文章目录(Table of Contents)
前言
这个系列一直以来就是用作记录,方便自己之后查找的,所以为了更加方便,我在github上建了一个仓库用来存放一些数据分析使用的代码。
今天这一篇文章就讲一下大概的使用方法,具体的可以去下载源文件进行查看。
简单示例
我们首先导入要使用的模块
- # 这里选择聚类的方法.
- from pyclustering.cluster.birch import birch;
- # 这里选择k-means聚类方法,具体的介绍查看 https://codedocs.xyz/annoviko/pyclustering/
- from pyclustering.cluster.kmeans import kmeans
- # 这里选择聚类的案例数据
- from pyclustering.utils import read_sample;
- from pyclustering.samples.definitions import FCPS_SAMPLES;
- # 可视化
- from pyclustering.cluster import cluster_visualizer
接着我们导入测试的数据集,并查看一下数据样例:
- # 导入数据集
- sample = read_sample(FCPS_SAMPLES.SAMPLE_LSUN);
- # 查看部分数据集
- sample[0:3]
- >>[[2.0, 3.0], [0.387577, 0.268546], [0.17678, 0.582963]]
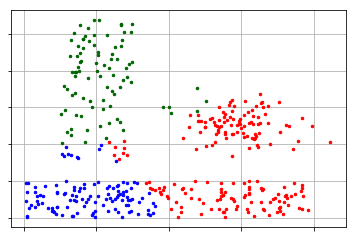
接下来我们开始进行聚类,使用birch算法进行聚类,一共聚成三类
- # 使用birch算法,聚成三类,这里将类实例化,变成对象
- birch_instance = birch(sample, 3);
- # 使用对象里的方法,开始聚类
- birch_instance.process();
- # 获取聚类结果
- clusters = birch_instance.get_clusters();
- # 查看形状,可以看到长度为3,被分为三类
- len(clusters)
- >> 3
最后进行可视化,查看聚类的效果
- # 进行可视化
- visualizer = cluster_visualizer();
- visualizer.append_clusters(clusters, sample);
- visualizer.show();
结语
关于更加详细的信息,可以直接查看源代码,我也觉得直接看源代码会更加清楚一些。
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论