文章目录(Table of Contents)
简介
本文会介绍 OpenAI Gym 的使用。在学习强化学习等的过程中,我们需要一些环境来测试算法, OpenAI Gym 就提供了许多经典的决策问题,包括机器人控制、视频游戏和棋盘游戏。
Gym的官方文档说明:Getting Started with Gym- 这一篇所有的示例代码都放在了
GitHub的仓库,Reinforcement Learning 中 Gym 的使用 - 本文的部分内容来自,Practical_RL,Week 01
Gym 初步使用介绍
Gym 的安装
安装没什么好说,直接使用 pip 进行安装即可:
- pip install gym
Gym 初次体验
首先让我们运行一个 Gym 的小例子,看一下整体的流程。我们使用 CartPole-v0 这个环境。注意下面的环境都是来自 env 基类:
- import gym
- env = gym.make('CartPole-v0')
- env.reset()
- for _ in range(1000):
- env.render()
- env.step(env.action_space.sample()) # take a random action
- env.close()
我们简单解释一下上面的代码。首先初始化一个环境,环境进行渲染,采取一个action,这样循环 1000 次。如果你在本地命令行运行,会弹出一个窗口进行模拟,如下所示:
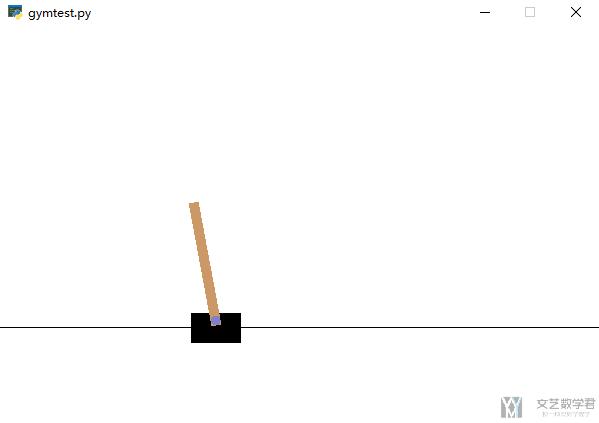
但是如果在 jupyter notebook 或是 google Colaboratory 就无法直接这样使用,我会在后面讲如何在 colab 上运行 gym。
关于 Observation Space 与 Action Space 的说明
在上面的代码中,我们可以看到我们每一次的 action 都是随机进行取值的。事实上,每一个环境都有 action_space和observation_space。(Every environment comes with an action_space and an observation_space) 我们还是用上面的 CartPole-v0 来作为例子.
首先我们来看 action_spaces,这个代表可以采取的 action 的种类,在 CartPole-v0 的例子中, 可以采取的 action 的种类只有两种.
- print(env.action_space)
- >> Discrete(2)
- # 随机选取action
- [env.action_space.sample() for i in range(10)]
- >> [0, 0, 1, 1, 0, 1, 0, 1, 1, 1]

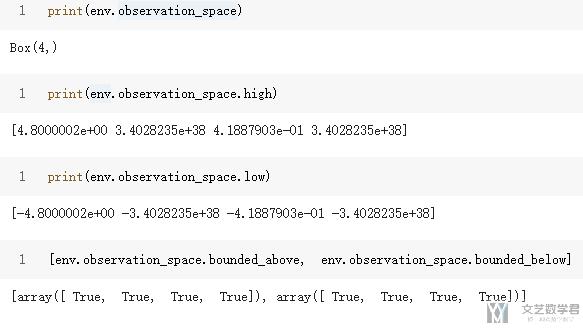
接下来我们查看 observation_space。可以查看这个 space 的 shape,和查看这个 space 的边界。简单的看一下下面的示范:
关于这里的 high 和 low 的理解,就是代表四个边界的上界和下界(能取到的最大值和最小值)。
对于 step 与返回的 obs, reward, done 与 info
上面我们只是每次做随机的 action。在执行 action 之后,环境会返回一些值。每一个 env 类会有以下的三种方法,分别是:
reset(): reset environment to the initial state, _return first observation_render(): show current environment state (a more colorful version)step(a): commit actionaand return(new_observation, reward, is_done, info)new_observation: an observation right after committing the actionareward: a number representing your reward for committing actionais_done: True if the MDP has just finished, False if still in progressinfo: some auxiliary stuff about what just happened. For now, ignore it.
在详细说明以下 step(a),也就是执行动作 a 之后返回的四个值:
observation(object): an environment-specific object representing your observation of the environment. For example, pixel data from a camera, joint angles and joint velocities of a robot, or the board state in a board game. (observation 可以表示代表当前 object 的状态, 例如位置信息, 角度信息等)reward(float): amount of reward achieved by the previous action. The scale varies between environments, but the goal is always to increase your total reward. (reward 采取这一步action 获得的即时奖励)done(boolean): whether it's time toresetthe environment again. Most (but not all) tasks are divided up into well-defined episodes, anddonebeingTrueindicates the episode has terminated. (For example, perhaps the pole tipped too far, or you lost your last life.) (代表这一轮游戏是否结束, 如果done=True, 表示这一类游戏结束了)info(dict): diagnostic information useful for debugging. It can sometimes be useful for learning (for example, it might contain the raw probabilities behind the environment's last state change). However, official evaluations of your agent are not allowed to use this for learning.
讲了这么多可能有点抽象, 还是上面的例子, 我们实际看一下输出就可以理解了.
- import gym
- env = gym.make('CartPole-v0')
- env.reset()
- for _ in range(10):
- env.render()
- observation, reward, done, info = env.step(env.action_space.sample()) # take a random action
- print('observation:{}, reward:{}, done:{}, info:{}'.format(observation, reward, done, info))
- env.close()
下面的每一行,分别有四个值,分别是 (observation, reward, done, info):
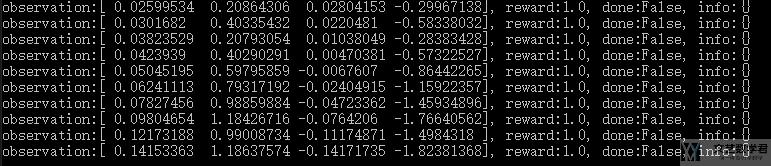
我们再详细看一下 (observation, reward, done, info) 这四个变量的数据类型:
- new_obs, reward, is_done, info = env.step(1) # taking action 1
- print("new observation code:", new_obs, type(new_obs))
- print("reward:", reward, type(reward))
- print("is game over?:", is_done, type(is_done))
- print("info:", info, type(info))
输入的内容如下所示,其中 obs 为 numpy.ndarray,reward 为 float,done 为 bool,info 为 dict:

上面的就是一个经典的 agent-environment 循环。agent 选择一个 action,环境返回一个observation 和 reward。就是如下图所示。(This is just an implementation of the classic "agent-environment loop". Each timestep, the agent chooses an action, and the environment returns an observation and a reward.)
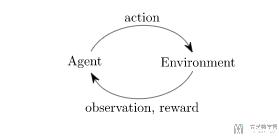
关于 render 的说明
render 其实就相当于一个渲染的引擎,没有 render 也是可以运行的。但是 render 可以为了便于直观显示当前环境中物体的状态,也是为了便于我们进行代码的调试。不然只看着一堆数字的 observation,我们也是不知道实际情况怎么样了。
Gym 进阶使用
Wrappers 的使用
有的时候我们希望对环境的功能进行拓展。例如我们想要对环境返回的 image 进行剪裁和预处理,这个时候原始的环境就无法满足我们的需求。我们可以 wrap 现有的环境,并增加一些功能。Gym 提供了 Wrapper 类来帮助我们实现上面的需求。
Wrapper 类的结构如下图所示。Wrapper 继承了 ENV 类。他接受的唯一参数是要包装的 ENV 的实例。如果想要添加额外的功能,需要自定义 step 或是 reset。
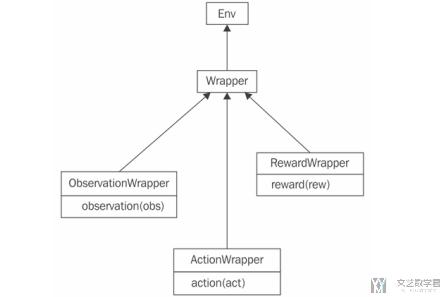
如果我们只想修改 observation,action 或是 reward,在 Wrapper 下面还提供了三个子类,我们可以分别进行修改。例如现在有一个需求,我们有 0.1 的概率不会执行我们下发的 action,而是会从 action space 中随机挑选一个执行。这个时候我们就可以继承 gym.ActionWrapper 来做。
下面的代码中,我们重写了 action 部分。每次会有一个随机数与 epsilon 比较。小于阈值则随机一个动作,否则就是下发的动作:
- class RandomActionWrapper(gym.ActionWrapper):
- def __init__(self, env, epsilon=0.1):
- super(RandomActionWrapper, self).__init__(env)
- self.epsilon = epsilon
- def action(self, action):
- if random.random() < self.epsilon:
- print("Random!")
- return self.env.action_space.sample() # 随机动作
- return action
我们可以传入一个实例化的环境到上面的 wrapper,这个时候我们就会使用我们的 wrapper 作为一个 env 的实例(作为环境)。因为 wrapper 继承自 env,他们有一样的接口,所以使用方式不用改变。
下面的代码中,我们首先实例化一个 CartPole-v0 的环境,接着每次都执行动作 0。但是我们会发现实际运行过程中,action 会有一定的几率随机改变的:
- env = gym.make("CartPole-v0")
- env = RandomActionWrapper(env)
- obs = env.reset()
- total_reward = 0.0
- while True:
- obs, reward, done, _ = env.step(0)
- total_reward += reward
- if done:
- break
- print("Reward got: %.2f" % total_reward)
Monitor 的使用
Monitor 可以将每一个 eposide 的信息记录在文件中,方便我们查看 agent 在环境中的表现变化。Monitor 使用十分简单,只需要加上一行即可:
- env = gym.make("LunarLander-v2")
- env = gym.wrappers.Monitor(env, directory="recording") # 增加一行
这样所有的数据会保存在 recording 文件夹下,包含 json 和 mp4 文件。
环境的状态
当我们注册好了环境之后,我们可以查看当前环境的所有 state 的个数与所有 action 的个数。

同时,environment 还可以返回在当前的 state,采取 action,返回下一个 state 的种类和概率。
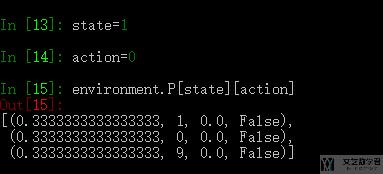
上面返回的四个值是,state_probability,next_state,reward,terminated.
设置从指定状态开始
在使用 gym 的时候, 有的时候我们需要设置从指定的state开始, 这个可以通过参数environment.s来进行设置, 同时我们要注意的是, environment.state存储的是初始状态(这个可以用dir查询一下, 然后自己尝试, 我在Windy_Gridworld的环境是上面说的这样)
下面我们来看一个例子.
- state = environment.reset()
- next_state, _, _, _ = environment.step(1)
- print(next_state, environment.s)
- next_state, _, _, _ = environment.step(1)
- print(next_state, environment.s)
- environment._render()
- # reset到指定state
- environment.s= 30
- next_state, _, _, _ = environment.step(1)
- print(next_state, environment.s)
- environment._render()
结果如下图所示, 可以看到第二幅图的时候, 从我们指定的位置30重新开始了.

环境的注册与删除
有的时候,gym 中自带的默认的属性可能无法满足我们的需求,这个时候我们希望可以有自定义修改一些内容,这个时候就需要对环境进行重新的注册。我们使用 FrozenLake-v0 来作为例子说明一下,FrozenLake-v0。
默认情况下,FrozenLake-v0 是会出现打滑的,也就是is_slippery=True,也就是实际的方向和我们想要的方向不一样。但是我们不希望有打滑,于是就需要自己重新注册一个新的环境。
- from gym.envs.registration import register
我们通过 id 的方式使用自带的环境,并修改参数重新注册,注意这里使用的 id 需要与原来的不相同。
- register(
- id='FrozenLakeNotSlippery-v0',
- entry_point='gym.envs.toy_text:FrozenLakeEnv',
- kwargs={'map_name' : '4x4', 'is_slippery': False},
- max_episode_steps=30,
- reward_threshold=0.78, # optimum = .8196
- )
需要注意的是,相同的 id 是不能重复注册的,否则会出现如下的报错:
- Error: Cannot re-register id: FrozenLakeNotSlippery-v0
所以,当我们需要注册相同的 id 的时候,需要先把之前注册的环境进行删除。我们可以使用下面的命令查看所有已经注册的环境。
- gym.envs.registry.env_specs
对环境进行删除,我们使用 del 即可:
- del gym.envs.registry.env_specs['FrozenLakeNotSlippery-v0']
参考资料:
- 关于如何注册新环境: Setting is_slippery=False in FrozenLake-v0
- 关于删除已经注册的环境: How do you unregister gym environments?
关于 jupyter output 的删除
在我们测试toy text的时候, 每一次render的内容都会保留在output里面, 但这样看上去不是很方便, 于是我们可以使用clear_output的方式对output进行清除. 下面是一个简单的例子.
- from IPython.display import clear_output
- for i in range(10):
- clear_output(wait=True)
- print("Hello World!")
参考资料: ipython notebook clear cell output in code
一个较为完善的例子
有了上面的基础之后, 我们重新修改一开始的CartPole-v0的代码, 我们需要考虑done的状态.
记住, 我们开始的时候需要从reset开始, 他返回一个初始的observation.
- observation = env.reset()
于是, 在一般情况下, 我们会将代码写成如下的样子.
- import gym
- env = gym.make('CartPole-v0')
- for i_episode in range(20):
- observation = env.reset()
- for t in range(100):
- env.render()
- print(observation)
- action = env.action_space.sample()
- observation, reward, done, info = env.step(action)
- if done: # 如果结束, 则退出循环
- print("Episode finished after {} timesteps".format(t+1))
- break
- env.close()
Gym 与 Colab 配合使用
上面讲的都是 Gym 在本地进行使用, 但是在线上的时候, 特别是 Gym 配合 Colab 进行使用的时候, 我们是无法直接使用 render 的, 因为无法弹出窗口. 这个时候就需要找其他的解决方法.
这一部分完整的代码我都会上传 github, 链接地址为: Reinforcement Learning中Gym的使用
安装依赖
首先我们需要安装相应的依赖.
- #remove " > /dev/null 2>&1" to see what is going on under the hood
- !pip install gym pyvirtualdisplay > /dev/null 2>&1
- !apt-get install -y xvfb python-opengl ffmpeg > /dev/null 2>&1
第二组依赖.
- !apt-get update > /dev/null 2>&1
- !apt-get install cmake > /dev/null 2>&1
- !pip install --upgrade setuptools 2>&1
- !pip install ez_setup > /dev/null 2>&1
- !pip install gym[atari] > /dev/null 2>&1
导入相应的库.
- import gym
- from gym import logger as gymlogger
- from gym.wrappers import Monitor
- gymlogger.set_level(40) #error only
- import numpy as np
- import random
- import matplotlib
- import matplotlib.pyplot as plt
- %matplotlib inline
- import math
- import glob
- import io
- import base64
- from IPython.display import HTML
- from IPython import display as ipythondisplay
使用pyvirtualdisplay进行显示.
- from pyvirtualdisplay import Display
- display = Display(visible=0, size=(1400, 900))
- display.start()
使用video recording的方式
这里方法参考自: Rendering OpenAi Gym in Colaboratory
主要的想法就是讲render的过程就存储下来, 最后使用video的方式进行展示. 首先定义一些工具函数.
- """
- Utility functions to enable video recording of gym environment and displaying it
- To enable video, just do "env = wrap_env(env)""
- """
- def show_video():
- mp4list = glob.glob('video/*.mp4')
- if len(mp4list) > 0:
- mp4 = mp4list[0]
- video = io.open(mp4, 'r+b').read()
- encoded = base64.b64encode(video)
- ipythondisplay.display(HTML(data='''<video alt="test" autoplay
- loop controls style="height: 400px;">
- <source src="data:video/mp4;base64,{0}" type="video/mp4" />
- </video>'''.format(encoded.decode('ascii'))))
- else:
- print("Could not find video")
- def wrap_env(env):
- env = Monitor(env, './video', force=True)
- return env
接着就是可视化的例子部分.
- env = wrap_env(gym.make("CartPole-v0"))
- observation = env.reset()
- while True:
- env.render()
- #your agent goes here
- action = env.action_space.sample()
- observation, reward, done, info = env.step(action)
- if done:
- break;
- env.close()
- show_video()
这样就是使得gym在colab中进行显示了.
使用 matplotlib 进行显示
这里我们使用另外一种方式, 我们将每一帧的画面, 使用matplotlib绘制出来, 接着间隔固定时间进行清除, 最后就可以看上去是动态的图像了, 我们还是看一个例子.
就直接参考下面的代码, 我已经写上了详细的注释了, 同样, 可以直接去github上查看代码, 链接地址为: Reinforcement Learning中Gym的使用.
- env = gym.make('CartPole-v0') # 初始化场景
- env.reset() # 初始状态
- env.render(mode='rgb_array')
- t = 0
- # 随便动一步(初始状态)
- action = env.action_space.sample()
- state, _, done, _ = env.step(action)
- env.render(mode='rgb_array')
- # 绘图
- plt.figure()
- plt.clf()
- plt.title('Example extracted screen')
- while True:
- action = env.action_space.sample()
- # 往后走一步
- state, _, done, _ = env.step(action)
- # 生成走后的场景
- current_screen = env.render(mode='rgb_array') # 返回现在的图像, 用于可视化
- # 绘制画面
- plt.pause(0.7) # pause a bit so that plots are updated
- ipythondisplay.clear_output(wait=True)
- ipythondisplay.display(plt.gcf())
- plt.title('Action: {}'.format(action))
- plt.imshow(current_screen, interpolation='none')
- t = t + 1
- if done:
- break
- if t>100:
- break
- plt.show()
- env.close()
- print(t)
最终的效果如下图所示:
Gym 使用的一些问题
Could not find module \ale_c.dl
在使用 atari 环境,例如 MsPacman-v0 的时候,可能会出现如下的报错:
- FileNotFoundError: Could not find module 'XXX\python\lib\site-packages\atari_py\ale_interface\ale_c.dll' (or one of its dependencies). Try using the full path with constructor syntax.
分下面三个步骤来解决问题:
- 第一步:先卸载 atari-py,
pip uninstall atari-py - 第二步:再重新安装 atari,
pip install --no-index -f https://github.com/Kojoley/atari-py/releases atari_py - 第三步:重新安装 gym,
pip install gym
参考资料, windows10安装gym环境后运行atari-py失败,但是atari-py已经安装,运行env=gym.make('MsPacman-v0')失败
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-







评论