文章目录(Table of Contents)
简介
本文会介绍 MADDPG 算法,这是一个集中式训练,分布式执行的算法,是基于 actor-critic 框架的,与之前我们介绍的值分解的算法思路不同。下面是一些关键点的总结:
- 研究点:研究协作或协作竞争混合场景下的 MADRL 算法
- 场景设定:部分可观、完全协作(共用同一奖励)/竞争(目标相互冲突)
- 训练方法:集中训练、分布式执行(基于 actor-critic 的框架,这里每个 agent 会有一个 actor 和 critic network,且每个 agent 都有自己的奖励函数)
参考资料
- Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments,MADDPG 原文;
- 【多智能体强化学习】[learn to cooperate] MADDPG 阅读笔记,知乎笔记,总结的较为简单;
- 多智能体强化学习入门(四)——MADDPG算法,知乎笔记(这一篇笔记更加详细,方法论部分为翻译,可以快速过一遍)
- maddpg_learner.py,在 EPyMARL 里面实现的代码,可以进行参考。
MADDPG 主要想法
目前研究存在的问题
RL 至今的辉煌成就主要集中在单一智能体领域,这些领域内无需太多地模拟或预测其他参与者的行为。然而,在涉及多个智能体互动的应用中,智能体之间相互作用和共同进化则催生了新的行为模式和更高的复杂性。例如,多机器人控制、通讯和语言的发现、多人游戏以及社会困境的分析等,都是在多智能体领域中进行的。(这里是针对这篇论文中的描述)
然而,传统的强化学习方法,例如 Q-Learning 或策略梯度(policy gradient),并不适合多智能体环境。一个挑战是,随着训练的进行,每个智能体的策略都在变化,这使得环境对于任何单一智能体来说都是不稳定的——这种不稳定性不是智能体自身策略变化所能解释的。这就给学习的稳定性带来了挑战,也使得无法直接使用经验回放,而这对于稳定深度 Q-Learning 来说至关重要。另一方面,当多个智能体需要协调行动时,策略梯度方法往往会表现出很高的方差。
MADDPG 的主要想法
MADDPG 提出了一种通用的多智能体学习算法,该算法满足:
- 学到的策略在执行时仅依赖于局部信息(即智能体自己的观测)
- 不需要假设环境动态模型是可微分的,也不需要对智能体间通信方式的结构做特定假设
- 不仅适用于合作互动,还适用于竞争或混合互动。
MADDPG 采取了集中式训练与分散式执行的框架( centralized training with decentralized execution),让策略在训练期间可以利用额外信息来简化训练过程,但这些信息在测试时则不会被使用。MADDPG 对 actor-critic 策略梯度方法的一个简单扩展,在这个扩展中,critic 会获得关于其他智能体策略的额外信息,而 actor 则只能访问局部信息。在训练结束后,局部信息在 actor 在执行阶段被使用,它们以分散的方式行动,并且适用于合作与竞争的环境。
MADDPG 的模型结构
考虑一个包含 N 个智能体的游戏,每个智能体的策略由参数 theta = {theta_1, ..., theta_N} 确定,设 pi = {pi_1, ..., pi_N} 为所有智能体策略的集合。那么我们可以为智能体 i 的期望回报的梯度 J(theta_i) 写出如下公式:
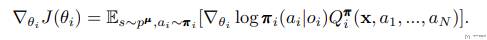
这里的 Q_i 是一个集中化动作价值函数(centralized action-value function),它输入所有智能体的动作 {a_1, ... , a_N} 和一些状态信息 x,并输出智能体 i 的 Q-值(注意,这里 {a_1, ... , a_N} 是可以拿到的,这是因为我们会通过 batch 里面拿数据进行训练,此时会有 action)。
在最简单的情况下,x 可以包含所有智能体的观测数据,即 x = (o_1, ..., o_N),但如果有额外的状态信息可用,我们也可以包含这些信息。由于每个 Q_i 是单独学习的,智能体可以有不同的奖励结构(这里需要注意,由于每个 agent 都有自己的奖励,因此可以单独为每一个 agent 训练一个 Q_i,相当于计算 td-error 的时候,可以给每一个 agent 都计算一个),包括在竞争环境中的相互冲突奖励。
于是 MADDPG 整体的结构如下所示,每一个 agent 都有一个自己的策略,同时也都有自己的 Q-函数(这里与值分解不同,值分解里面是所有 agent 是一个奖励,需要利用 Q 去拆解,这里是每一个 agent 都有自己的奖励,只不过在计算 critic 的时候,可以看到其他 agent 的动作和观测)。这里的动作是可以拿到的,只需要 actor 先输出动作概率,就有动作了,然后 critic 根据动作计算 Q 值。
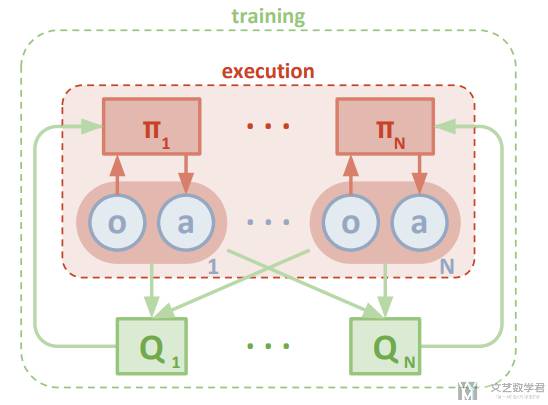
MADDPG 模型扩展
上面介绍了 MADDPG 的主要想法,下面包含两个扩展:
推断其他智能体的策略:原始MADDPG中,每个智能体的 Q 网络均需要接收所有智能体的动作(策略)作为输入,作者提出这一假设可以适当放松,此时每个智能体可以通过对其他智能体的策略进行估计而替代其他智能体真实的策略,即除了学习 Actor 网络和 Q 网络之外,还需要学习其余所有智能体策略的估计。但是感觉每个 agent 需要学习的网络较多,还会随着 agent 数量变多而变多。
对于 agent i 来说,需要对其他每一个 agent 学习一个策略 u_ij,用于估计 agent j 的动作。估计策略的函数如下所示(这里就是一个极大似然估计,希望在观测 o_j 的情况下,出现 a_j 的概率最大),这里 H 是 entropy of the policy distribution:
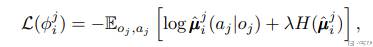
智能体的策略组合:为了进一步增强模型应对敌对智能体策略改变所导致的环境非平稳性,作者提出每个智能体可以训练得到由个不同子策略组成的策略集合,即每个智能体的策略是个不同子策略的组合,每个子策略都拥有一个经验回访池,单独训练。
MADDPG 代码实现
下面结合代码来在详细说一下 MADDPG。关于 DDPG 的更新,可以参考 Deep Deterministic Policy Gradient 里面的伪代码。下面的代码主要参考 maddpg_learner.py,他是没有实现 MADDPG 原文里面的两个扩展的。
Train Critic
首先我们计算 td-error,计算的式子如下所示:

这里 y(也就是 target)的计算如下所示:
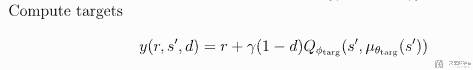
于是我们可以写出对应的代码(这里代码只是参考,完整代码见 maddpg_learner.py):
- q_taken = critic(inputs, actions)
- target_vals = target_critic(inputs, target_actions) # caluclate target
- td_error = (q_taken - targets)
- loss = (masked_td_error ** 2).mean()
Train Actor
接着我们计算 policy loss,计算的式子如下所示:
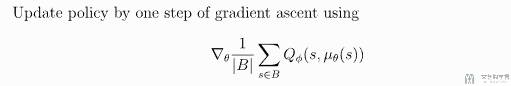
于是可以写出对应的大致的代码(同样,完整的代码见 maddpg_learner.py):
- pis = multiagent_controller.forward(batch) # 概率
- new_actions = sample(pi, hard=True)) # 动作
- q = critic(inputs, new_actions)
- pg_loss = -q.mean() + 0.01 * (pis ** 2).mean()
核心代码如上,首先计算动作的概率,接着选出动作,最后根据状态和动作计算 Q 值。同时我们将这里概率也用上,加在 loss 最后用于进行正则化。
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论