文章目录(Table of Contents)
简介
Transformers 是由 Hugging Face 开发的一个 NLP 包,支持加载目前绝大部分的预训练模型。随着 BERT、GPT 等大规模语言模型的兴起,越来越多的公司和研究者采用 Transformers 库来构建 NLP 应用,因此熟悉 Transformers 库的使用方法很有必要(最近也是看了 Decision Transformer 的相关代码,使用了 Hugging Face 的相关内容,因此在这里系统的看一下)。
本文的主要是对下面参考链接一和链接二的内容进行了整理。会简单介绍 Transformers 的使用,和 Transformers 库中的两个重要组件:模型(Models 类)和分词器(Tokenizers 类)。
参考链接
- Hugging Face 的 Transformers 库快速入门(一):开箱即用的 pipelines,本文主要参考的内容;
- Hugging Face 的 Transformers 库快速入门(二):模型与分词器,本文主要参考的内容;
- Huggingface Transformers Index,Hugging Face 的主页,可以查看详细的接口;
开箱即用的 pipelines
Transformers 库最基础的对象就是 pipeline() 函数,它封装了预训练模型和对应的前处理和后处理环节。我们只需输入文本,就能得到预期的答案。目前常用的 pipelines 有:
feature-extraction(获得文本的向量化表示)fill-mask(填充被遮盖的词、片段)ner(命名实体识别)question-answering(自动问答)sentiment-analysis(情感分析)summarization(自动摘要)text-generation(文本生成)translation(机器翻译)zero-shot-classification(零训练样本分类)
Pipelines 的简单使用
下面看一个使用 pipeline() 函数来进行「文本生成」的例子。我们指定任务和使用的模型,来生成中文的古诗:
- from transformers import pipeline
- generator = pipeline("text-generation", model="uer/gpt2-chinese-poem")
- results = generator(
- "[CLS] 万 叠 春 山 积 雨 晴 ,",
- num_return_sequences=2,
- max_length=50
- )
- print(results)
运行之后可以生成如下的内容:
- [
- {'generated_text': '[CLS] 万 叠 春 山 积 雨 晴 , 烟 消 云 霁 列 峰 生 。 遥 知 草 木 焦 枯 处 , 大 野 流 泉 水 自 清 。 成 新 式 式 金 堤 , 圣 德 神 功 已 尽 跻 。 不'},
- {'generated_text': '[CLS] 万 叠 春 山 积 雨 晴 , 晓 看 沧 海 暮 云 生 。 千 峰 列 翠 依 遥 立 , 双 涧 分 流 自 在 鸣 。 猿 鸟 不 惊 人 世 远 , 鱼 龙 常 共 太 平 平 。 谁'}
- ]
Pipelines 背后做了什么
pipeline() 函数实际上封装了许多操作,下面我们就来了解一下它们背后究竟做了啥。以情感分析 pipeline 为例,我们运行下面的代码:
- from transformers import pipeline
- classifier = pipeline("sentiment-analysis")
- result = classifier("I've been waiting for a HuggingFace course my whole life.")
- print(result)
就可以得到结果:
- [{'label': 'POSITIVE', 'score': 0.9598048329353333}]
实际上它的背后经过了三个步骤:
- 预处理 (preprocessing),将原始文本转换为模型可以接受的输入格式;
- 将处理好的输入送入模型;
- 对模型的输出进行后处理 (postprocessing),将其转换为人类方便阅读的格式。
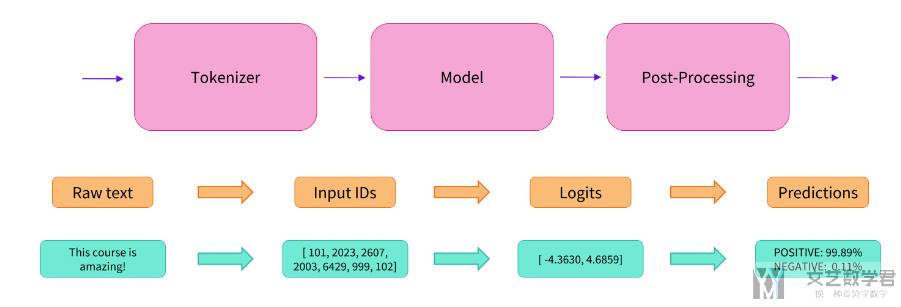
使用分词器进行预处理
因为神经网络模型无法直接处理文本,因此首先需要通过预处理环节将文本转换为模型可以理解的数字。具体地,我们会使用每个模型对应的分词器 (tokenizer) 来进行:
- 将输入切分为词语、子词或者符号(例如标点符号),统称为 tokens;
- 根据模型的词表将每个 tokens 映射到对应的 token 编号(就是一个数字);
- 根据模型的需要,添加一些额外的输入。
我们对输入文本的预处理需要与模型自身预训练时的操作完全一致,只有这样模型才可以正常地工作。注意,每个模型都有特定的预处理操作,如果对要使用的模型不熟悉,可以通过 Model Hub 查询。这里我们使用 AutoTokenizer 类和它的 from_pretrained() 函数,它可以自动根据模型 checkpoint 名称来获取对应的分词器。
情感分析 pipeline 的默认 checkpoint 是 distilbert-base-uncased-finetuned-sst-2-english,下面我们手工下载并调用其分词器:
- from transformers import AutoTokenizer
- checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
- tokenizer = AutoTokenizer.from_pretrained(checkpoint)
- raw_inputs = [
- "I've been waiting for a HuggingFace course my whole life.",
- "I hate this so much!",
- ]
- inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
- print(inputs)
输入的结果如下所是,上面的 truncation 表示「截断操作」:
- {
- 'input_ids': tensor([
- [ 101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172, 2607, 2026, 2878, 2166, 1012, 102],
- [ 101, 1045, 5223, 2023, 2061, 2172, 999, 102, 0, 0,
- 0, 0, 0, 0, 0, 0]
- ]),
- 'attention_mask': tensor([
- [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
- [1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]
- ])
- }
上面输出中包含两个键 input_ids 和 attention_mask,其中:
input_ids对应分词之后的 tokens 映射到的数字编号列表;attention_mask则是用来标记哪些 tokens 是被填充的(这里“1”表示是原文,“0”表示是填充字符);
将预处理好的输入送入模型
预训练模型的下载方式和分词器 (tokenizer) 类似,Transformers 包提供了一个 AutoModel 类和对应的 from_pretrained() 函数。下面我们手工下载这个 distilbert-base 模型:
- from transformers import AutoModel
- checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
- model = AutoModel.from_pretrained(checkpoint)
预训练模型的本体只包含基础的 Transformer 模块,对于给定的输入,它会输出一些神经元的值,称为 hidden states 或者特征 (features)。对于 NLP 模型来说,可以理解为是文本的高维语义表示。这些 hidden states 通常会被输入到其他的模型部分(称为 head)(也就是上面的模型是没有 head 的),以完成特定的任务,例如送入到分类头中完成文本分类任务。
基本所有的模型都有类似的模型结构,只有模型的最后一个部分会使用不同的 head 来完成相应的任务。下图是一个简单的例子:
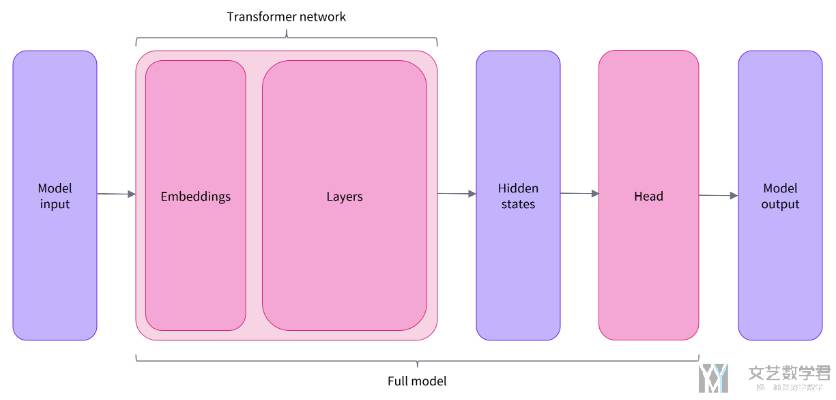
Transformer 模块的输出是一个维度为 (Batch size, Sequence length, Hidden size) 的三维张量,其中
- Batch size 表示每次输入的样本(文本序列)数量,即每次输入多少个句子,上例中为 2;
- Sequence length 表示文本序列的长度,即每个句子被分为多少个 token,上例中为 16;
- Hidden size 表示每一个 token 经过模型编码后的输出向量(语义表示)的维度(预训练模型编码后的输出向量的维度通常都很大,例如 Bert 模型 base 版本的输出为 768 维,一些大模型的输出维度为 3072 甚至更高)。
这里我们打印出 distilbert-base 模型的输出维度,将 input 输入模型:
- from transformers import AutoTokenizer
- from transformers import AutoModel
- # 对 input 进行预处理
- checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
- tokenizer = AutoTokenizer.from_pretrained(checkpoint)
- raw_inputs = [
- "I've been waiting for a HuggingFace course my whole life.",
- "I hate this so much!",
- ]
- inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
- print(inputs)
- # 加载模型并输出
- checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
- model = AutoModel.from_pretrained(checkpoint)
- output = model(**inputs) # 将 input 传入 model
- print(output.last_hidden_state.shape)
Transformers 模型的输出格式类似 namedtuple 或字典,可以像上面那样通过属性访问,也可以通过键(outputs["last_hidden_state"]),甚至索引访问(outputs[0])。上面模型输出的大小如下所是:
- torch.Size([2, 16, 768])
对于情感分析任务,很明显我们最后需要使用的是一个「二分类 head」。因此,实际上我们不会使用 AutoModel 类,而是使用 AutoModelForSequenceClassification:
- from transformers import AutoTokenizer
- from transformers import AutoModelForSequenceClassification
- checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
- tokenizer = AutoTokenizer.from_pretrained(checkpoint)
- model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
- raw_inputs = [
- "I've been waiting for a HuggingFace course my whole life.",
- "I hate this so much!",
- ]
- inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
- outputs = model(**inputs)
- print(outputs.logits.shape)
最后输出的结果如下。可以看到,对于 batch 中的每一个样本,模型都会输出一个两维的向量(每一维对应一个标签,positive 或 negative)。
- torch.Size([2, 2])
对模型输出进行后处理
由于模型的输出只是一些数值,因此并不适合人类阅读。例如我们打印出上面例子的输出:
- tensor([[-1.5607, 1.6123],
- [ 4.1692, -3.3464]], grad_fn=<AddmmBackward0>)
模型对第一个句子输出 [-1.57, 1.61],对第二个句子输出 [4.16, -3.34],它们并不是概率值,而是模型最后一层输出的 logits 值(所有 Transformers 模型都会输出 logits 值,因为训练时的损失函数通常会自动结合激活函数,例如 SoftMax,与实际的损失函数,例如交叉熵 cross entropy)。要将他们转换为概率值,还需要让它们经过一个 SoftMax 层,例如:
- import torch
- predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
- print(predictions)
经过上面的输出之后,模型就可以输出易于理解的概率值了。
- tensor([[4.0195e-02, 9.5980e-01],
- [9.9946e-01, 5.4418e-04]], grad_fn=<SoftmaxBackward0>)
- {0: 'NEGATIVE', 1: 'POSITIVE'}
于是我们可以得到最终的预测结果如下:
- 第一个句子: NEGATIVE: 0.0402, POSITIVE: 0.9598
- 第二个句子: NEGATIVE: 0.9995, POSITIVE: 0.0005
模型
在之前介绍 pipeline 模型时,我们使用 AutoModel 类根据 checkpoint 名称自动加载模型。当然,我们也可以直接使用对应的 Model 类。例如加载 BERT 模型(包括采用 BERT 结构的其他模型):
- from transformers import BertModel
- model = BertModel.from_pretrained("bert-base-cased")
加载模型
通过调用 Model.from_pretrained() 函数可以自动加载 checkpoint 对应的模型权重 (weights)。然后,我们可以直接使用模型完成它的预训练任务,或者在新的任务上对模型权重进行微调。
Model.from_pretrained() 会自动缓存下载的模型权重,默认保存到 ~/.cache/huggingface/hub,我们也可以通过 HF_HOME 环境变量自定义缓存目录。
所有存储在 Model Hub 上的模型都能够通过 Model.from_pretrained() 加载,只需要传递对应 checkpoint 的名称。当然了,我们也可以先将模型下载下来,然后将本地路径传给 Model.from_pretrained(),比如加载下载好的 Bert-base 模型:
- from transformers import BertModel
- model = BertModel.from_pretrained("./models/bert/")
部分模型的 Hub 页面中会包含很多文件,我们通常只需要下载:
- 模型对应的 config.json 和 pytorch_model.bin,
- 分词器对应的 tokenizer.json、tokenizer_config.json 和 vocab.txt。
保存模型
保存模型与加载模型类似,只需要调用 Model.save_pretrained() 函数。例如保存加载的 BERT 模型:
- from transformers import AutoModel
- model = AutoModel.from_pretrained("bert-base-cased")
- model.save_pretrained("./models/bert-base-cased/")
这会在保存路径下创建两个文件:
- config.json:模型配置文件,里面包含构建模型结构的必要参数;
- pytorch_model.bin:又称为 state dictionary,包含模型的所有权重。
这两个文件缺一不可,配置文件负责记录模型的结构,模型权重记录模型的参数。我们自己保存的模型同样可以通过 Model.from_pretrained() 加载,只需要传递保存目录的路径。下面是 config.json 文件的大致内容:

分词器
因为神经网络模型不能直接处理文本,我们需要先将文本转换为模型能够处理的数字,这个过程被称为编码 (Encoding):先使用分词器 (Tokenizers) 将文本按词、子词、符号切分为 tokens;然后将 tokens 映射到对应的 token 编号(token IDs)。
分词策略
根据切分粒度的不同,分词策略大概可以分为以下几种,关于这部分详细内容可以查看链接 分词策略:
- 按词切分(Word-based)
- 按字符切分(Character-based)
- 按子词切分(Subword-based)
目前按子词切分 (Subword tokenization) 是一种被广泛采用的方式。按子词 (Subword) 切分 高频词直接保留,低频词被切分为更有意义的子词。
例如 “annoyingly” 就是一个低频词,可以切分为 “annoying” 和 “ly”,这两个子词不仅出现频率更高,而且词义也得以保留。下图就是对文本 “Let’s do tokenization!“ 按子词切分的例子:

可以看到,“tokenization” 被切分为了 “token” 和 “ization”,不仅保留了语义,而且只用两个 token 就表示了一个长词。这中策略只用一个较小的词表就可以覆盖绝大部分的文本,基本不会产生 unknown tokens。尤其对于土耳其语等黏着语言,可以通过串联多个子词构成几乎任意长度的复杂长词。
加载和保存分词器
分词器的加载与保存与模型非常相似,也是使用 from_pretrained() 和 save_pretrained() 函数。例如,使用 BertTokenizer 类加载并保存 BERT 模型的分词器:
- from transformers import BertTokenizer
- tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
- tokenizer.save_pretrained("./models/bert-base-cased/")
与 AutoModel 类似,在大部分情况下,我们都应该使用 AutoTokenizer 类来加载分词器,它会根据 checkpoint 来自动选择对应的分词器(使用的接口是与上面一致的):
- from transformers import AutoTokenizer
- tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
- tokenizer.save_pretrained("./models/bert-base-cased/")
调用 Tokenizer.save_pretrained() 函数会在保存路径下创建三个文件:
- special_tokens_map.json:配置文件,里面包含 unknown tokens 等特殊字符的映射关系;
- tokenizer_config.json:配置文件,里面包含构建分词器需要的参数;
- vocab.txt:词表,每一个 token 占一行,行号就是对应的 token ID(从 0 开始)。
下面是 special_tokens_map.json 文件对应的内容:
- {
- "unk_token": "[UNK]",
- "sep_token": "[SEP]",
- "pad_token": "[PAD]",
- "cls_token": "[CLS]",
- "mask_token": "[MASK]"
- }
编码和解码文本
完整的文本编码 (Encoding) 过程实际上包含两个步骤:
- 分词:使用分词器按某种策略将文本切分为 tokens(也就是将);
- 映射:将 tokens 转化为对应的 token IDs。
因为不同预训练模型采用的分词策略并不相同,因此我们需要通过向 Tokenizer.from_pretrained() 函数传递模型 checkpoint 的名称来加载对应的分词器和词表。
分词与映射分别操作
下面,我们尝试使用 BERT 分词器来对文本进行分词:
- from transformers import AutoTokenizer
- tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
- sequence = "Using a Transformer network is simple"
- tokens = tokenizer.tokenize(sequence)
- print(tokens)
输出的结果如下所是。可以看到,BERT 分词器采用的是子词 (subword) 切分策略,它会不断切分词语直到获得词表中的 token,例如 “transformer” 会被切分为 “trans” 和 “##former”。
- ['Using', 'a', 'Trans', '##former', 'network', 'is', 'simple']
然后,我们通过 convert_tokens_to_ids() 将切分出的 tokens 转换为对应的 token IDs:
- ids = tokenizer.convert_tokens_to_ids(tokens)
- print(ids)
输出的结果如下所是,也就是将上面的字符转换为了 id:
- [7993, 170, 13809, 23763, 2443, 1110, 3014]
使用 encode 完成编码
我们也可以通过 encode() 函数将这两个步骤合并,并且 encode() 会自动添加模型需要的特殊字符。例如对于 BERT 会自动在 token 序列的首尾分别添加 [CLS] 和 [SEP] token:
- from transformers import AutoTokenizer
- tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
- sequence = "Using a Transformer network is simple"
- sequence_ids = tokenizer.encode(sequence)
- print(sequence_ids)
输出的结果如下所是,其中 101 和 102 分别是 [CLS] 和 [SEP] 对应的 token IDs:
- [101, 7993, 170, 13809, 23763, 2443, 1110, 3014, 102]
使用 decode 完成解码
文本解码 (Decoding) 与编码相反,负责将 token IDs 转化为原来的字符串。注意,解码过程不是简单地将 token IDs 映射回 tokens,还需要合并那些被分词器分为多个 token 的单词。下面我们尝试通过 decode() 函数解码前面生成的 token IDs:
- from transformers import AutoTokenizer
- tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
- decoded_string = tokenizer.decode([101, 7993, 170, 13809, 23763, 2443, 1110, 3014, 102])
- print(decoded_string)
最终的结果如下所是,可以看到成功将 ID 还原为 tokens。
- [CLS] Using a Transformer network is simple [SEP]
直接使用分词器处理
实际编码文本时,更为常见的是直接使用分词器进行处理。这样返回的结果中不仅包含处理后的 token IDs,还包含模型需要的其他辅助输入。例如对于 BERT 模型还会自动在输入中添加 token_type_ids 和 attention_mask:
- from transformers import AutoTokenizer
- tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
- tokenized_text = tokenizer("Using a Transformer network is simple")
- print(tokenized_text)
最终的结果如下所是:
- {
- 'input_ids': [101, 7993, 170, 13809, 23763, 2443, 1110, 3014, 102],
- 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0],
- 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]
- }
处理多段文本
在实际应用中,我们往往需要同时处理大量长度各异的文本。而且所有的神经网络模型都只接受批 (batch) 数据作为输入,即使只输入一段文本,也需要先将它组成只包含一个样本的 batch,然后才能送入模型。
使用分词器处理多个句子
同样的,我们可以直接使用「分词器」对文本进行处理。下面看一个例子,共有两句话:
- from transformers import AutoTokenizer
- # 加载分词器
- checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
- tokenizer = AutoTokenizer.from_pretrained(checkpoint)
- # 句子
- sequence = [
- "I've been waiting for a HuggingFace course my whole life.",
- "Hello, World."
- ]
- # 分词
- tokenized_inputs = tokenizer(sequence, padding=True, return_tensors="pt")
- print("Input IDs:\n", tokenized_inputs)
输出的结果为,可以看到通过 padding 使得输出长度是一样的。
- {
- 'input_ids': tensor([
- [
- 101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172,
- 2607, 2026, 2878, 2166, 1012, 102],
- [
- 101, 7592, 1010, 2088, 1012, 102, 0, 0, 0, 0,
- 0, 0, 0, 0, 0, 0
- ]
- ]),
- 'attention_mask': tensor([
- [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
- [1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
- ])
- }
这里通过 return_tensors 参数指定返回的张量格式:设为 pt 则返回 PyTorch 张量;tf 则返回 TensorFlow 张量,np 则返回 NumPy 数组。
通过 Padding 操作,在短序列的最后填充特殊的 padding token,使得 batch 中所有的序列都具有相同的长度。padding 有以下的参数来控制:
padding="longest": 将 batch 内的序列填充到当前 batch 中最长序列的长度;padding="max_length":将所有序列填充到模型能够接受的最大长度,例如 BERT 模型就是 512。
截断操作通过 truncation 参数来控制,如果 truncation=True,那么大于模型最大接受长度的序列都会被截断,例如对于 BERT 模型就会截断长度超过 512 的序列。此外,也可以通过 max_length 参数来控制截断长度:
- model_inputs = tokenizer(sequences, max_length=8, truncation=True)
Attention Masks
使用 padding 会存在一个问题,Transformer 模型会编码输入序列中的每一个 token 以建模完整的上下文。因此会将填充的 padding token 也当成是普通 token 一起编码,从而生成了不同的上下文语义表示。也就是导致加入 padding 之后的结果会和加入前是不一样的。
因此,在进行 Padding 操作的同时,我们必须明确地告诉模型哪些 token 是我们填充的,它们不应该参与编码,这就需要使用到 attention mask。
Attention masks 是一个与 input IDs 尺寸完全相同的仅由 0 和 1 组成的张量,其中 0 表示对应位置的 token 是填充符,不应该参与 attention 层的计算,而应该只基于 1 对应位置的 token 来建模上下文。
编码句子对
在上面的例子中,我们都是对单个序列进行编码(即使通过 batch 处理多段文本,也是并行地编码单个序列),而实际上对于 BERT 等包含「句子对」分类预训练任务的模型来说,都支持对「句子对」进行编码,例如:
- from transformers import AutoTokenizer
- checkpoint = "bert-base-uncased"
- tokenizer = AutoTokenizer.from_pretrained(checkpoint)
- inputs = tokenizer("This is the first sentence.", "This is the second one.")
- print(inputs)
- tokens = tokenizer.convert_ids_to_tokens(inputs["input_ids"])
- print(tokens)
输出的结果是:
- {
- 'input_ids': [101, 2023, 2003, 1996, 2034, 6251, 1012, 102, 2023, 2003, 1996, 2117, 2028, 1012, 102],
- 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1],
- 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
- }
- ['[CLS]', 'this', 'is', 'the', 'first', 'sentence', '.', '[SEP]', 'this', 'is', 'the', 'second', 'one', '.', '[SEP]']
可以看到分词器自动使用 [SEP] token 拼接了两个句子,输出形式为「[CLS] sentence1 [SEP] sentence2 [SEP]」的 token 序列,这也是 BERT 模型预期的输入格式。
返回结果中除了前面我们介绍过的 input_ids 和 attention_mask 之外,还包含了一个 token_type_ids 项,用于标记输入序列中哪些 token 属于第一个句子,哪些属于第二个句子。也就是第一个句子「[CLS] sentence1 [SEP]」的 token_type_ids 都是 0,而第二个句子 「sentence2 [SEP]」对应的 token_type_ids 都是 0。
下面是一个包含句子对和多个句子的分词器使用的例子:
- from transformers import AutoTokenizer
- checkpoint = "bert-base-uncased"
- tokenizer = AutoTokenizer.from_pretrained(checkpoint)
- sentences_list = [
- ["This is the first sentence 1.", "second sentence 1."],
- ["This is the first sentence 2.", "second sentence 2."]
- ]
- tokens = tokenizer(
- sentences_list,
- padding=True,
- truncation=True,
- return_tensors="pt"
- )
- print(tokens)
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-


评论