文章目录(Table of Contents)
简介
JSON (JavaScript Object Notation) 是一种轻量级的数据交换格式。它基于 ECMAScript 的一个子集。 JSON采用完全独立于语言的文本格式,但是也使用了类似于 C 语言家族的习惯(包括C、C++、Java、JavaScript、Perl、Python等)。这些特性使 JSON 成为理想的数据交换语言。易于人阅读和编写,同时也易于机器解析和生成(一般用于提升网络传输速率)。
在 Python 中提供了一个处理 Json 的模块,里面有四个功能,dumps、dump、loads、load。
- Json dumps:将 Python 中的字典转换为字符串;
- Json dump:将 Python 中的 字典类型存储为 json 文件;
- Json loads:将 Python 中的字符串转换为字典类型;
- Json load:将 json 文件转换为字典类型;
下面介绍一下上面的四个功能。
Json 模块使用介绍
Json dumps 的使用
可以将 Python 中的的 dict 类型转换为 str 类型
- import json
- test_dict = {'bigberg': [
- 7600, {1: [['iPhone', 6300], ['Bike', 800], ['shirt', 300]]}]}
- # 将 dict 转换为 str
- json_str = json.dumps(test_dict)
- print(type(json_str))
- """
- <class 'str'>
- """
Json dump 的使用
dump 可以将 Python 数据写入 Json 文件。
- import json
- test_dicts = {
- 'bigberg': [7600, {1: [['iPhone', 6300], ['Bike', 800], ['shirt', 300]]}],
- 'small': [7600, {1: [['iPhone12', 7300], ['Bike', 800], ['shirt', 300]]}]
- }
- # 将 dict 转换为 str
- with open("./record.json", "w") as f:
- json.dump(test_dicts, f)
最终导出的结果如下所示,可以看到所有的结果都在一行之中,这样不是很美观:

dump 可以设置参数 indent,将其设置为 1,可以使得导出的 json 文件的格式更加美观。下面是 indent 这个参数的介绍。
If indent is a non-negative integer, then JSON array elements and object members will be pretty-printed with that indent level. An indent level of 0 will only insert newlines. None is the most compact representation.
下面看一下将 indent 设置为 1 的效果,可以看到此时输出的结果会排列更加美观:
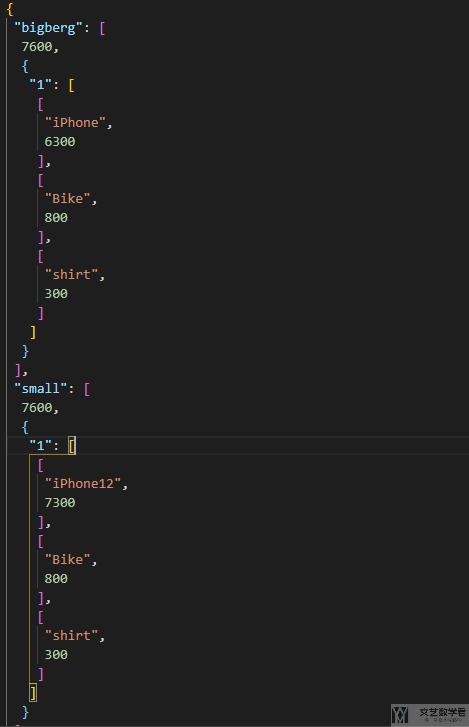
这里 indent 设置的大小表示空格的效果,例如下面是 indent=4 的效果:

如果要是的 dump 的中文可以正常显示,需要设置,ensure_ascii=False 即可。
Json loads 的使用
loads 可以将字符串转换为字典类型。假设我们现在 json 文件的内容如下所示:
- { "page": { "url": "url1", "update_time": "1415387875"}, "other_key": {} }
- { "page": { "url": "url2", "update_time": "1415381963"}, "other_key": {} }
- { "page": { "url": "url3", "update_time": "1415384938"}, "other_key": {} }
我们可以对原始文件每一行进行读取,同时每读一行都使用 json.loads 来转换为字典类型。
- with open("./record.json", "r") as f:
- for line in f:
- line_dict = json.loads(line)
- print(line_dict['page']['url'], type(line_dict))
- """
- url1 <class 'dict'>
- url2 <class 'dict'>
- url3 <class 'dict'>
- """
Json load 的使用
load 可以将 Json 文件转换为字典类型。下面的例子,我们将 dict 首先使用 dump 保存为 json 文件,接着使用 load 来将 json 文件转换为 dict。
- import json
- test_dicts = {
- 'bigberg': [7600, {1: [['iPhone', 6300], ['Bike', 800], ['shirt', 300]]}],
- 'small': [7600, {1: [['iPhone12', 7300], ['Bike', 800], ['shirt', 300]]}]
- }
- # 将 dict 写入文件
- with open("./record.json", "w") as f:
- json.dump(test_dicts, f, indent=1)
- # 读取 json 文件
- with open("./record.json", "r") as json_read:
- load_json = json.load(json_read)
- print(load_json)
- """
- {'bigberg': [7600, {'1': [['iPhone', 6300], ['Bike', 800], ['shirt', 300]]}], 'small': [7600, {'1': [['iPhone12', 7300], ['Bike', 800], ['shirt', 300]]}]}
- """
一些其他需求
对 json 文件中的某个 key 进行排序
有的时候我们需要对 json 文件中的某个 key 进行排序。例如下面的 json 文件,我们希望按照 update_time 来进行排序。
- { "page": { "url": "url1", "update_time": "1415387875"}, "other_key": {} }
- { "page": { "url": "url2", "update_time": "1415381963"}, "other_key": {} }
- { "page": { "url": "url3", "update_time": "1415384938"}, "other_key": {} }
最终希望输出的排序结果如下所示:
- { "page": { "url": "url1", "update_time": "1415387875"}, "other_key": {} }
- { "page": { "url": "url3", "update_time": "1415384938"}, "other_key": {} }
- { "page": { "url": "url2", "update_time": "1415381963"}, "other_key": {} }
下面的方法参考自,python sort list of json by value。我们把上面的所有内容保存在一个 list 中,接着定义一个提取其中 update_time 的函数,然后使用 sort 来进行排序。
- import json
- def extract_time(json):
- try:
- return int(json['page']['update_time'])
- except KeyError:
- return 0
- lines = []
- with open('./record.json', 'r') as f:
- for line in f:
- line_dict = json.loads(line)
- lines.append(line_dict)
- lines.sort(key=extract_time, reverse=True) # 降序进行排序
对于导出的 json 文件中文设置
我们需要设置 ensure_ascii=False 来保证中文可以正常显示,
- with open('filename', 'w', encoding='utf8') as json_file:
- json.dump("你好", json_file, ensure_ascii=False)
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论