变为20了.
增加 xml 的内容并进行保存
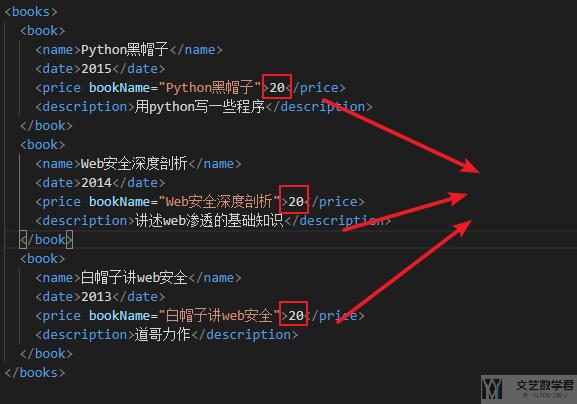
有的时候我们希望可以在原始的 xml 文件中增加一行,并将新的 xml 文件进行保存。例如下面的 xml 文件,我们希望可以在第 2 个 book 的位置,在 description 的位置下面加一个 tag,这个时候可以使用 append 来进行添加。
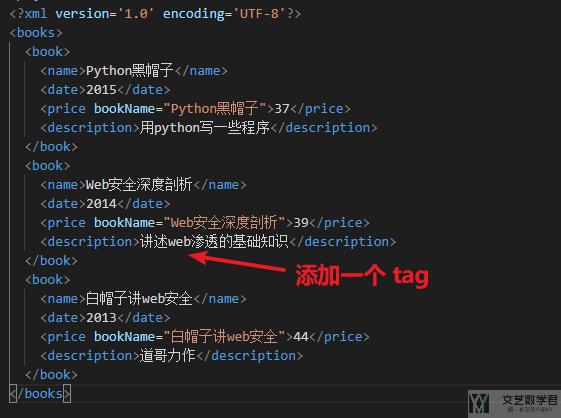
我们可以使用下面的代码来完成新的 xml 文件的生成:
- from xml.etree import ElementTree as ET
- from xml.dom import minidom
- if __name__ == "__main__":
- tree = ET.parse("./test.xml")
- root = tree.getroot()
- for children in root:
- for child in children:
- if child.text == 'Web安全深度剖析':
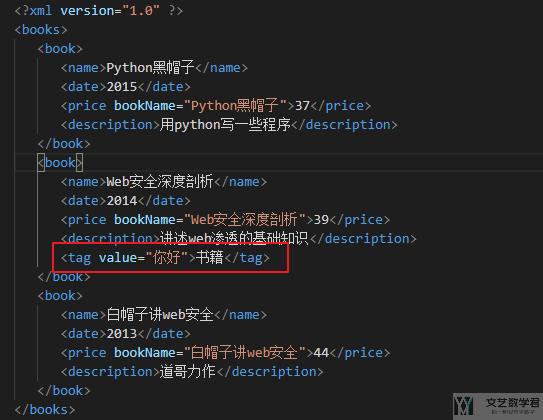
- children.append(ET.fromstring("<tag value='你好'>书籍</tag>"))
- break
- # 美化 xml 文件, 并进行保存
- xmlstr = minidom.parseString(ET.tostring(root)).toprettyxml(indent=" ")
- xmlstr = '\n'.join([line for line in xmlstr.split('\n') if line.strip()]) # 去掉换行
- with open('./test1.xml', "w", encoding='utf-8') as f:
- f.write(xmlstr)
最终生成的新的 xml 文件中已经添加了新的一行,如下所示:
构造一个新的 xml 文件
上面我们都是基于一个 xml 文件来进行修改,现在我们想要从头来生成一个 xml 文件。我们的目标是生成下面的文件:
- <routes>
- <vehicle depart="1" id="2" departLane="random">
- <route edges="1 2 3"/>
- </vehicle>
- </routes>
首先我们定义根节点,也就是上面的 routes:
- from xml.etree import ElementTree
- from xml.dom import minidom
- route_root = ElementTree.Element('routes') # 根节点
接着定义 routes 里面的 vehicle,同时设置属性。可以像下面这样,使用 set 来设置属性:
- vehicle_element = ElementTree.SubElement(route_root, 'vehicle')
- vehicle_element.set('depart', '1')
- vehicle_element.set('id', '2')
- vehicle_element.set('departLane', 'random')
接着我们定义 vehicle 里面的 route,使用另外一种方式定义属性:
- route_element = ElementTree.SubElement(vehicle_element, 'route', {'edges': '1 2 3'})
到这里就完成了 xml 的生成。我们使用 ElementTree.dump 查看此时的 route_root 的结果:

如果我们想要将上面的内容写在文件中,可以再加上下面的代码:
- xmlstr = minidom.parseString(ElementTree.tostring(route_root)).toprettyxml(indent=" ")
- xmlstr = '\n'.join([line for line in xmlstr.split('\n') if line.strip()]) # 去掉换行
- with open('/mnt/d/test.xml', "w", encoding='utf-8') as f:
- f.write(xmlstr)
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论