文章目录(Table of Contents)
简介
我们在之前的文章中,介绍了 Transformer 的结构和其在自然语言中的应用,Transformer 结构介绍,Transformer 完全图解指南。在本文中,我们会介绍 Transformer 的结构在「图像」上面的应用,也就是 Vision Transformer (ViT) 。
之前对于「图像」数据的处理,通常是使用「卷积网络(Pytorch入门教程13-卷积神经网络的CIFAR-10的识别)」,例如 ResNet。而 ViT 当在足够大的数据集上进行预训练,再迁移到特定的任务上面时,可以得到超越传统「卷积网络」的效果。同时,这篇文章也说明了纯 Transformer 结构可以在图像上获得好的结果。
参考资料
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (Paper Explained),
ViT的原始论文阅读; - Vision Transformer (ViT) 用于图片分类,一个中文视频对
ViT的介绍(本文后面的ViT流程主要是根据该视频进行描述的); - Vision Transformer in PyTorch,使用
PyTorch来实现ViT。这个视频讲的非常详细,非常推荐看一遍。该视频对应的代码仓库是,vision_transformer(这里自己实现的代码完全就是依照这个说明); - ViT 完整代码-Github;从头实现的
ViT代码,内容也是参考自 Vision Transformer in PyTorch。
Vision Transformer 介绍
ViT 的基本想法
ViT 模型其实就是 Transformer Encoder 部分。本文的出发点是,当 Transformer 的结构在「自然语言」上获得了较好的结果,是否可以将其使用在图片上。目前图像的任务还是会使用「卷积网络」,本文用纯的 Transformer 结构,在大数据集预训练下,可以获得很好的结果。
本文得到的结论是,在小的数据集上,传统的「卷积网络」,例如 ResNet 会更好,这里作者解释是因为「卷积网络」会对图片是有假设的,(1)图片相邻区域是相似的;(2)translation equivariance。但是在更大的数据集上,ViT 模型就会获得比之前方法更好的效果。
ViT 方法
ViT 模型的结构可以用下面的图来描述。本文是想与传统的 Transformer 框架尽量是一样的,这样就可以复用之前的模型框架等。
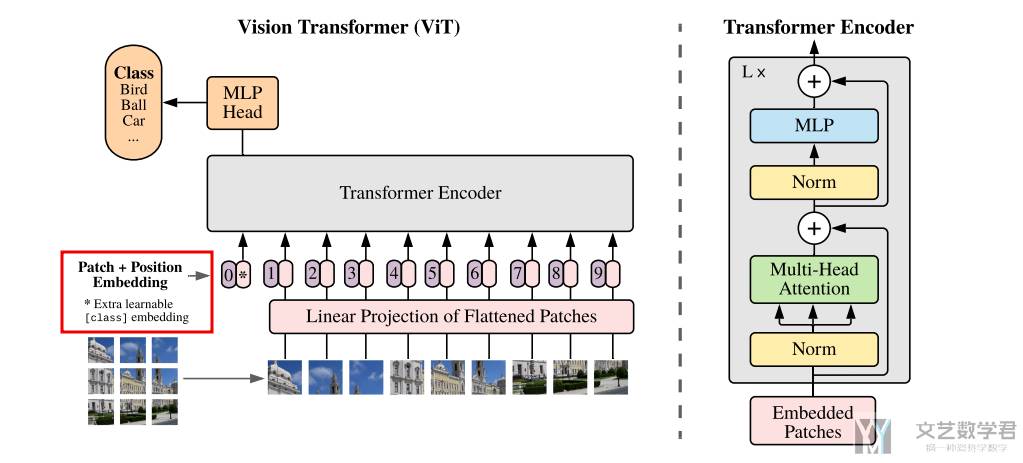
上图展示了 ViT 模型的结构。我们(1)首先将图片分成不同的小块;(2)接着通过一个线性变换,转换为向量,并加上位置信息(此时就获得了 patch embedding,这个就和 word embedding 是类似的含义);(3)后面的步骤就可以直接使用在「自然语言处理」部分的 Transformer 的结构了。
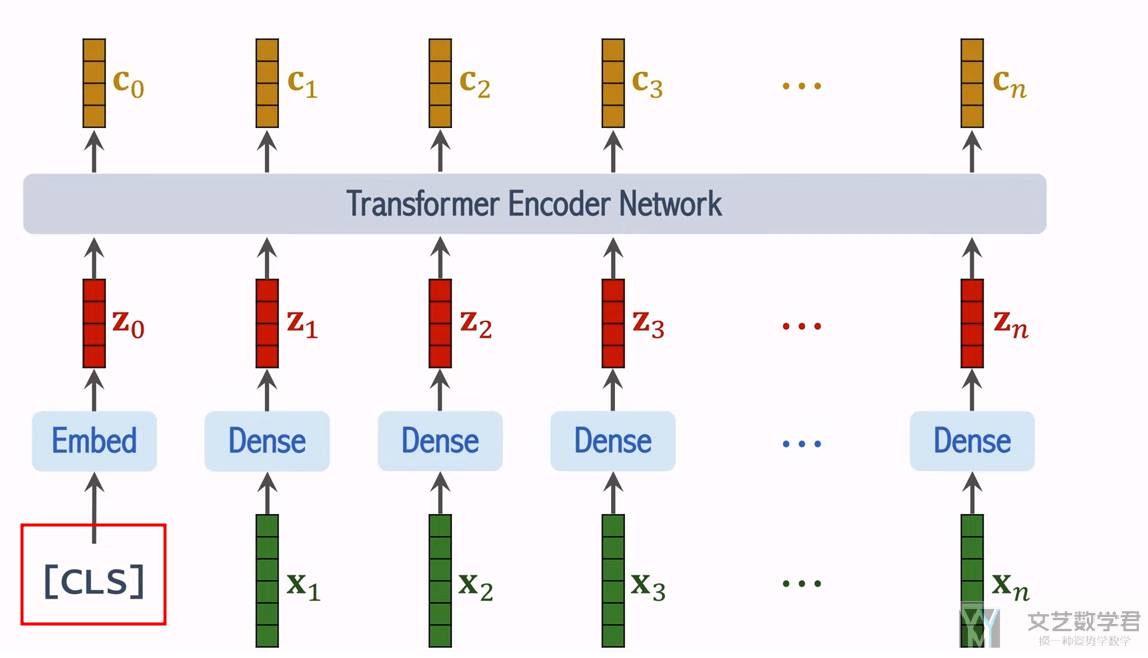
作者用下面的四个式子来说明了 ViT 模型的步骤:
- (1):有
N个patch和一个CLS token,E表示线性变化,接着再加上位置编码; - (2)和(3):这两个式子是
Transformer Encoder的部分,计算multi-head attention和MLP; - (4)最后取最后一层的第一个值,来用作分类任务;
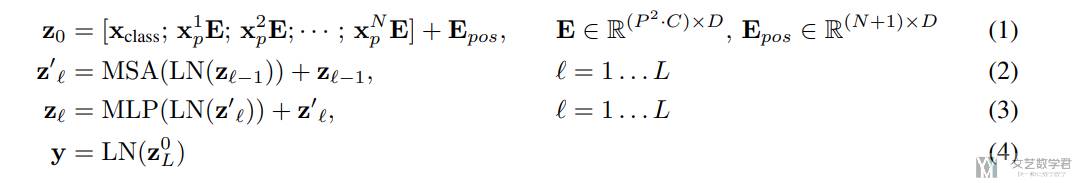
ViT 模型其实不是很复杂。下面会对「位置编码」和「CLS token」稍微做一点详细的解释。
Position Embedding
首先来看一下「位置编码」。这里的「位置编码」是可以学习的,且只记录了一维的信息。下面是「位置编码」的定义,我们会将位置编码与 x 直接相加。
- self.pos_embed = nn.Parameter(
- torch.zeros(1, 1 + self.patch_embed.n_patches, embed_dim)
- ) # 可以学习的位置编码
- x = x + self.pos_embed
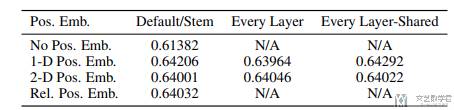
其实还会有不同的「位置编码」的设计。原文中也是进行了比较,但是发现不同「位置编码」结果是类似的。如下表所是:
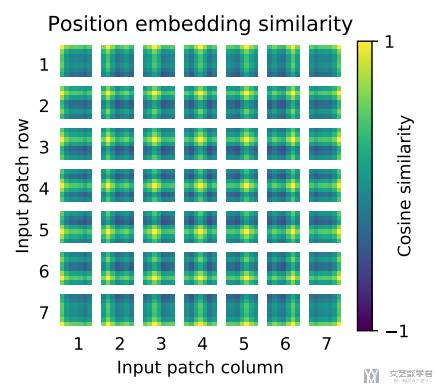
同时作者也对「位置编码」进行了可视化分析,将一个特定位置的 Position Embedding 与其他所有位置的 Position Embedding 计算「余弦相似度」,最终结果如下图。可以看到例如「第一行第一列」的 Position Embedding 与同行同列的相似度较高。这个也可以解释为什么使用不同的「位置编码」结果类似,这是因为当前的位置编码已经学出了二维的信息。
CLS Token
接着我们来解释一下为什么需要使用「CLS token」。这是因为希望「自然语言处理」部分使用的模型是对齐的,在 Bert 中也是使用了 「CLS token」。
作者也是尝试了与图像处理中经常使用的「globally average-pooling (GAP)」进行比较,结果表明只需要适当的对学习率进行调整,使用 GAP 也是可以获得好的结果。这里因为想尽量少的改变原始的 Transformer 框架,所以使用了 CLS token。
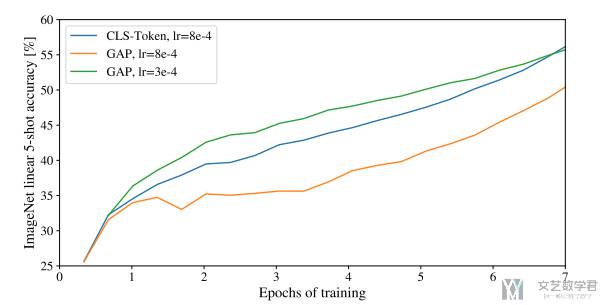
ViT 实验结果
ViT 在三个不同大小的数据集上进行了实验。
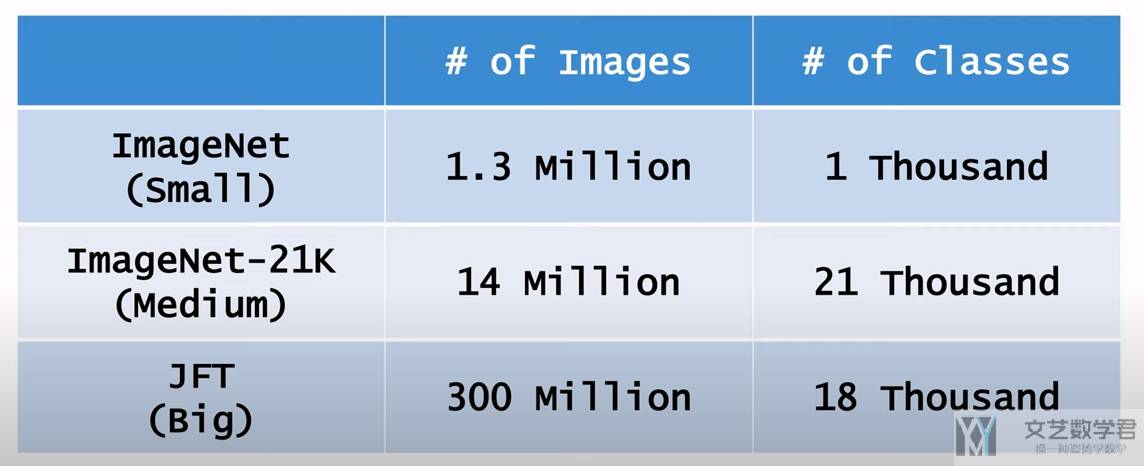
下面是一个实验结果的概括。简单来说,在大数据集上预训练,ViT 可以获得更好的结果:
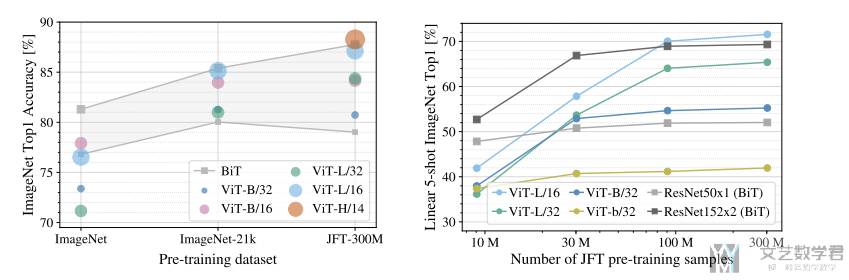
下面来看一下不同模型性能随着数据量的变化具体的变化。如下图所是,可以看到随着 pre-training samples 数量的增大,ViT 的效果是可以一直上升的。有以下的结论:
- While large ViT models perform worse than BiT ResNets (shaded area) when pre-trained on small datasets, they shine when pre-trained on larger datasets. Similarly, larger ViT variants overtake smaller ones as the dataset grows.
- Linear few-shot evaluation on ImageNet versus pre-training size. ResNets perform better with smaller pre-training datasets but plateau sooner than ViT, which performs better with larger pre-training.(这里 Linear few-shot evaluation 是指用对应模型作为特征提取器,参数不变,后面接一个全连接的效果)
其实下面的图也是给出了一个说明,大概多大的数据量使用什么样子的模型。当小于 100M 的时候,ResNet 表现会更好。当大于 300M 的时候,ViT 表现会更好,ResNet 就每什么提升了。
ViT 核心代码
下面简单看一下 ViT 的代码,完整的代码可以查看链接,ViT 完整代码-Github。这里主要看两个部分(1)将图片分割为 patches 的实现,转换为 patch embedding;(2)完整的 ViT 的数据流程。
首先我们来看一下如何生成 patch embedding。这里我们使用了一个「卷积」来将图片划分为patches,并将其转换为向量:
- class PatchEmbed(nn.Module):
- """Split image into patches and then embed them.
- 这个部分可以说是 ViT 全文最重要的创新点了.
- """
- def __init__(self, img_size, patch_size, in_chans=3, embed_dim=768):
- super().__init__()
- self.img_size = img_size
- self.patch_size = patch_size
- self.n_patches = (img_size // patch_size) ** 2
- self.proj = nn.Conv2d(
- in_chans,
- embed_dim,
- kernel_size=patch_size,
- stride=patch_size,
- ) # 此时 kernel_size 和 stride 与 patch_size 是一样的
- def forward(self, x):
- x = self.proj(
- x
- ) # (n_samples, embed_dim, n_patches ** 0.5, n_patches ** 0.5)
- x = x.flatten(2) # (n_samples, embed_dim, n_patches)
- x = x.transpose(1, 2) # (n_samples, n_patches, embed_dim)
- return x
接着看一下完整的 ViT 的数据流程。如下所是,我们对每一行都加上了注释,方便理解:
- # 得到 patch embedding
- x = self.patch_embed(x) # 将 image 按照 patch 进行划分
- # 初始化 cls token
- cls_token = self.cls_token.expand(
- n_samples, -1, -1
- ) # (n_samples, 1, embed_dim), 将 cls_token 重复 batch_size 次
- # 将 cls token 与 patch embedding 结果合并
- x = torch.cat((cls_token, x), dim=1) # (n_samples, 1 + n_patches, embed_dim)
- # 加上位置信息
- x = x + self.pos_embed # (n_samples, 1 + n_patches, embed_dim)
- x = self.pos_drop(x)
- # 进入 multi-head attention
- for block in self.blocks:
- x = block(x)
- x = self.norm(x)
- # 获取输出的第一个向量
- cls_token_final = x[:, 0] # **just the CLS token**
- # 使用该向量进行分类
- x = self.head(cls_token_final)
ViT 完整流程
上面我们介绍了 ViT 的基本想法,和论文里面的实验结果。这里我们再完整过一遍 ViT 的整体流程。从而让我们对 ViT 有个整体上面的理解。这部分的内容来自,Vision Transformer (ViT) 用于图片分类,对视频内容进行了简化,推荐查看原始视频。
Split Image into Patches
ViT 会将图片划分为大小相同的 patches。例如在下面的例子中,图片被划分成了 9 个 patches。在 ViT 原文中,patches 是没有重叠的,但我们也可以使得 patches 是重叠的。

Vectorization
上面将图片分割为若干个 patches 之后,每个 patches 其实就是一个张量,下面我们将其转换为向量,也就是把「张量」拉伸为「一维向量」。
如下图所是,我们将上面得到的 9 个 patches 转换为 9 个向量。例如原始每个 patches 的大小是 (d1, d2, d3),那么转换后的向量就是 (1, d1×d2×d3)。

Multi-head Attention
到上面将 patches 转换为「向量」,就和自然语言是一样了,相当于每一个 patches 就是一个词汇。因此后面的内容其实是和 Transformer 是一样的。我们在这里进行简单的介绍,详细的内容可以参考 Transformer 完全图解指南。
如下所是,我们将上面得到的每个 patches 的向量计算 multi-head attention,这里可以保证「输入」和「输出」的大小是一样的(因为有残差连接)。需要注意的是,我们额外加入了一个 CLS token,他相当于是存储整个图片的信息:
在最后的特定任务中,我们只会使用向量「c0」,这个相当于是从图像中提取的特征向量。通常会在 「c0」后面接一个「全连接层」和「Softmax」,就可以来完成分类任务。
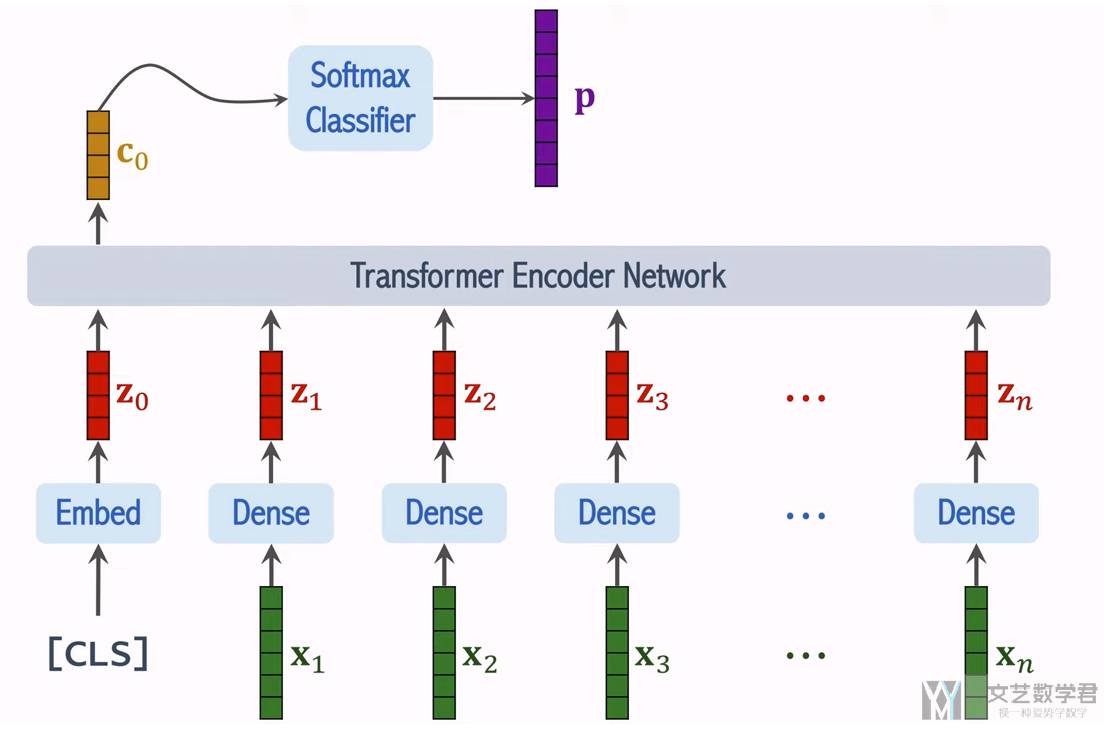
ViT 的训练步骤
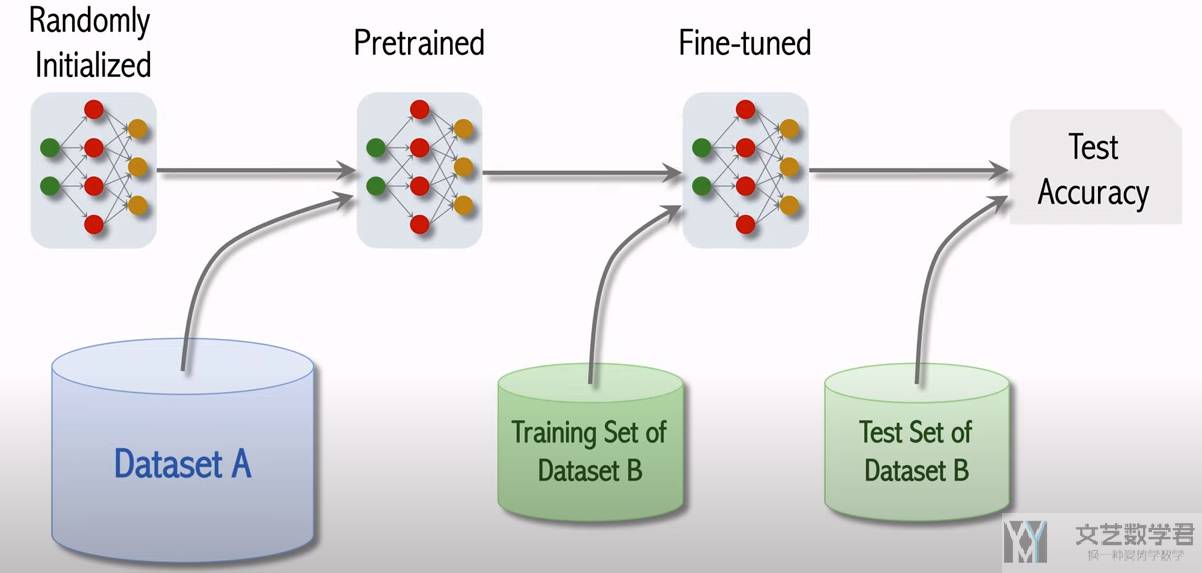
通常 ViT 模型的训练步骤如下所是:
- 首先在「数据集 A」上进行预训练(pretrained),「数据集 A」的规模要比较大;
- 接着在「数据集 B」上接着训练,通常「数据集 B」是特定任务的数据集,会比较小。这一步叫做微调(fine-tuned);
- 最后在「数据集 B」的测试集上评价模型的表现,得到测试准确率;
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-



评论