文章目录(Table of Contents)
简介
【需要看】参考一下这个 Github 的仓库,Show how to structure a Python project.
所以,这一部分包含三个部分,分别是:
- Python 风格指南;
- Python 项目文件结构;
- 中文排版指南(指北)
Python 风格指南
这一部分参考自, Google开源项目风格指南-Python 风格指南,主要分为两个部分:
- Python 语言规范;
- Python 风格规范;
还有一些内容来自于下面的链接:
模块的导入
使用 import 语句的特殊形式 from modu import 模拟更标准的行为。但 import 通常被认为是不好的做法。
- 使用
from modu import *的代码较难阅读而且依赖独立性不足。 - 使用
from modu import func能精确定位您想导入的方法并将其放到全局命名空间中。比from modu import *要好些,因为它明确地指明往全局命名空间中导入了什么方法。
下面是三种导入模块的方法的比较:
- 差
- [...]
- from modu import *
- [...]
- x = sqrt(4) # sqrt是模块modu的一部分么?或是内建函数么?上文定义了么?
- 稍好
- from modu import sqrt
- [...]
- x = sqrt(4) # 如果在import语句与这条语句之间,sqrt没有被重复定义,它也许是模块modu的一部分。
- 最好的做法
- import modu
- [...]
- x = modu.sqrt(4) # sqrt显然是属于模块modu的。
除了简单的单文件项目外,其他项目需要能够明确指出类和方法的出处,例如使用 modu.func 语句,这将显著提升代码的可读性和易理解性。
Python 包管理
Python提供非常简单的包管理系统,即简单地将模块管理机制扩展到一个目录上(目录扩展为包)。
任意包含 init.py 文件的目录都被认为是一个Python包。导入一个包里不同模块的方式和普通的导入模块方式相似,特别的地方是 init.py 文件将集合所有包范围内的定义。
pack/ 目录下的 modu.py 文件通过 import pack.modu 语句导入。 该语句会在 pack 目录下寻找 init.py 文件,并执行其中所有顶层语句。以上操作之后,modu.py 内定义的所有变量、方法和类在pack.modu命名空 间中均可看到。
一个常见的问题是往 init.py 中加了过多代码,随着项目的复杂度增长, 目录结构越来越深,子包和更深嵌套的子包可能会出现。在这种情况下,导入多层嵌套 的子包中的某个部件需要执行所有通过路径里碰到的 init.py 文件。如果包内的模块和子包没有代码共享的需求,使用空白的 init.py 文件是正常甚至好的做法。
最后,导入深层嵌套的包可用这个方便的语法:import very.deep.module as mod。 该语法允许使用 mod 替代冗长的 very.deep.module。
动态类型
Python是动态类型语言,这意味着变量并没有固定的类型。实际上,Python 中的变量和其他语言有很大的不同,特别是静态类型语言。变量并不是计算机内存中被写入的某个值,它们只是指向内存的「标签」或「名称」。
因此可能存在下面这样的情况,变量 'a' 先代表值1,然后变成字符串 'a string' , 然后又变为指向一个函数。这样是不好的。避免对不同类型的对象使用同一个变量名。
- a = 1
- a = 'a string'
- def a():
- pass # 实现代码
我们可以将上面的代码改成下面的方式来进行书写:
- count = 1
- msg = 'a string'
- def func():
- pass # 实现代码
可变类型与不可变类型
Python提供两种内置或用户定义的类型。可变类型允许内容的内部修改。典型的动态类型包括列表与字典。不可变类型没有修改自身内容的方法。比如,赋值为整数 6 的变量 x 并没有 『自增』 方法,如果需要计算 x + 1,必须创建另一个整数变量并给其命名。
- my_list = [1, 2, 3]
- my_list[0] = 4
- print my_list # [4, 2, 3] <- 原列表改变了
- x = 6
- x = x + 1 # x 变量是一个新的变量
这种差异导致的一个后果就是,可变类型是不『稳定』的,因而不能作为字典的键使用。 我们可以使用元组来作为字典的键来进行使用。
同时,在 Python 中,字符串是不可变类型。这意味着当需要组合一个字符串时,将每一部分放到一个可变列表里,使用字符串时再组合 ('join') 起来的做法更高效。 值得注意的是,使用列表推导的构造方式比在循环中调用 append() 来构造列表更好也更快。下面来看一下 Python 中字符串组合的例子。
- 差,每次创建一个新的变量。
- # 创建将0到19连接起来的字符串 (例 "012..1819")
- nums = ""
- for n in range(20):
- nums += str(n) # 慢且低效
- print nums
- 好,将字符串首先保存到可变类型列表里,接着使用
join进行合并。
- # 创建将0到19连接起来的字符串 (例 "012..1819")
- nums = []
- for n in range(20):
- nums.append(str(n))
- print "".join(nums) # 更高效
- 更好,使用列表表达式。
- # 创建将0到19连接起来的字符串 (例 "012..1819")
- nums = [str(n) for n in range(20)]
- print "".join(nums)
- 最好,best。
- # 创建将0到19连接起来的字符串 (例 "012..1819")
- nums = map(lambda x:str(x), range(20))
- print "".join(nums)
另外,在合并一些字符串的时候,我们可以使用 format 来进行合并。
- foo = 'foo'
- bar = 'bar'
- foobar = '{0}{1}'.format(foo, bar) # 好
- foobar = '{foo}{bar}'.format(foo=foo, bar=bar) # 最好
Python 项目文件结构
参考资料
- Python目录结构建议,下面的文件结构在这个基础上进行修改。
- Guide to Python, 结构化您的工程,也有一些内容来源于此。
Python 推荐项目文件结构
下面是一个比较推荐的 Python 项目的文件结构。
- ├── README.md
- ├── requirements.txt
- ├── docs
- ├── project
- │ ├── __init__.py
- │ ├── __main__.py
- │ ├── moduleA
- │ │ ├── __init__.py
- │ │ └── packageA.py
- │ └── moduleB
- │ └── __init__.py
- ├── setup.py
- └── tests
- └── moduleA
- └── test_packageA.py
添加搜索目录
有的时候,当我们自定义了多个 module 之后,我们需要添加搜索目录,来方便我们导入各个
module。按下面方式在主文件的最前面加上即可。
- import os
- import sys
- filePath = os.path.dirname(os.path.abspath(__file__)) # 获取当前的路径
- rootPath = os.path.abspath(os.path.join(filePath, "..")) # 获取上级路径
- sys.path.append(filePath)
- sys.path.append(rootPath)
Python 的 -m 参数
在运行 Python 脚本的时候,我们可以使用到参数 -m,他的含义是「将库中的python模块用作脚本去运行」。一个最常见的例子就是 python 启动 http 服务器:
- python -m http.server # python3中启动一个简单的http服务器
那么使用 -m 参数和不使用这个参数会有什么区别呢,也就是下面两种运行 python 文件的方式会有什么区别呢:
- python xxx.py
- python -m xxx.py
他们的区别在于不同,会影响 sys.path 这个属性,也就是 PATH 内包含的路径。下面我们做一个简单的实验。现在我们的目录结构如下所示:
- # 目录结构如下
- awesome_project
- ├─ __init__.py
- ├─ test.py
- ├─ some
- │ │─ __init__.py
- │ │─ addFunction.py
我们这个 module 叫做 awesome_project, 里面有一个子模块叫做 some。里面我们把需要的函数写在了 addFunction.py 这个文件里面。addFunction.py 中的内容如下所示:
- import sys
- class add_number(object):
- """这是一个加法运算
- """
- def __init__(self, a: int, b: int) -> None:
- self.a = a
- self.b = b
- def add_n(self) -> int:
- c = self.a + self.b
- return c
- def path_print():
- print(sys.path)
在 awesome_project 目录下的 test.py 文件内容如下所示:
- import sys
- print(sys.path)
我们在 awesome_project 目录外面运行 test.py 这个脚本。使用下面两种方式分别进行测试:
- python .\awesome_project\test.py
- >> 'D:/A_Project/awesome_project'
- python -m awesome_project.test
- >> 'D:/A_Project'
可以看到:
- 直接运行 test.py 这个脚本,会把『该脚本所在的目录』放在 sys.path 属性中;
- 使用 -m 的方式运行,会把『当前路径』放在 sys.path 属性中;
于是,在实际的场景中,当我们把 awesome_project 当成一个库的时候(看下面示例代码中,都是从 awesome_project 中导入函数),当 test.py 内的内容为:
- import awesome_project.some.addFunction
- awesome_project.some.addFunction.path_print()
可以使用 -m 来进行调试。若这个时候直接运行 py 文件,就会出现 ModuleNotFoundError 的报错:
- python -m awesome_project.test
这一部分参考资料为,[python]自问自答:python -m参数?
Python 项目测试
编写测试不仅仅是为了发现 Bug,更是为了在未来重构或添加新功能时,给你提供“不会搞崩现有功能”的信心。一个没有测试的大型 Python 项目,就像是在没有安全绳的高空走钢丝。
这部分介绍 Python 测试的主流工具、目录结构规范,并结合 pytest 和 unittest.mock 进行实例演示。现代 Python 开发规范中,pytest 是事实上的行业标准。
测试目录结构规范
测试代码应与业务代码分离,但结构应保持镜像对应。这有助于快速定位模块对应的测试文件。
- my_project/
- ├── src/
- │ ├── services/
- │ │ ├── __init__.py
- │ │ └── payment.py <-- 业务代码
- │ └── utils.py
- ├── tests/ <-- 测试根目录
- │ ├── services/ <-- 对应 src/services
- │ │ ├── __init__.py
- │ │ └── test_payment.py <-- 对应 payment.py
- │ └── test_utils.py
- ├── pyproject.toml
- └── README.md
命名规范:
- 测试文件必须以
test_开头(例如test_payment.py)。 - 测试函数必须以
test_开头(例如def test_success():)。
纯函数测试
假设我们在 src/utils.py 中有一个除法函数:
- # src/utils.py
- def distinct_divide(a: float, b: float) -> float:
- """执行除法,如果分母为0则抛出特定异常"""
- if b == 0:
- raise ValueError("Divider cannot be zero")
- return a / b
对应的测试代码 (tests/test_utils.py):
- import pytest
- from src.utils import distinct_divide
- # 1. 测试正常情况 (Happy Path)
- def test_distinct_divide_success():
- result = distinct_divide(10, 2)
- assert result == 5.0
- # 2. 测试边界情况/异常 (Edge Case)
- def test_distinct_divide_by_zero():
- # 使用 pytest.raises 上下文管理器来捕获预期的异常
- with pytest.raises(ValueError) as exc_info:
- distinct_divide(10, 0)
- # 可选:验证异常信息是否正确
- assert "Divider cannot be zero" in str(exc_info.value)
测试是 Python 工程化中不可或缺的一环。一个遵循规范的测试体系应具备以下特征:
- 工具统一:使用 pytest 作为主要运行器。
- 结构清晰:tests/ 目录结构镜像于源代码目录。
- 独立性:单元测试不依赖网络和数据库,使用 Mock 隔离外部环境。
- 可度量:通过覆盖率报告来监控测试质量。
中文文案排版指北
这一部分参考自, Github-中文文案排版指北。在这里主要记录一些关键点。
中英文之间需要增加空格
正確:
在 LeanCloud 上,數據存儲是圍繞 AVObject 進行的。
錯誤:
在LeanCloud上,數據存儲是圍繞AVObject進行的。
中文与数字之间需要增加空格
正確:
今天出去買菜花了 5000 元。
錯誤:
今天出去買菜花了 5000元。
全角标点与其他字符之间不加空格
下面的句子中,逗号(这里逗号是全角字符)和后面的内容之间不需要增加空格。
正確:
剛剛買了一部 iPhone,好開心!
錯誤:
剛剛買了一部 iPhone ,好開心!
关于全角和半角字符的解释:全角和半角是文字的两种显示形式,“全角”指文字字身长宽比为一比一的正方形,而“半角”为宽度为全角一半的文字。
遇到完整的英文整句, 使用半形
正確:
賈伯斯那句話是怎麼說的?「Stay hungry, stay foolish.」
推薦你閱讀《Hackers & Painters: Big Ideas from the Computer Age》,非常的有趣。
錯誤:
賈伯斯那句話是怎麼說的?「Stay hungry,stay foolish。」
推薦你閱讀《Hackers&Painters:Big Ideas from the Computer Age》,非常的有趣。
关于引号的用法
下面两种引号的使用都是可以的:
用法:
「老師,『有條不紊』的『紊』是什麼意思?」
對比用法:
“老師,‘有條不紊’的‘紊’是什麼意思?”
关于如何打出这两个方引号,可以按照下面的步骤进行设置:
首先打开Windows自带的输入法的设置,点击词库和自学习:
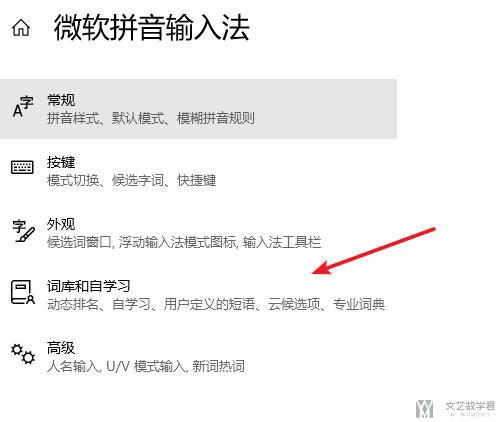
进入词库和自学习之后,点击『添加或编辑自定义短语』
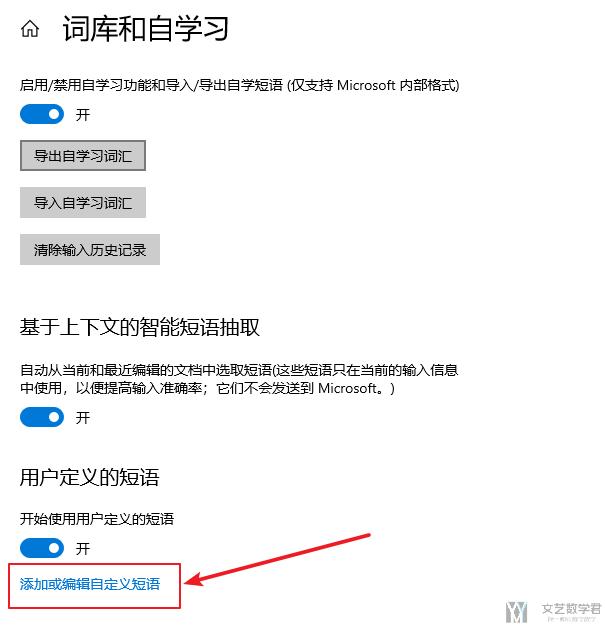
之后按照下面的方式,自行进行添加即可:

最后输入的时候,在输入法中输入 yh, 即可出现备选的选项了。

- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论