文章目录(Table of Contents)
简介
在前面的内容中,我们了解了自注意力和位置编码,注意力分数,多头注意力。在有了所有这些知识之后,我们就可以开始学习「Transformer 的结构」了。
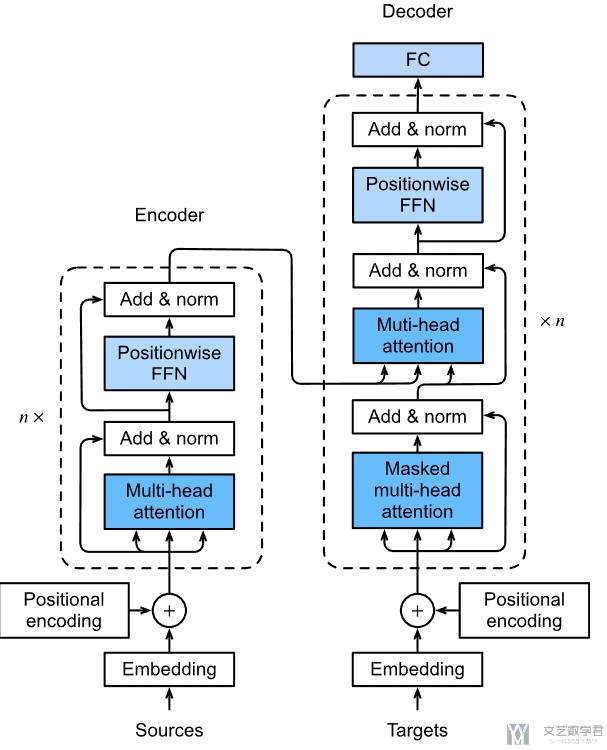
与 Seq2Seq 一样,Transformer 仍然是使用 Encoder 和 Decoder 的结构;但是与 Seq2Seq 不一样的是,这里不使用 RNN 的架构,而是全部使用 Attention 的结构;下图展示了「Transformer 的结构」,下文会对其进行详细的分析。
参考资料
- 11.7. The Transformer Architecture,Dive into deep learning 中关于 Transformer 的介绍;
- Transformer,D2L 关于 Transformer 的介绍(中文版);
- B 站 D2L Transformer 视频,上面 D2L 对应的 B站视频教学;
- Attention-mechanisms-and-transformers,本文对应的代码,transformer 文件名;
Encoder 部分解释
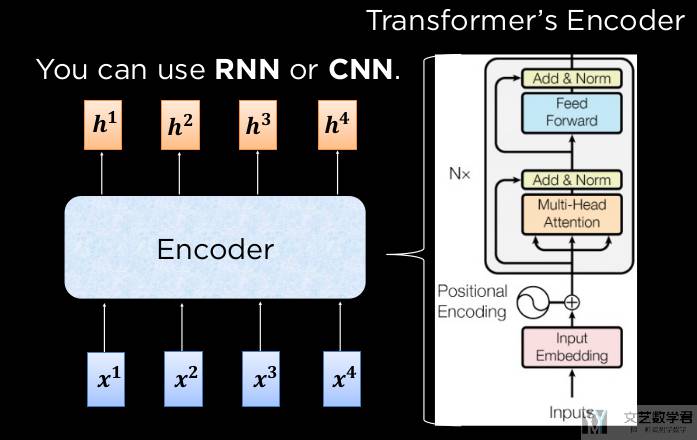
首先我们对 Transformer 的 Encoder 的部分进行说明。Encoder 部分总体来说如下所是:
Positionwise Feed-Forward Networks
该层在本质上就是一个全连接层。原本的输入大小为 (batch size, sequence length, feature dimension),在经过两层的全连接层之后,输出的大小会转换为 (batch size, sequence length, ffn_num_outputs)。只有最后一个维度发生了变化,相当于对每个字的信息进行转换。于是我们可以写出下面的代码:
- class PositionWiseFFN(nn.Module):
- """Positionwise feed-forward network.
- 输入是三维, 只对最后一维度作处理.
- """
- def __init__(self, ffn_num_hiddens, ffn_num_outputs):
- super().__init__()
- self.dense1 = nn.LazyLinear(ffn_num_hiddens)
- self.relu = nn.ReLU()
- self.dense2 = nn.LazyLinear(ffn_num_outputs)
- def forward(self, X):
- return self.dense2(self.relu(self.dense1(X)))
我们实际跑一个例子,下面 input_x 的大小是 (2,3,4),经过 Positionwise Feed-Forward Networks 之后输出的大小为 (2,3,8)。
- ffn = PositionWiseFFN(4, 8) # 将 feature dimension 转换为 8
- ffn.eval()
- input_x = torch.ones((2, 3, 4))
- output_x = ffn(input_x)
- print(f'Input Shape, {input_x.shape}; \nOutput Shape, {output_x.shape};')
- """
- Input Shape, torch.Size([2, 3, 4]);
- Output Shape, torch.Size([2, 3, 8]);
- """
Batch Norm 和 Layer Norm 介绍
因为在 Transformer 中会用到 Layer Norm 的相关内容,故我们在这里做一个简单的介绍。
Batch Norm是将每个特征(一列),变为均值为 0,方差为 1;Layer Norm是将每个样本,变为均值为 0,方差为 1。相当于是对特征进行标准化;
下面看一个具体的数值例子。
- ln = nn.LayerNorm(2)
- bn = nn.LazyBatchNorm1d()
- X = torch.tensor([[1, 2], [2, 3]], dtype=torch.float32)
- # Compute mean and variance from X in the training mode
- print('layer norm:', ln(X), '\nbatch norm:', bn(X))
- """
- layer norm: tensor([[-1.0000, 1.0000],
- [-1.0000, 1.0000]], grad_fn=<NativeLayerNormBackward0>)
- batch norm: tensor([[-1.0000, -1.0000],
- [ 1.0000, 1.0000]], grad_fn=<NativeBatchNormBackward0>)
- """
可以看到使用 Layer Norm 则一个样本的均值是 0,而使用 Batch Norm 则是一个特征的均值为 0,也就是一列。
AddNorm 介绍
下面定义 Transformer 用到的 Add&Norm,其实就是包括一个「残差」和一个「Layer Norm」。代码如下所是:
- class AddNorm(nn.Module):
- """Residual connection followed by layer normalization."""
- def __init__(self, norm_shape, dropout):
- super().__init__()
- self.dropout = nn.Dropout(dropout)
- self.ln = nn.LayerNorm(norm_shape)
- def forward(self, X, Y):
- """_summary_
- Args:
- X (_type_): 原始的输入
- Y (_type_): Y 是 f(X) 的结果, 这里我们加一个 dropout
- """
- return self.ln(self.dropout(Y) + X)
我们重点看上面的 forward 部分,其中 Y是经过别的层输出的,X 是原始的,我们将其相加(相当于是残差)。最后用一个实际的例子,可以看到 Add&Norm 是可以保持输入的形状的:
- # AddNorm 是不会改变「输入」和「输出」的形状。
- add_norm = AddNorm(4, 0.5)
- output_x = add_norm(torch.ones((2, 3, 4)), torch.ones((2, 3, 4)))
- print(f'Output Shape, {output_x.shape}')
- # Output Shape, torch.Size([2, 3, 4])
Encoder Block 介绍
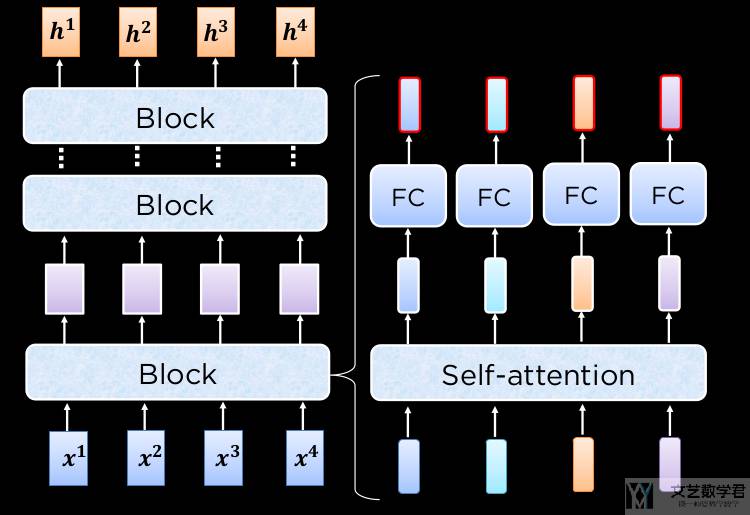
有了上面知识点的铺垫,我们就可以开始介绍 Encoder Block 了。他的整个数据流向是「Multi-head Attention --> AddNorm --> FFN --> AddNorm」。
下图简单展示了上面所说的数据流向。
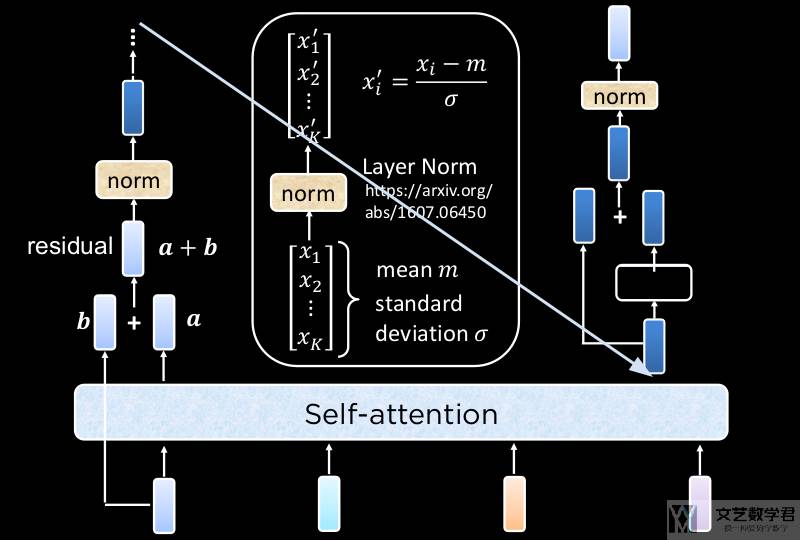
对于右侧的部分,下图对其进行了详细的说明。(1)首先经过了 Multi-head Attention得到了 b;(2)然后经过 AddNorm,也就是 norm(a+b);(3)接着是FFN;(4)最后对 FFN 输出的结果进行 AddNorm;
于是我们根据上面的思路,可以写出下面的 Encoder Block 的代码,可以自行查看 forward 部分的代码,与上面的流程是一样的:
- class TransformerEncoderBlock(nn.Module):
- """Transformer encoder block."""
- def __init__(self, num_hiddens, ffn_num_hiddens, num_heads, dropout, use_bias=False):
- super().__init__()
- self.attention = MultiHeadAttention(num_hiddens, num_heads, dropout, use_bias)
- self.addnorm1 = AddNorm(num_hiddens, dropout)
- self.ffn = PositionWiseFFN(ffn_num_hiddens, num_hiddens)
- self.addnorm2 = AddNorm(num_hiddens, dropout)
- def forward(self, X, valid_lens):
- # 计算 self attention 就是 query, key, value 都是 X
- self_ttention_result = self.attention(X, X, X, valid_lens) # self attention
- Y = self.addnorm1(X, self_ttention_result) # 残差
- return self.addnorm2(Y, self.ffn(Y))
我们还是找一组实际的数据来进行测试。
- encoder_blk = TransformerEncoderBlock(
- num_hiddens=24, ffn_num_hiddens=48,
- num_heads=8, dropout=0.5
- )
- encoder_blk.eval()
- X = torch.ones((2, 100, 24))
- valid_lens = torch.tensor([3, 2])
- Y = encoder_blk(X, valid_lens)
- print(f'Output Shape, {Y.shape}')
- # Output Shape, torch.Size([2, 100, 24])
可以看到输入和输出的大小是一样的,都是 (2, 100, 24)。这里输出和输出的大小一定是一样的,因为我们使用了 AddNorm,只有维度一样,才可以进行相加。
Transformer Encoder
最后将若干个 Encoder Block 叠加,就得到了 Transformer Encoder。需要注意的是,对于输入部分,我们需要对输入文字进行 「embedding」 和加上「位置编码」,也就是下面 forward 中的第一行。
- class TransformerEncoder(Encoder):
- """Transformer encoder."""
- def __init__(self, vocab_size, num_hiddens, ffn_num_hiddens,
- num_heads, num_blks, dropout, use_bias=False):
- super().__init__()
- self.num_hiddens = num_hiddens
- self.embedding = nn.Embedding(vocab_size, num_hiddens)
- self.pos_encoding = PositionalEncoding(num_hiddens, dropout)
- # 加上多个 block 的数据
- self.blks = nn.Sequential()
- for i in range(num_blks):
- self.blks.add_module(
- "block"+str(i),
- TransformerEncoderBlock(num_hiddens, ffn_num_hiddens, num_heads, dropout, use_bias)
- )
- def forward(self, X, valid_lens):
- # Since positional encoding values are between -1 and 1,
- # the embedding values are multiplied by the square root of the embedding dimension to rescale before they are summed up
- # 使得 embedding 的结果的值和 position embedding 的值差不多大
- X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens))
- self.attention_weights = [None] * len(self.blks)
- for i, blk in enumerate(self.blks):
- X = blk(X, valid_lens)
- self.attention_weights[i] = blk.attention.attention.attention_weights
- return X
需要注意,整个 Transformer Encoder 也是不会改变数据的大小,只会改变最后一个维度。例如下面的例子中,我们输入的大小是 (2, 100),输出的大小是 (2, 100, 24),相当于是每个字有 24 维度的特征大小。
- encoder = TransformerEncoder(200, 24, 48, 8, 2, 0.5)
- X = torch.ones((2, 100), dtype=torch.long)
- valid_lens = torch.tensor([3, 2])
- Y = encoder(X, valid_lens)
- print(f'Output Shape, {Y.shape}') # 最后每个字多一个 24 维度的输出
- # Output Shape, torch.Size([2, 100, 24])
Decoder 部分解释
Mask Self-Attention
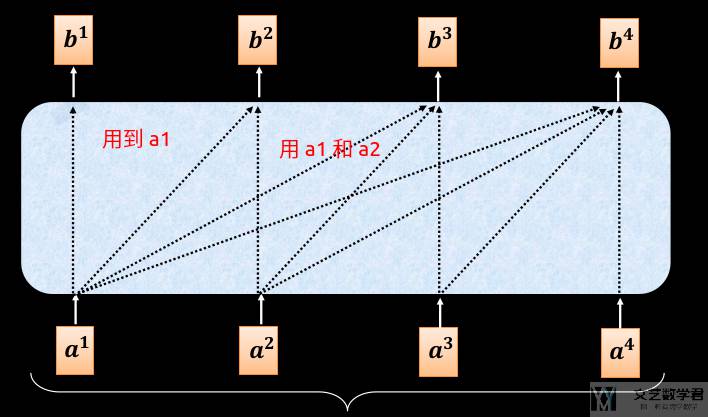
在 Decoder 部分,我们不能像在 Encoder 的时候一样,看到全部的输入,因此我们每次计算 attention 的时候,需要遮住一部分。
如下图所是,计算「b1」的时候只能使用「a1」;计算「b2」的时候,使用了「a1和 a2」;计算「b3」的时候,使用了「a1,a2 和 a3」;计算「b4」的时候,使用了「a1,a2 ,a3 和 a4」;
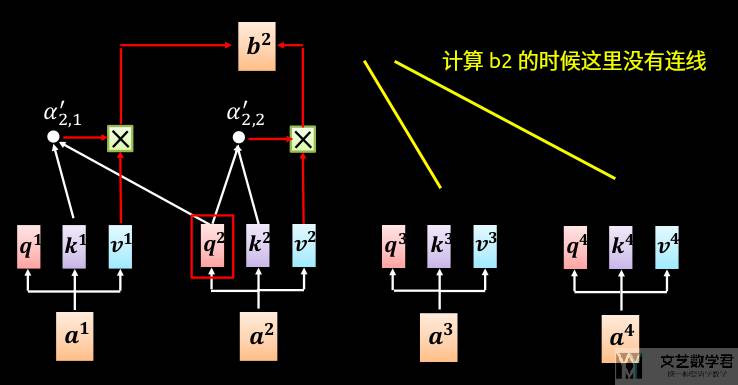
例如计算「b2」的时候,由于只使用了「a1和 a2」,因此此时的计算流程如下所是:
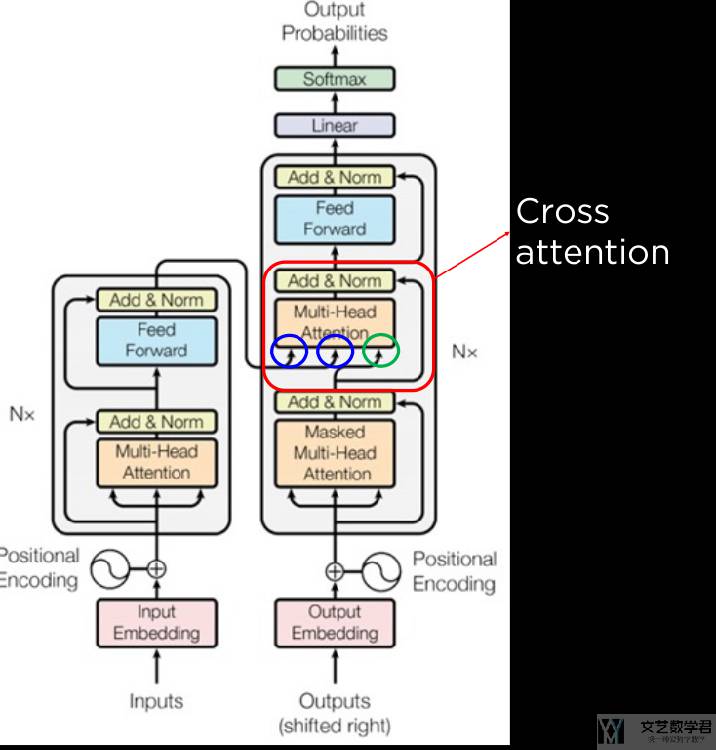
Cross Attention
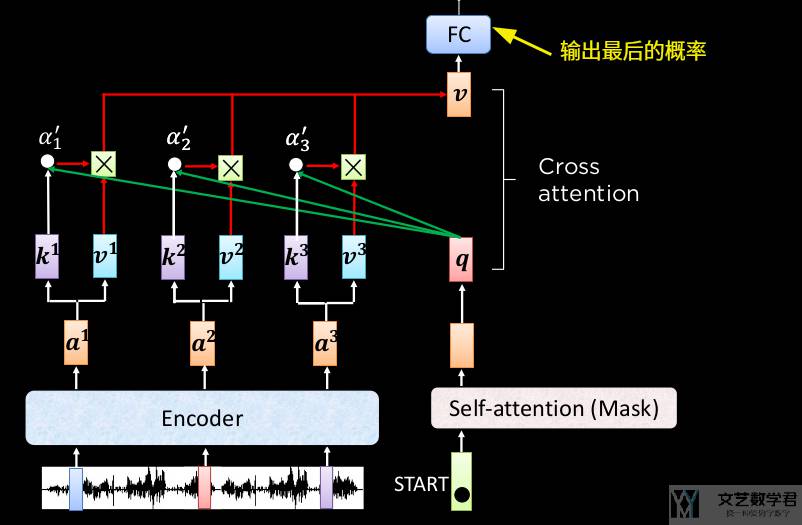
在 Deocder Block 中,包含两个 Multi-head Attention,其中第一个是 Self-Attention,这个与前面介绍的一样。第二个是 Cross Attention,他的 key-value 是来自 Encoder 的。Cross Attention如下所是:
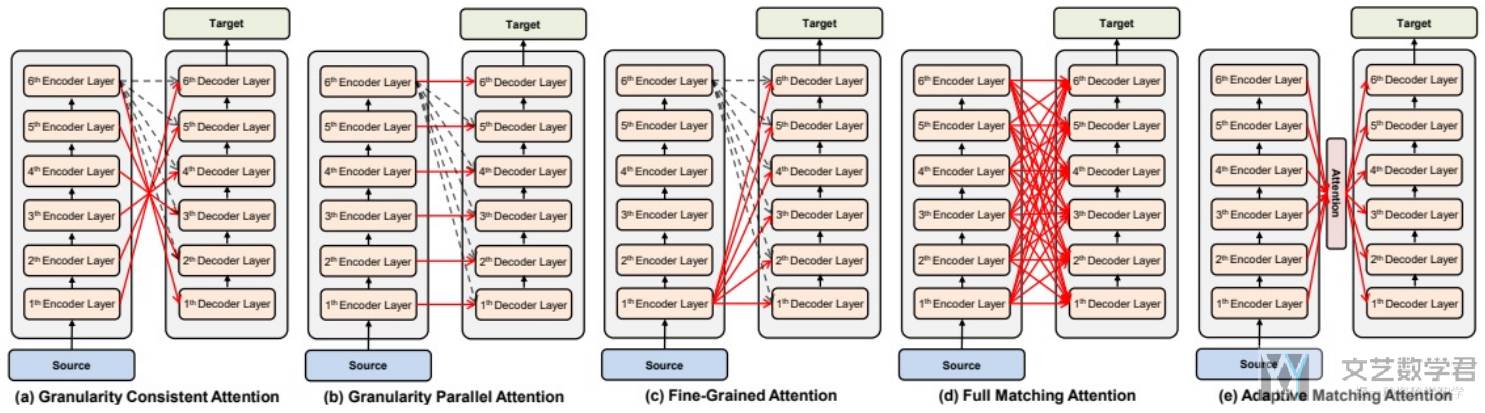
因为有多层的 Encoder Layer 和 Decoder Layer,因此 Cross Attention 可以有不同的形式,也就是不同层之间如何进行 Cross Attention。下图进行了简单的概括:
下图举了一个例子来说明 Cross Attention 是如何进行计算的。我们将 q 与 Encoder 的输出计算「注意力分数」,并得到 v,最后将 v 通过全连接层,来输出最终的概率即可:
关于 Transformer Decoder 部分的代码与 Encoder 部分是类似的,因此我们就不写在这里了。完整的代码可以查看 Attention-mechanisms-and-transformers。里面涉及了比较多的对数据的处理,例如如何处理 mask 等,可以详细去看一下代码。
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-









评论