文章目录(Table of Contents)
简介
最近在看GCN的内容, 里面会用到关于一些网络结构. 在处理数据的时候就会使用到NetworkX这个库, 在这里简单介绍一下相关的内容. 自己也是用到多少就记录多少, 会不断进行补充的.
参考资料
这个是NetworkX的说明文档, NetworkX, Software for Complex Networks
图的一些操作
关于这部分的内容, 可以参考连接, NetworkX, Tutorial
创建一个图
我们首先创建一个空的图, 没有nodes和edges.
- import networkx as nx
- G = nx.Graph()
添加节点与添加边
接着我们向上面的图中添加node和edge. 一般情况下, 我们会首先将所有的node都添加完毕, 之后再添加edge. 添加node有下面两种方法.
我们可以一次只添加一个点.
- G.add_node(1)
也可以一次添加多个点.
- G.add_nodes_from([2, 3])
当然, 我们在添加节点的时候, 可以一起添加节点的属性值.
- G.add_nodes_from([
- (4, {"color": "red"}),
- (5, {"color": "green"}),
- ])
在添加完节点之后, 我们需要添加边. 同样的, 我们可以一条一条边进行添加.
- G.add_edge(1, 2)
我们也可以多条边一起添加, 同时可以加上权重.
- G.add_edges_from([(2, 3, {'weight': 3.1415}), (4, 5), (3, 5)])
顶点和边的信息
对于一个network来说, 我没可以查询他的点的个数和边的个数.
- numNodes = G.number_of_nodes()
- numEdges = G.number_of_edges()
除了列举顶点和边的个数以外, 我们还可以列举出具体的顶点和具体的边的信息.
- list(G.nodes)
- """
- [1, 2, 3, 4, 5]
- """
- list(G.edges)
- """
- [(1, 2), (2, 3), (3, 5), (4, 5)]
- """
判断node与node之间是否有边
有的时候, 我们需要判断两个node之间是否是相连的, 这个时候就需要是要is_path函数. 例如在上面node 2和node 3是相连的, 但是node 2和node 4是不相连的, 我们可以确认一下.
- nx.is_path(G, (2,3))
- # >> True
- nx.is_path(G, (2,4))
- # >> False
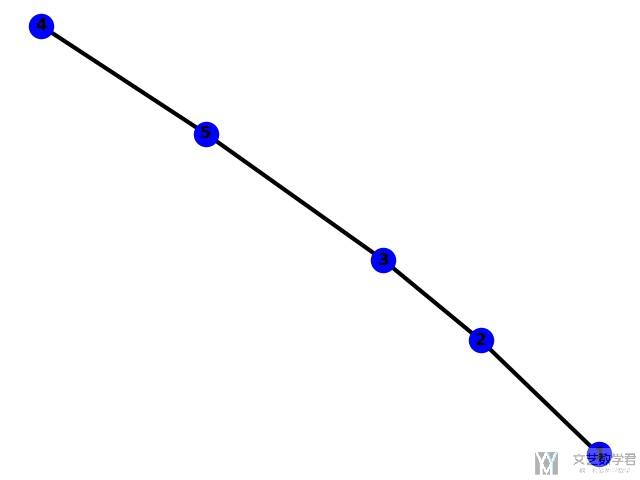
图的可视化
我们可以使用nx.draw来进行网络的可视化. 所有的参数都可以自定义在options中.
- import matplotlib.pyplot as plt
- options = {
- 'with_labels': True,
- 'font_weight': 'bold',
- 'node_color': 'blue',
- 'node_size': 300,
- 'width': 3,
- }
- nx.draw(G, **options)
- plt.show()
最终的结果显示如下图所示:
读取和保存文件
这部分内容可以参考链接, NetworkX, Reading and writing graphs
读取邻接矩阵-Adjacency List
对于edge没有权重的图来说, 可以使用adjacency lists的方式来进行读取. 他读取的格式如下所示:
- a b c # source target target
- d e
其中每一行第一个字母是source node, 后面是target node. 也就是上面的格式表示的图为 a-b, a-c, d-e, 包含三条边. 我们可以通过read_adjlist来进行文件的读取, 如下所示:
- G = nx.read_adjlist("test.adjlist")
参考资料:
NetworkX关于Adjacency List的相关说明, Adjacency List.
保存为Adjacency List
我们可以直接使用write_adjlist来完成相关的操作. 如下所示:
- fh = open("test.adjlist", "wb")
- nx.write_adjlist(G, fh, comments='#@')
此时, 最终的输出结果如下所示:
- #@dataPre.py
- #@ GMT Thu Sep 10 18:41:01 2020
- #@
- 1 2
- 2 3
- 3 5
- 4 5
- 5
这里每一行的含义和上面读取的时候是一样的. 这里最上面是会有一些信息的, 例如运行的时间和文件的名字.
但是如果想要去掉最上面的一些信息, 或是自定义信息的内容, 我们可以重新写一下相关的函数. 例如此时文件开头就是整个图的顶点个数和边的个数.
- def writeAdj(subG, adjPath):
- """写入文件
- """
- fh = open(adjPath, "wb")
- numNodes = subG.number_of_nodes()
- numEdges = subG.number_of_edges()
- # 开始写入
- fh.write(('{} {}\n'.format(numNodes, numEdges)).encode('utf-8'))
- for line in nx.generate_adjlist(subG, " "):
- line += "\n"
- fh.write(line.encode('utf-8'))
此时输出的文件如下, 第一行5表示5个顶点, 4表示有4条边. 第二行开始, 1表示source node, 2表示target node. 此时就是表示node 1和node 2是相连的.
- 5 4
- 1 2
- 2 3
- 3 5
- 4 5
- 5
转换为其他数据类型
与其他数据类型的转换, 可以参考链接: NextworkX converting to and from other data formats
转换为pandas的格式
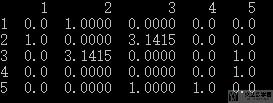
将图的邻接矩阵使用dataframe来进行表示.
- nx.to_pandas_adjacency(G)
最终的输出结果如下所示, 可以看到上面有设置权重是3.1415的边.
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论