文章目录(Table of Contents)
前言
这一篇我们讲一下布隆过滤器,并给出Python实现的代码。
一句话说明布隆过滤器的作用就是判断一个元素是否在一个集合中,通常这个集合会很大。下面引用一下我参考文章里的一段话:
比如说,一个象 Yahoo,Hotmail 和 Gmai 那样的公众电子邮件(email)提供商,总是需要过滤来自发送垃圾邮件的人(spamer)的垃圾邮件。一个办法就是记录下那些发垃圾邮件的 email 地址。由于那些发送者不停地在注册新的地址,全世界少说也有几十亿个发垃圾邮件的地址,将他们都存起来则需要大量的网络服务器。如果用哈希表,每存储一亿 个 email 地址, 就需要 1.6GB 的内存(用哈希表实现的具体办法是将每一个 email 地址对应成一个八字节的信息指纹, 然后将这些信息指纹存入哈希表,由于哈希表的存储效率一般只有 50%,因此一个 email 地址需要占用十六个字节。一亿个地址大约要 1.6GB, 即十六亿字节的内存)。因此存贮几十亿个邮件地址可能需要上百 GB 的内存。除非是超级计算机,一般服务器是无法存储的。
这个时候我们就需要介绍布隆过滤器了(布隆过滤器的原理很简单,大家就看后面的参考文章里讲的,下面就把代码贴出一下,大家可以结合代码来看)。
代码及运行结果
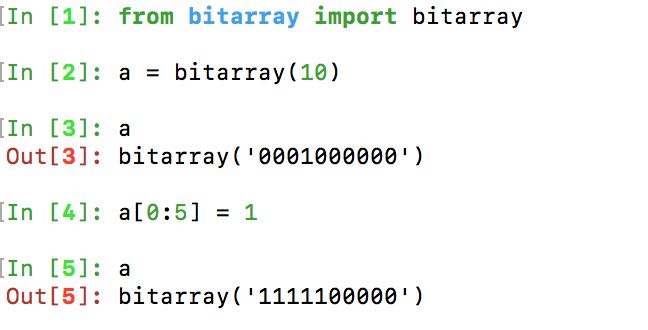
看代码之前首先看一下一个python库bitarray的用法,他可以让你像操作数组一样操作bitarray,具体的可以看下面的这张图:
接下来就是看一下完整的代码实现,代码中都包含了注释了,大家复制到本地自己看一下,运行一下。
- import mmh3
- from bitarray import bitarray
- # Implement a simple bloom filter with murmurhash algorithm.
- # Bloom filter is used to check wether an element exists in a collection, and it has a good performance in big data situation.
- # It may has positive rate depend on hash functions and elements count.
- class BloomFilter(object):
- def __init__(self,BIT_SIZE):
- # 初始化布隆过滤器,生成一下全0的 bitarray
- bit_array = bitarray(BIT_SIZE)
- bit_array.setall(0)
- self.bit_array = bit_array
- def add(self, url):
- # 添加一个url,同时获取这个url的对应的bitarray的位置
- point_list = self.get_postions(url)
- for b in point_list:
- self.bit_array[b] = 1
- def contains(self, url):
- # 验证这个url是否存在在集合中
- point_list = self.get_postions(url)
- result = True
- for b in point_list:
- result = result and self.bit_array[b]
- return result
- def get_postions(self, url):
- # 一个url获取七个位置,之后会把这七个位置变为1
- point1 = mmh3.hash(url, 41) % BIT_SIZE
- point2 = mmh3.hash(url, 42) % BIT_SIZE
- point3 = mmh3.hash(url, 43) % BIT_SIZE
- point4 = mmh3.hash(url, 44) % BIT_SIZE
- point5 = mmh3.hash(url, 45) % BIT_SIZE
- point6 = mmh3.hash(url, 46) % BIT_SIZE
- point7 = mmh3.hash(url, 47) % BIT_SIZE
- return [point1, point2, point3, point4, point5, point6, point7]
- if __name__ == '__main__':
- BIT_SIZE = 5000000
- # 类的实例化
- bloom_filter = BloomFilter(BIT_SIZE)
- urls = ['www.baidu.com','mathpretty.com','sina.com']
- urls_check = ['mathpretty.com','zhihu.com']
- for url in urls:
- bloom_filter.add(url)
- for url_check in urls_check:
- result = bloom_filter.contains(url_check)
- print('被检测的网址 : ',url_check,'/ 是否被包含在原集合中 : ',result)
稍微解释一下上面最后测试的代码,我们假设我们原始集合包含三个url,可以看urls这个list,分别是,www.baidu.com,mathpretty.com,sina.com,我们的测试集合为两个网址,分别是mathpretty.com和zhihu.com,我们判断这两个网址是否在原始集合中,最后的输出入下图所示:

可以看到成功检测出来了,mathpretty.com是在原始集合中的,zhihu.com不在原始集合中的。
参考文章
这里讲一下参考文章和自己的一些感受吧。首先讲一下参考文章,参考文章如下:
布隆过滤器(Bloom Filter)详解:这一篇里面会有布隆过滤器的原理的讲解,会有为什么布隆过滤器需要多个hash函数,会有False positives的概率推导以及最佳数组长度和最佳hash函数个数的确定。
最后说一下感受吧,之前看别人写的博客,看到一篇别人92年写的,真的是感觉现在也是这样,不管是书还是网上的教程,都是一个抄一个,而且还没原来写的好,格式还给调乱了,现在能获取信息的渠道这么多,还是要多做筛选的,下面是截图。

- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论