文章目录(Table of Contents)
介绍
这一篇会系统介绍一些关于编码的知识。之前写爬虫的时候经常会遇到编码问题,每次都去查太麻烦了,故在这里进总结。
在线编码转换工具
站长之家-编码解码:可以在这里尝试一些编码与解码
Python类型转换
下面是一些常用的类型转换的函数:
- int(x [,base ]) 将x转换为一个整数
- str(x ) 将对象 x 转换为字符串
- repr(x ) 将对象 x 转换为表达式字符串
- eval(str ) 用来计算在字符串中的有效Python表达式,并返回一个对象
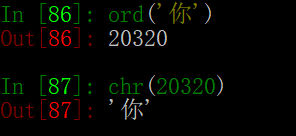
- chr(x ) 将一个整数转换为一个字符
- ord(x ) 将一个字符转换为它的整数值
- hex(x ) 将一个整数转换为一个十六进制字符串
- oct(x ) 将一个整数转换为一个八进制字符串
int的解释
其中int(num,base)可以将base转为十进制,如int(num,2)的意思为将二进制表示的num转换为十进制;
chr与ord的解释
一张图来解释:
str()与repr()的区别
尽管str(),repr()和运算在特性和功能方面都非常相似,事实上repr()和做的是完全一样的事情,它们返回的是一个对象的“官方”字符串表示,也就是说绝大多数情况下可以通过求值运算(使用内建函数eval())重新得到该对象。
但str()则有所不同。str()致力于生成一个对象的可读性好的字符串表示,它的返回结果通常无法用于eval()求值,但很适合用于print语句输出。需要再次提醒的是,并不是所有repr()返回的字符串都能够用 eval()内建函数得到原来的对象。
Python的decode与encode
首先看下图,是在Python3中encode和decode的转换关系:
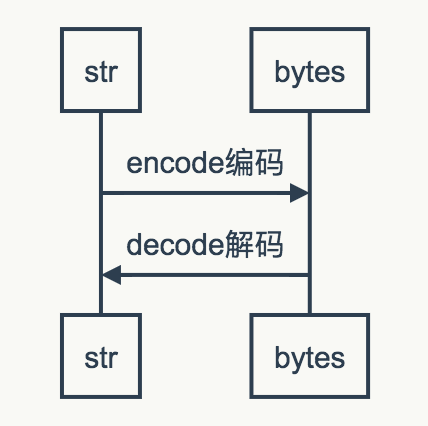
我们看一个例子,就可以了:

参考链接:python3的decode()与encode()
进制转换
十六进制数’\0x’和’\x’有什么区别?
区别不大,都是把数按16进制输出。
- 0x:当输出的数转换为16进制只有1位时,在前面补0,如 0a,其它情况按照实际情况输出。
- \x:按照输出数转换为16进制的实际位数输出。
此外,小写x和大写X也有点区别,小写的x输出小写符号的16进制,大写X则输出大写的(主要针对ABCDEF这六位)
参考链接:https://www.cnblogs.com/SharkBin/p/4043856.html
Unicode
Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码;
如上面汉字“你”的唯一二进制编码为:
100111101100000
转换为十进制就是:
20320
而我们经常见到的下面的形式就是Unicode编码:
\u6587\u827a\u6570\u5b66\u541b
这个就是文字的对应Unicode编码,\u表示Unicode的意思,网上也有用U+表示unicode(上面这段unicode表示的是文艺数学君)。
参考链接:
UTF-8编码方式
有了上面的铺垫,下面我们来讲一下UTF-8编码方式。
上面可以看到unicode把全球各国文字都统一在一个编码标准里,兼容性很好。但是如果使用原始的unicode码,由于英文字符也全部使用双字节,存储成本和流量会大大地增加,所以Unicode编码大多数情况并没有被原始地使用,而是被转换编码成UTF8。下面总结一下性质:
- UTF-8就是在互联网上使用最广的一种unicode的实现方式;
- UTF-8最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度,当字符在ASCII码的范围时,就用一个字节表示,保留了ASCII字符一个字节的编码做为它的一部分,注意的是unicode一个中文字符占2个字节,而UTF-8一个中文字符占3个字节;
- 上面内容参考自:Unicode 和 UTF-8 有什么区别?
Unicode与UTF-8之间的转换关系:
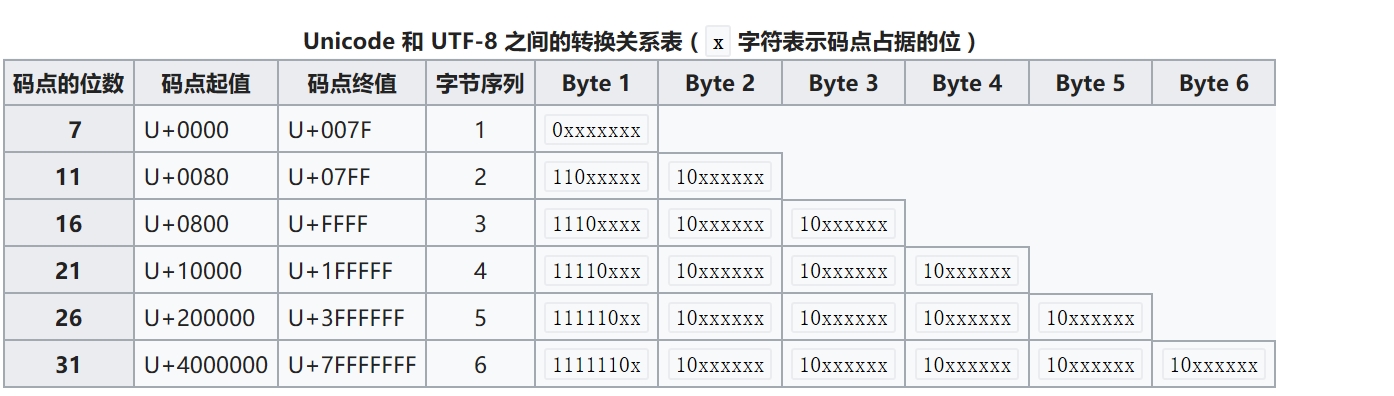
- 在ASCII码的范围,用一个位元组表示,超出ASCII码的范围就用位元组表示,这就形成了我们上面看到的UTF-8的表示方法,这様的好处是当UNICODE文件中只有ASCII码时,储存的文件都为一个位元组,所以就是普通的ASCII文件无异,读取的时候也是如此,所以能与以前的ASCII文件相容。
- 每个使用UTF-8储存的字符,除了第一个字节外,其余字节的头两个位元都是以"10"开始,使文字处理器能够较快地找出每个字符的开始位置;
- 大于ASCII码的,就会由上面的第一位元组的前几位表示该unicode字元的长度,比如110xxxxx前三位的二进位表示告诉我们这是个2BYTE的UNICODE字元;1110xxxx是个三位的UNICODE字元,依此类推;xxx的位置由字符编码数的二进制表示的位填入。越靠右的x具有越少的特殊意义。只用最短的那个足够表达一个字符编码数的多字节串。注意在多字节串中,第一个字节的开头"1"的数目就是整个串中字节的数目;
- 参考资料:https://zh.wikipedia.org/wiki/UTF-8
下面我们来看一个具体的例子,还是看上面的汉字“你”;
Unicode与UTF-8转换示例
我们还是使用汉字“你”来作为例子来看。
首先我们按照上面的表格来看,“你”的二进制编码为 100111101100000 (补到16位为0100111101100000),我们知道一个汉字由3 Byte 表示,于是有下面的表格:

于是“你”的utf-8编码为\xe4\xbd\xa0(这个就是我们爬虫经常看见的表示形式),整个推导过程见上面的表格。
下面用python代码验证一下,我们把三个二进制打印出来,如下面所示:
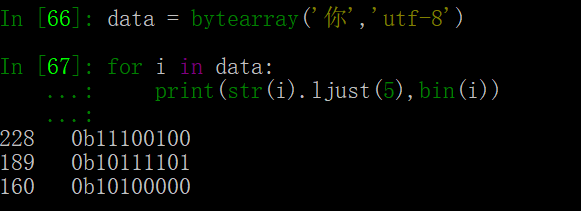
我们按照上面表格里的规则,将上面的二进制取出有意义的位置拼接起来成为Unicode码,把二进制转为十进制,再转为汉字,可以看到就是汉字“你”;
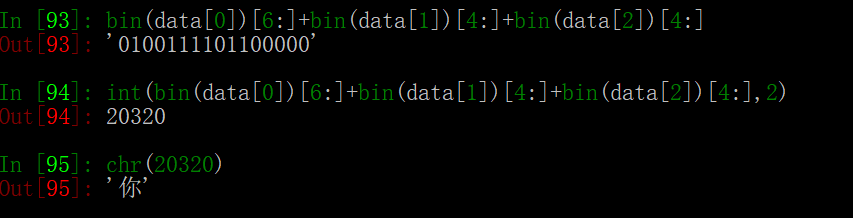
可以看到和上面表格是一样的意思。
关于URL编码
有了上面的铺垫再来将url编码就会方便很多了。
我们经常会看见形如下面的网址:
https://sou.autohome.com.cn/zonghe?q=%B4%F3%D6%DA
关于?q后面的一段内容其实就是我们输入搜索的内容进行转码后的内容,关于使用的编码格式可以通过查看网页源代码查看,比如这里有charset=gb2312,于是我们队上面的进行解码:
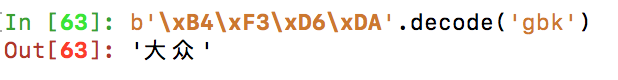
关于url编码解码还可以使用urllib.parse中的quote, unquote, urlencode和来完成。
首先看一下quote和unquote的使用:

有的时候为了构造的方便,我们会使用urlencode来进行编码,我们看下面的例子,我们使用urlencode进行网址的构建。

参考链接:关于URL编码 - 阮一峰
类型转换会出现的问题
下面记录一些自己遇到过的问题,方便以后的查错。
'gb2312' codec can't encode character u'\xb7' in position
解决方法:将gb2312替换为GBK或者GB18030就好了;
原因:GB2312为早期的编码标准。后来的GBK(1995)才补充了大量的汉字进去,所以这里可以改用GBK。
参考链接:https://blog.csdn.net/linking530/article/details/45483147
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论