文章目录(Table of Contents)
前言
之前写过一篇关于Python正则表达式的文章,关于(python)正则表达式,其实主要是找里面的一个参考链接,里面给了一张关于正则表达式图,很好用,也是为了我方便去查找,我把图在这里也放一下。
我参考的文章的链接:Python正则表达式指南
还有一个也是很好的教材, 我也会在后面有所提及, Tutorial: Python Regex (Regular Expressions) for Data Scientists
指南
在线测试网站
正则表达式在线测试 - 菜鸟工具:这个在线网站可以通过点击生成代码来生成各种语言下的正则表达式。
正则表达式匹配中文标点
关于汉字和汉字标点的匹配,我大概说一下:
匹配中文标点符号
- String str="[\u3002\uff1b\uff0c\uff1a\u201c\u201d\uff08\uff09\u3001\uff1f\u300a\u300b]"
该表达式可以识别出: 。 ; , : “ ”( ) 、 ? 《 》 这些标点符号。
关于上面的\u3002等,都是中文标点对应的unicode码,具体的对应关系,可以看这个链接:中文标点符号unicode码,我大概罗列在下面方便使用:
- String str="[\u3002\uFF1F\uFF01\uFF0C\u3001\uFF1B\uFF1A\u300C\u300D\u300E\u300F\u2018\u2019\u201C\u201D\uFF08\uFF09\u3014\u3015\u3010\u3011\u2014\u2026\u2013\uFF0E\u300A\u300B\u3008\u3009]"
匹配中文汉字
- String str="[\u4e00-\u9fa5]";
该表达式可以识别出任何汉字。
比如,我们使用的时候,需要匹配不包含中文的字符,可以这么书写:
- re.match('[^\u4e00-\u9fa5]+','你好呀-')
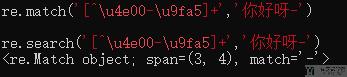
最后贴出参考的资料
敏感词库
最近做东西需要进行敏感词的过滤,于是在网上寻找敏感词库,目前找到两个比较好用的,放在这里:
Sensitive-word:这个敏感词库是有分类的
年華社区所使用的敏感词汇名单:这是一份没有分类的敏感词库
正则表达式分组
例如我们现在有这样一个需求, 原始的字符串是/123/, 现在我们想要变为str(/123/), 也就是在外面加上str()进行包裹, 我们就可以正则表达式中的分组的功能.
首先是搜索时的正则表达式:
- (/.*/){1}
接着是替换时的正则表达式, 在vs code的时候, 引用的时候需要使用$符号.
- \textipa{$1}
正则表达式的元字符和语法图
下面就直接放一下图片(图片转在上面那个文章):
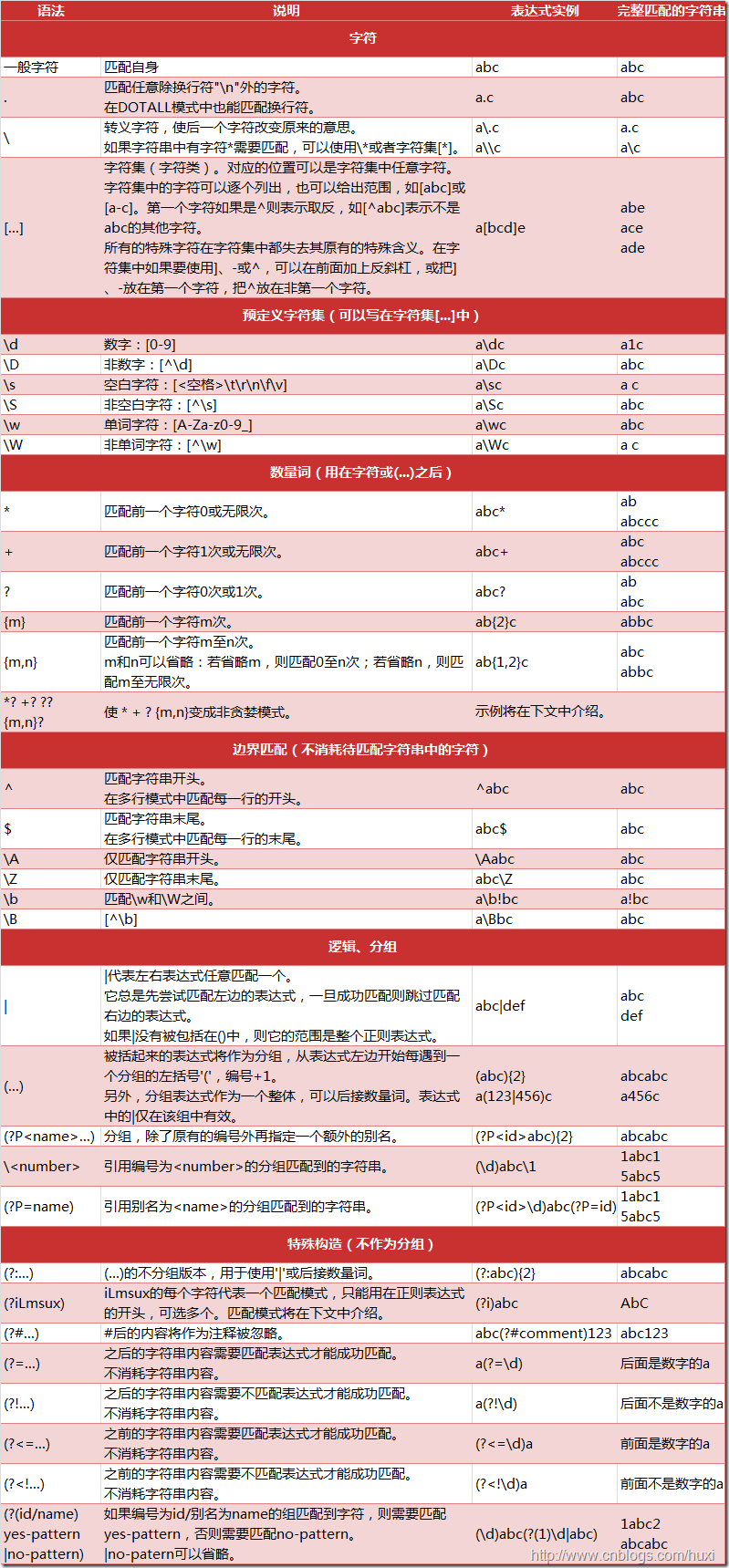
好了,主要放一张图片,之后有什么关于正则表达式的内容也会在这篇文章进行更新的。
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论