文章目录(Table of Contents)
简介
这一篇主要介绍 Python 标准库 subprocess 的使用。subprocess 包主要功能是执行外部的命令和程序。比如说,我需要使用 wget 下载文件。我在 Python 中调用 wget 程序。从这个意义上来说,subprocess 的功能与 shell 类似。
通过使用 subprocess 包,我们可以运行外部程序。这极大的拓展了 Python 的功能。如果你已经了解了操作系统的某些应用,你可以从 Python 中直接调用该应用 (而不是完全依赖 Python ),并将应用的结果输出给 Python,并让 Python 继续处理。(摘自,Python标准库06 子进程 (subprocess包))
参考资料
subprocess 即常见的封装函数
当我们允许 python 程序的时候,我们是创建了一个进程。一个进程可以 fork 一个子进程,这个子进程可以运行另外一个程序。在 python 中,我们可以使用标准库 subprocess 来 fork 一个子进程,并运行外部程序。
在使用 subprocess 创建子进程的时候,有以下几个点需要注意:
- 当创建子进程之后,父进程是否暂停,等待子进程运行;
- 子进程返回是什么;
- 当
return code不是 0 的时候,父进程应该如何处理;
subprocess.call
subprocess.call 是父进程等待子进程完成,同时返回 return code。下面看一个简单的例子。
- import subprocess
- rc = subprocess.call(["dir"], shell=True)
我们使用了 shell=True 这个参数。这个时候,Python 将先运行一个 shell,再用这个 shell 来解释这整个字符串。我们在 windows 下运行一些 exe 的时候,也需要使用 shell=True 的方式来进行运行。
在 Windows 和 Linux 下,使用 shell=True 这个设置得到的效果是不同的。例如运行下面的代码,在 Windows 上可以正确显示:
- import subprocess
- child = subprocess.Popen(["ping",
- "www.baidu.com"],
- stdout=subprocess.PIPE, stderr=subprocess.PIPE, shell=True)
- std_out, err_out = child.communicate()
- child.wait() # 等待子进程完成
- print(std_out.decode('gb2312'), err_out)
但是上面同样的代码,在 Linux 中会出现「ping: usage error: Destination address required」的错误。这是因为设置了 shell=True 之后,在 Linux 中相当于运行了 /bin/sh -c "ping" "baidu.com",而不是我们想要的 /bin/sh -c "ping baidu.com"。此时 ping 没有获得参数 baidu.com。

subprocess.Popen
事实上,上面的 subprocess.call 就是基于 subprocess.Popen 的封装。这些封装的目的在于让我们容易使用子进程。当我们想要更个性化我们的需求的时候,就要转向 Popen 类,该类生成的对象用来代表子进程。
与上面的封装不同,Popen 对象创建后,主程序不会自动等待子进程完成。我们必须调用对象的 wait() 方法,父进程才会等待。可以看下面的例子,
- import subprocess
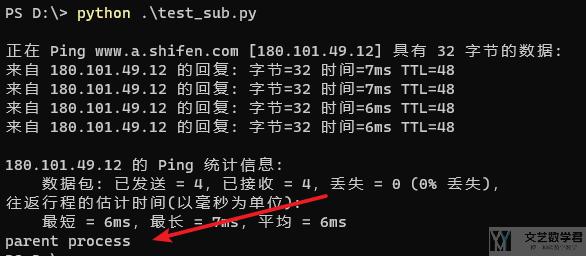
- child = subprocess.Popen(["ping", "www.baidu.com"])
- print("parent process")
父进程在开启子进程之后,没有等待,而是先进行 print 之后,才开始有子进程的信息。

我们需要使用 child.wait() 来是的父进程等待子进程的完成。
- import subprocess
- child = subprocess.Popen(["ping", "www.baidu.com"])
- child.wait()
- print("parent process")
可以看到此时父进程是等子进程运行完毕之后才开始运行的。
子进程的输入和输出异常控制
在使用 Popen 的时候,我们可以分别控制子进程的标准输入和输出,和子进程的异常。这些分别是:
- child.stdin,标准输入
- child.stdout,标准输出
- child.stderr,异常
我们可以在 Popen() 建立子进程的时候改变标准输入、标准输出和标准错误,并可以利用subprocess.PIPE 将多个子进程的输入和输出连接在一起,构成管道 (pipe) :
- import subprocess
- child1 = subprocess.Popen(["ls","-l"], stdout=subprocess.PIPE)
- child2 = subprocess.Popen(["wc"], stdin=child1.stdout,stdout=subprocess.PIPE)
- out = child2.communicate()
- print(out.decode('gb2312'))
在上面的例子中,subprocess.PIPE 实际上为文本流提供一个缓存区。child1 的 stdout 将文本输出到缓存区,随后 child2 的 stdin 从该 PIPE 中将文本读取走。child2 的输出文本也被存放在 PIPE 中,直到 communicate() 方法从 PIPE 中读取出 PIPE 中的文本。
其中,communicate() 是Popen对象的一个方法,该方法会阻塞父进程,直到子进程完成。同时要注意,在 windows 下输出的编码,可能需要使用 decode('gb2312') 来进行解码才可以正常显示。
我们可以借助其来运行一些 windows 下的 exe 的程序,例如下面运行 editcap.exe 来进行流量的分割,可以在其中指定参数,具体的可以参考下面的写法。
- prog = subprocess.Popen(["editcap.exe",
- "-F", "libpcap",
- "-T", "ether",
- '1.pcapng',
- '1.pcap'],
- stdout=subprocess.PIPE, stderr=subprocess.PIPE, shell=True)
- _, _ = prog.communicate()
将子进程输出到临时文件
在 Python 中,调用 subprocess.Popen 的时候,如果调用的 shell 命令本身在执行之后会突然出现很多输出,则这个时候可能会导致 hang 在那里,表现就是卡死了,程序也不往下走,也不会报错。
这个原因就是,PIPE 本身可容纳的量比较小,所以程序会卡死,所以一大堆内容输出过来的时候,会导致 PIPE 不足够处理这些内容,因此需要将输出内容定位到其他地方,例如临时文件等。
下面我们尝试将 subprocess.Popen() 的内容重定向到临时文件中。例如下面是不重定向到临时文件的写法:
- import subprocess
- child = subprocess.Popen(["ping", "www.baidu.com",
- "-c", "10"],
- stdout=subprocess.PIPE, stderr=subprocess.PIPE, shell=False)
- std_out, err_out = child.communicate()
- child.wait() # 等待子进程完成
- print(std_out, err_out)
下面我们将输出和 err 都重定向到文件中去,这里就不需要使用 communicate 了:
- import subprocess
- from tempfile import TemporaryFile
- temp_file = TemporaryFile()
- child = subprocess.Popen(["ping", "www.baidu.com",
- "-c", "10"],
- stdout=temp_file, stderr=temp_file, shell=False)
- child.wait() # 等待子进程完成
- temp_file.seek(0)
- print(temp_file.readlines())
- # 关闭文件的同时删除文件
- temp_file.close()
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论