文章目录(Table of Contents)
简介
这一篇会详细介绍关于Python的正则表达式的相关内容. 我们之前有一篇介绍了一些关于正则表达式的相关内容, Python正则表达式指南, 但是那个比较简单.
因为这次找到了一个比较好的教程, 所以准备完整详细的来写一下Python正则表达式的相关内容. 这里不仅会包括基础的Python的正则表达式的内容, 还会包括正则表达式与pandas结合使用的相关内容.
我写的顺序可能会和教程的顺序有所不同, 我会按照我习惯的顺序进行书写. 这个教程可能更像是一步一步在教, 慢慢引出所有的概念, 但是我在写的时候就会把一些相同的东西整理到一起去.
先说说正则表达式的优点: 正则表达式在处理文本信息的时候还是一个很常用的工具的.
参考资料: Tutorial: Python Regex (Regular Expressions) for Data Scientists
Python正则表达式指南
正则表达式可以做什么
Regular expressions (regex) are essentially text patterns that you can use to automate searching through and replacing elements within strings of text. This can make cleaning and working with text-based data sets much easier, saving you the trouble of having to search through mountains of text by hand.
数据准备与导入库
我们测试的时候会使用钓鱼邮件来进行测试. 数据集链接为Fraudulent E-mail Corpus. 但我们可能不会使用完整的数据集, 我们会使用部分数据集, 部分数据集链接为: test_emails.txt
我们导入我们需要的数据集, 我们在文件路径前使用了r, 这是将string转换为raw string, 这是防止计算机读取字符串时可能引起的冲突, 例如路径中的反斜杠:
- fh = open(r"/content/drive/My Drive/Machine Learning/dataset/test_email.txt", "r").read()
最后导入我们这次会使用到的python库.
- import re
- import numpy as np
- import pandas as pd
一些常见的pattern
wmatches alphanumeric characters, which means a-z, A-Z, and 0-9. It also matches the underscore, _, and the dash, -.dmatches digits, which means 0-9.smatches whitespace characters (常见空白字符), which include the tab, new line, carriage return, and space characters.Smatches non-whitespace characters (非空白字符)..matches any character except the new line charactern(匹配除了换行之后的所有内容).- ---------特殊符号------------
*matches zero or more instances of a pattern on its left. This means it looks for repeating patterns. When we look for repeating patterns, we say that our search is "greedy." (当我们使用repeating pattern的时候, 我们称我们的搜索是贪婪模式)+matches 1 or more instances of a pattern on its left. (注意这里+和*的区别, +是需要匹配至少一个的)- 反斜杠, The backslash is a special character used for escaping other special characters. (这个反斜杠是转义符. 例如"?"可能在正则表达是中有其他的含义, 但是如果我们就是要匹配?, 我们就需要在前面加上反斜杠)
- ----------括号的使用-----------
[ ]match any character placed inside them. For instance, if we want to find"a","b", or"c"in a string, we can use[abc]as the pattern. The patterns we discussed above apply as well.[\w\s]would find either alphanumeric or whitespace characters. (下面有个例子详细解释一下中括号的作用)
更加详细的常见pattern的表格可以在Python正则表达式指南中找到.
这里详细说一下中括号的问题, 我们举一个例子来进行说明. 有了中括号之后, 写起来可以更加简洁.
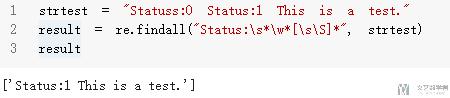
- strtest = "Statuss:0 Status:1 This is a test."
- result = re.findall("Status:\s*\w*[\s\S]*", strtest)
- result
上面相同的例子, 如果不写中括号, 那么匹配的结果就是下面这个样子的.
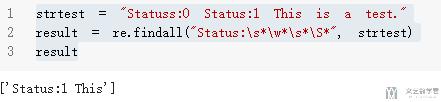
- strtest = "Statuss:0 Status:1 This is a test."
- result = re.findall("Status:\s*\w*\s*\S*", strtest)
- result
匹配结果是无法匹配完全的, 匹配结果如下所示.
那么我们要是想不用中括号, 达成一样的效果, 应该写成下面这个样子.
- strtest = "Statuss:0 Status:1 This is a test."
- result = re.findall("Status:\s*\w*\s*\S*\s*\S*\s*\S*\s*\S*", strtest)
- result

所以, 中括号的作用可以理解为反复匹配中括号中出现的pattern, 且里面是没有顺序的.
一些常见的re的函数
re.findall(), 找出所有与pattern匹配的内容.re.search(), 找出第一个与pattern匹配的内容.re.split(), 将string按照指定的符号进行划分.re.sub(), 将string中的部分进行替换.
我们下面依次来介绍这四个常见的函数.
找出发件人--正则表达式之re.findall
首先我们第一个任务是找出邮件的发件人. 我们使用re.findall来完成任务. This function takes two arguments in the form of re.findall(pattern, string). 这个函数接收两个参数, 分别是pattern和string. 也就是要匹配的规则(在这里我们会用到的pattern就是.*), 和要查找的字符串.
比如要找出发件人, 我们会使用下面的方式来进行匹配:
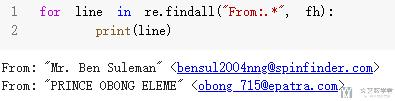
- for line in re.findall("From:.*", fh):
- print(line)
其中"."表示任意字符, "*"表示重复无数次. 于是, 我们得到了下面的匹配结果.
接下来, 我们希望更进一步. 我们只需要发件人的姓名. 于是我们第一个想法就是先找出包含收件人信息的行, 再从这些行里面找出姓名. 于是我们就可以写成下面这个样子.
- match = re.findall("From:.*", fh)
- for line in match:
- print(re.findall("\".*\"", line))
于是我们得到了下面的结果, 可以看到成功返回了姓名. 需要注意的是findall返回的是一个list.

接着, 我们再更进一步, 我们希望获取发件人的邮箱. 于是我们可以写成下面的这个样子.
- match = re.findall("From:.*", fh)
- for line in match:
- print(re.findall("\w\S*@.*\w", line))
我们简单对上面的pattern进行解释. 这个pattern可以分成两个部分来看, 分别是"艾特(这里输入符号会出现问题)"前面和"艾特"后面. 因为邮箱一定是有"@"的.
- 在"艾特"前面, 我们使用\w\S*, 一般邮箱是字母组成, 但有时会有下划线, 所以需要使用\W
- 在"艾特"后面, 我们使用.*\w, 后面也是可能包含所有的可能性, 且最后结尾一定是字母或数字, 所以我们用\w结尾.
正则表达式之re.search
首先我们看一下findall和search之间的区别. 简单来说就是findall会找出所有符合pattern的string并返回为一个list; search只会找出第一个符合要求的string, 并返回为match object.
While re.findall() matches all instances of a pattern in a string and returns them in a list, re.search() matches the first instance of a pattern in a string, and returns it as a re match object.
和findall一样, search也是接受两个参数, 分别是pattern和string. 我们还是使用上面的邮件的例子来进行说明. 我们找出文本中的第一个发件人的信息.
- match = re.search("From:.*", fh)
- print(match)
- print(match.group())
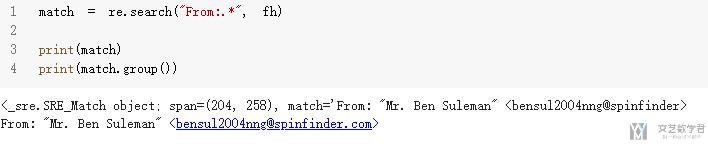
可以看到的是, re.search返回的是match object, 并不是string, 里面还包含一些其他的信息. 我们需要使用group将其转换为string, 如上面例子所示. (As we can see, group() converts the match object into a string.)
正则表达式之re.split
现在我们的任务是找出邮箱的用户名和注册的网站. 例如bensul2004nng@spinfinder.com, 我们就是要分别打印出bensul2004nng和spinfinder.com. 这里我们就需要使用到re.split这个函数了. 我们直接来看下面的例子.
- match = re.findall("From:.*", fh)
- for line in match:
- for item in re.findall("\w\S*@.*\w",line): # 找出邮箱
- print(re.split("@", item))

正则表达式之re.sub
前面讲到的三个都是执行的查找的功能, 这里要介绍的re.sub是来进行替换工作的. 正如他的名字所说的, 就是substitutes.
re.sub接受三个参数, 分别是:
- The first is the substring to substitute, 要替换掉的内容
- The second is a string we want in its place, 我们想要替换的内容
- The third is the main string itself, 要替换的string
我们下面看一个例子, 就是将string中的From替换为Email.
- sender = re.search("From:.\".*\"", fh)
- address = sender.group()
- email = re.sub("From", "Email", address)
- print(address)
- print(email)

Python正则表达式案例分析
上面我们讲了最基本的python的正则表达式的相关内容. 在实际处理数据的时候, 我们更多的时候会使用pandas, 所以这一部分我们会来说明一下如何在pandas中来使用正则表达式来完成我们的需求.
在这一部分, 我们的最终任务是将邮件按下面的几个部分进行排序整理, 这样可以更加方便我们进行整理.
sender_name, 发件人姓名sender_address, 发件人地址recipient_address, 收件人地址recipient_name, 收件人姓名date_sent, 发件时间subject, 邮件的标题email_body, 邮件主体内容
上面的每一个部分我们会存储到pandas中去. 也就是上面的每一部分的内容都会是一行. 列的内容包括发件人姓名, 发件人地址等.
在这里我们会额外用到一个库email, 这个是用来处理邮件的主体的.
- import re
- import pandas as pd
- import email
- emails = []
- fh = open(r"/content/drive/My Drive/Machine Learning/dataset/test_email.txt", "r").read()
其中上面创建的emails是用来存储的.
邮件的分割-re.split
因为现在是一个txt文件中包含多封邮件, 所以我们需要将其进行分割. 通过观察邮件, 我们发现每一封邮件开头都是"From r"这样的形式, 所以我们首先将其进行分割.
- contents = re.split("From r", fh)
- contents.pop(0) # 去掉第一个, 因为当使用"From r"进行分割的时候, 第一个是空
- contents
可以注意的是, 我们使用了pop(0)来去掉第一个, 这是因为在进行分割的时候, 第一个是空. 我们可以这样来简单理解一下:
- 例如"a+b", 我们按照+来分割就是a和b.
- 要是"+b"按照+来进行分割就是空和b, 此时就要去掉第一个空.
最终得到下面的结果.

获得姓名和邮箱地址-re.search与re.sub
再对每一封邮件进行分割之后, 我们接着来获取每一封邮件的姓名和邮箱地址, 这里包括
sender_name, 发件人姓名sender_address, 发件人地址recipient_address, 收件人地址recipient_name, 收件人姓名
为了获取上面的这些信息, 我们要分为下面的几个步骤
- 依次对每一封邮件进行处理
- 开始找发件人的信息
- 找出发件人的信息, 注意这里要对可能出现的异常进行处理
- 从发件人信息中分离出名字和邮箱, 注意进行异常处理
- 将发件人的名字和邮箱存储到字典中去
- 开始找收件人的信息(这里的步骤和上面是一样的)
下面我们看一下完整的代码, 其实这一部分要想写的很完善, 还是要考虑周到的, 还是有很多细节要进行书写的.
- for item in contents:
- # %%%%%%%%%%%%%%%%%%%%%%%%
- # step 1: 处理每一封邮件
- emails_dict = {}
- # %%%%%%%%%%%%%%%%%%%%%%%%
- # step 2: 找出发件人信息
- sender = re.search("From:.*", item)
- # step 2.1: 对可能出现的异常进行处理(如果没有找到发件人信息, 则设置为None)
- if sender is not None:
- s_email = re.search("\w\S*@.*\w",sender.group())
- s_name = re.search("\".*\"",sender.group())
- else:
- s_email = None
- s_name = None
- # step 2.2: 对发件人姓名和邮件进行检测
- if s_email is not None:
- sender_email = s_email.group()
- else:
- sender_email = None
- if s_name is not None:
- # 对于名字, 我们删除名字两边的双引号
- sender_name = re.sub("\"","",s_name.group())
- else:
- sender_name = None
- # step 2.3: 存储到emails_dict中
- emails_dict['sender_email'] = sender_email
- emails_dict['sender_name'] = sender_name
- # %%%%%%%%%%%%%%%%%%%%%%%%
- # step 3: 找出收件人信息
- recipient = re.search("To:.*", item)
- # step 3.1: 对可能出现的异常进行处理(如果没有找到收件人信息, 则设置为None)
- if recipient is not None:
- r_email = re.search("\w\S*@.*\w",recipient.group())
- r_name = re.search(r"\".*\"",recipient.group())
- else:
- r_email = None
- r_name = None
- # step 3.2: 对发件人姓名和邮件进行检测
- if r_email is not None:
- recipient_email = r_email.group()
- else:
- recipient_email = None
- if r_name is not None:
- # 对于名字, 我们删除名字两边的双引号
- recipient_name = re.sub("\"","",r_name.group())
- else:
- recipient_name = None
- # step 3.3: 存储到emails_dict中
- emails_dict['recipient_email'] = recipient_email
- emails_dict['recipient_name'] = recipient_name
- print(emails_dict)
最终的结果如下所示, 可以看到正确的提取了发件人和收件人的信息:

获取邮件的发送时间
在获取了收件人和发件人的信息之后, 我们来获得邮件的发送时间. 我们这里写的时候使用第0个contents来进行测试.
整体的步骤还是分为两步:
- 第一步: 获取date的大致位置
- 第二步: 提取里面详细的date的信息
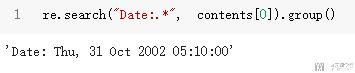
首先我们获取date的信息.
- re.search("Date:.*", contents[0]).group()
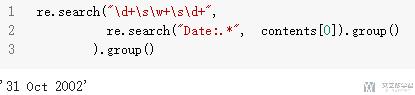
接着我们获取详细的date的信息.
- re.search("\d+\s\w+\s\d+",
- re.search("Date:.*", contents[0]).group()
- ).group()
我们来解释一下上面提取date时候用到的pattern. 我们要提取的日期的格式是DD MMM YYYY的格式.
- 第一个DD是阿拉伯数字, 可能是一位数, 也可能是两位是, 所以这里使用了\d+, 注意这里使用了+而不是使用*, 这是因为日期一定是包含一位数字的, 同理后面的月份和年份的匹配也是类似的.
- 接着是一个空格, 所以我们使用了\s
- 接着是月份, 是三个字母, 所以我们使用了\w+
- 月份之后又是一个空格, 所以我们还是使用了\s
- 最后是年份, 是四个数字, 我们这里使用\d+
为了考虑完整, 我们的完整的代码如下所示, 我们需要考虑search出是None的情况.
- for item in contents:
- # %%%%%%%%%%%%%%%%%%%%%%%%
- # step 1: 处理每一封邮件
- emails_dict = {}
- # %%%%%%%%%%%%%%%%%%%%%%%%
- # step 2: 查找日期大致范围
- date_field = re.search("Date:.*", item)
- # %%%%%%%%%%%%%%%%%%%%%%%%
- # step 3: 得到详细的日期
- if date_field is not None:
- date = re.search("\d+\s\w+\s\d+", date_field.group())
- else:
- date = None
- # %%%%%%%%%%%%%%%%%%%%%%%%
- # step 4: 将日期进行保存
- if date is not None:
- date_sent = date.group()
- else:
- date_sent = None
- emails_dict['date_sent'] = date_sent
- print(emails_dict)
最终可以获取下面的结果:

获取邮件主题
这里的内容提取和之前的操作详细, 我们首先获得subject的大致内容, 接着进行精细的内容提取.
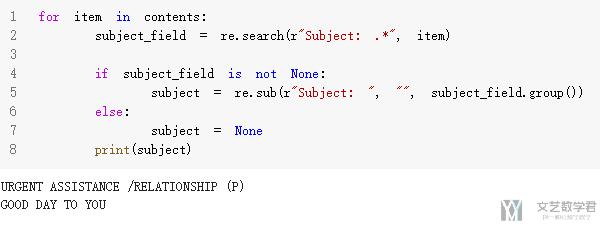
我们首先进行大致内容的提取, 获得如下的结果.
- subject_field = re.search(r"Subject: .*", item)

接着我们的任务就是获取上面提取的Subject之后的内容, 我们直接使用替换, 将前面的Subject替换成空即可.
- subject = re.sub(r"Subject: ", "", subject_field.group())
所以, 最终完整的代码, 和最终的结果如下图所示.
获取邮件主体
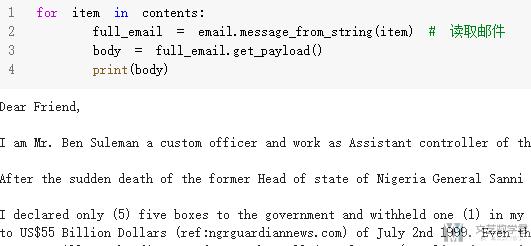
最后一个步骤就是获取邮件的主题内容. 这一部分我们会直接使用email这个包来完成任务.
我们首先将整个email读入, 存储为email的对象, 这个对象包含header和payload, 分别就是对应邮件的头部和邮件的内容.
- for item in contents:
- full_email = email.message_from_string(item) # 读取邮件
- body = full_email.get_payload()
- print(body)
我们大致看一下打印出来的结果, 因为内容有点长, 我们截图就只截取部分.
获取完整信息
上面我们完成了各个部分的代码, 获取header和获取body的部分. 下面我们只需要将每一个邮件的email_dict存储到email中即可, 也就是下面的代码:
- emails.append(emails_dict)
下面是完整的代码(我感觉原教程这里有一些问题, 在计算email的个数的时候, 我在这里进行了修改):
- import re
- import pandas as pd
- import email
- emails = []
- fh = open(r"/content/drive/My Drive/Machine Learning/dataset/test_email.txt", "r").read()
- contents = re.split(r"From r",fh)
- contents.pop(0)
- for item in contents:
- emails_dict = {}
- sender = re.search(r"From:.*", item)
- if sender is not None:
- s_email = re.search(r"\w\S*@.*\w", sender.group())
- s_name = re.search(r":.*<", sender.group())
- else:
- s_email = None
- s_name = None
- if s_email is not None:
- sender_email = s_email.group()
- else:
- sender_email = None
- emails_dict["sender_email"] = sender_email
- if s_name is not None:
- sender_name = re.sub("\s*<", "", re.sub(":\s*", "", s_name.group()))
- else:
- sender_name = None
- emails_dict["sender_name"] = sender_name
- recipient = re.search(r"To:.*", item)
- if recipient is not None:
- r_email = re.search(r"\w\S*@.*\w", recipient.group())
- r_name = re.search(r":.*<", recipient.group())
- else:
- r_email = None
- r_name = None
- if r_email is not None:
- recipient_email = r_email.group()
- else:
- recipient_email = None
- emails_dict["recipient_email"] = recipient_email
- if r_name is not None:
- recipient_name = re.sub("s*<", "", re.sub(":s*", "", r_name.group()))
- else:
- recipient_name = None
- emails_dict["recipient_name"] = recipient_name
- date_field = re.search(r"Date:.*", item)
- if date_field is not None:
- date = re.search(r"\d+\s\w+\s\d+", date_field.group())
- else:
- date = None
- if date is not None:
- date_sent = date.group()
- else:
- date_sent = None
- emails_dict["date_sent"] = date_sent
- subject_field = re.search(r"Subject: .*", item)
- if subject_field is not None:
- subject = re.sub(r"Subject: ", "", subject_field.group())
- else:
- subject = None
- emails_dict["subject"] = subject
- # "item" substituted with "email content here" so full email not displayed.
- full_email = email.message_from_string(item)
- body = full_email.get_payload()
- emails_dict["email_body"] = "email body here"
- emails.append(emails_dict)
- # Print number of dictionaries, and hence, emails, in the list.
- print("Number of emails: " + str(len(emails)))
- # Print first item in the emails list to see how it looks.
- for key, value in emails[0].items():
- print(str(key) + ": " + str(emails[0][key]))
我们需要注意的是, 为了显示的方便, 我们在这里body是直接都存储成了一样的内容. 最终的打印结果如下所示:

使用Pandas处理数据
经过上面的处理, 我们的数据已经保存为list, list里面是字典类型. 这个对于pandas是容易进行处理的. 我们下面简单看一下操作的流程.
- import pandas as pd
- # Module imported above, imported again as reminder.
- emails_df = pd.DataFrame(emails)
- emails_df
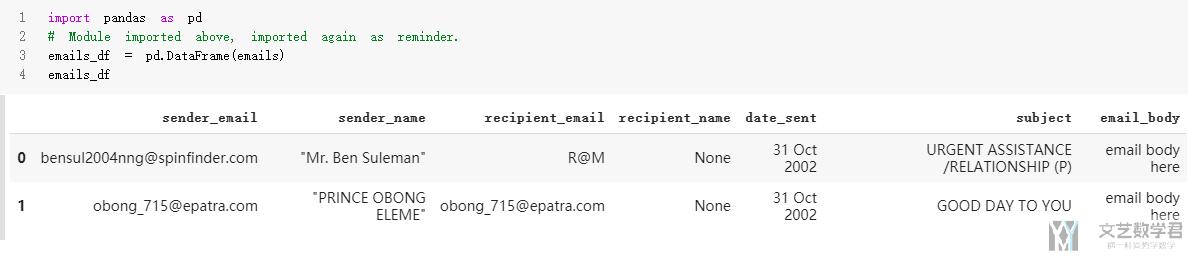
生成了dataframe数据结构, 我们可以很方便的查找指定的发件人的信息. 比如我们查询发件人邮箱中包含epatra或spinfinder的.
- emails_df[emails_df["sender_email"].str.contains("epatra|spinfinder")]
这里的查询结果就是上面两个, 我们就不放截图了.
当然, 上面contains也是可以使用正则表达式的, 比如我们想要找出发件邮箱包含spinfinder的邮件的内容, 也就是body部分.
在原教程中使用了四个步骤, 我感觉不是很复杂, 就在下面一起写完了.
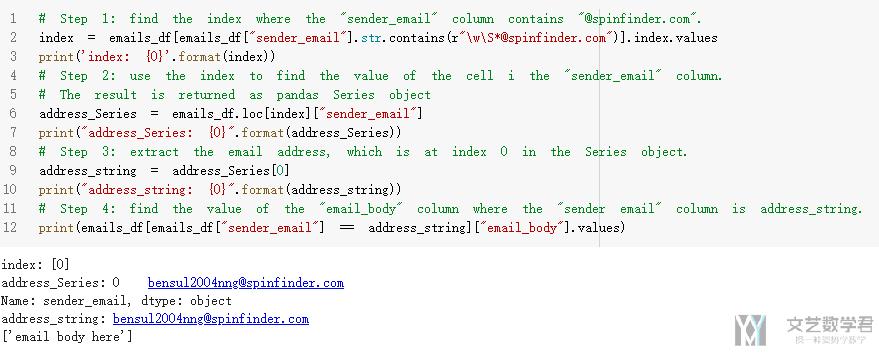
- # Step 1: find the index where the "sender_email" column contains "@spinfinder.com".
- index = emails_df[emails_df["sender_email"].str.contains(r"\w\S*@spinfinder.com")].index.values
- print('index: {0}'.format(index))
- # Step 2: use the index to find the value of the cell i the "sender_email" column.
- # The result is returned as pandas Series object
- address_Series = emails_df.loc[index]["sender_email"]
- print("address_Series: {0}".format(address_Series))
- # Step 3: extract the email address, which is at index 0 in the Series object.
- address_string = address_Series[0]
- print("address_string: {0}".format(address_string))
- # Step 4: find the value of the "email_body" column where the "sender email" column is address_string.
- print(emails_df[emails_df["sender_email"] == address_string]["email_body"].values)
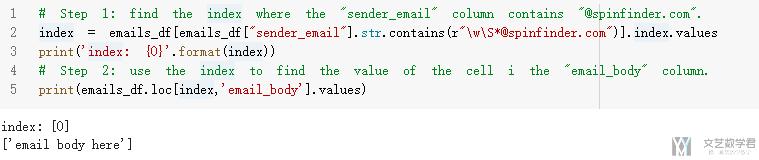
但是, 其实当我们知道了index之后, 使用两个步骤也是可以获得相同的结果的.
- # Step 1: find the index where the "sender_email" column contains "@spinfinder.com".
- index = emails_df[emails_df["sender_email"].str.contains(r"\w\S*@spinfinder.com")].index.values
- print('index: {0}'.format(index))
- # Step 2: use the index to find the value of the cell i the "email_body" column.
- print(emails_df.loc[index,'email_body'].values)
到这里就是所有的关于Python的正则表达式的内容了, 这一次的内容应该还是很详细的, 记录在这里方便之后查阅.
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论