文章目录(Table of Contents)
简介
在 Haomo 8th AI Day,毫末智行发布了首个应用 GPT 模型和技术逻辑的自动驾驶算法模型DriveGPT,并正式官宣中文名为「雪湖·海若」。DriveGPT 使用 Drive Language 对自动驾驶车辆进行规划和推理(不直接使用自然语言描述场景,会有偏差。于是构建了更加严谨的 Drive Language)。本文会介绍 DriverGPT,和对于的 Drive Language。最后简单看一下目前公布的功能。
参考资料
- DriveGPT 技术讲解,HAOMO 对 DriveGPT 的介绍;
- HAOMO 的 Github 仓库主页;
- DriveGPT 功能体验;DriveGPT 的试用接口;
- 毫末大模型 DriveGPT 试用,试用 DriverGPT 的介绍(目前开放的感觉是物体检测的功能);
- DriveGPT,根据技术大会的内容做的总结(本文也是主要基于这篇文章来写的);
- 毫末的Drive GPT是什么?蹭热点还是真有料?
自动驾驶车辆规划
自动驾驶汽车的核心软件组件是感知、规划和控制。 规划是指在给定一个场景或一系列场景的情况下生成行动计划的过程,供自动驾驶车辆遵循以实现安全和期望的自动驾驶。
用于规划的场景是从感知软件组件获得的。 计划的动作将由控制软件组件执行。
规划还可以进一步分为三类,任务规划、行为规划和局部规划。
- 任务规划是旅程的最高级别规划。它决定采取哪条路线到达目的地。比如我们常用的导航谷歌地图就属于这一类。(这个类似于路径规划)
- 行为规划是中层规划,决定在给定的实时动态场景中采取哪些高层操作。它决定车辆是否应该变换车道、加速、减速、转弯、停止等。
- 局部规划是低级规划,以平稳、安全的方式实现行为规划。行为规划和局部规划之间的界限有时是模糊的。
DriveGPT 专注于行为规划和本地规划(也就是后面两种规划方式)。
目前行业存在的问题
现在自动驾驶的技术难点在于层出不穷的长尾难题(Corner case)。背后原因是,目前系统在认知各类驾驶场景时,主要靠的还是人工写规则。
有多少特殊场景,就用多少规则来约束,但始终无法穷其尽。为了解决这个问题,业内一直在探索「实现端到端的自动驾驶」——感知数据输入、规划决策数据输出,靠神经网络来解决。
DriveGPT 的基础了解
类比自然语言,是知道前面几个文字,预测后面。在自动驾驶场景是知道前面 10s 的场景(输入),生成下一个时刻的驾驶环境(输出)。
于是 DriveGPT 可以解决下面的三个问题:
- 生成很多个宏观的环境(可以按概率生成很多个这样的场景序列,每个场景都是一个全局的场景,每个场景序列都是未来有可能发生的一种实际情况。);
- 在每一个环境中,要生成自车的轨迹(在所有场景序列都产生的情况下,能把场景中最关注的自车行为轨迹给量化出来,也就是生成场景的同时,便会产生自车未来的轨迹信息。);
- 可以生成思考链,给出推荐的理由(解决黑盒问题,有了这段轨迹之后,毫末希望这条轨迹是可解释的,而GPT模型最擅长的领域便是对话和推理,DriveGPT在生成场景序列、轨迹的同时,也会把整个决策逻辑链给输出);
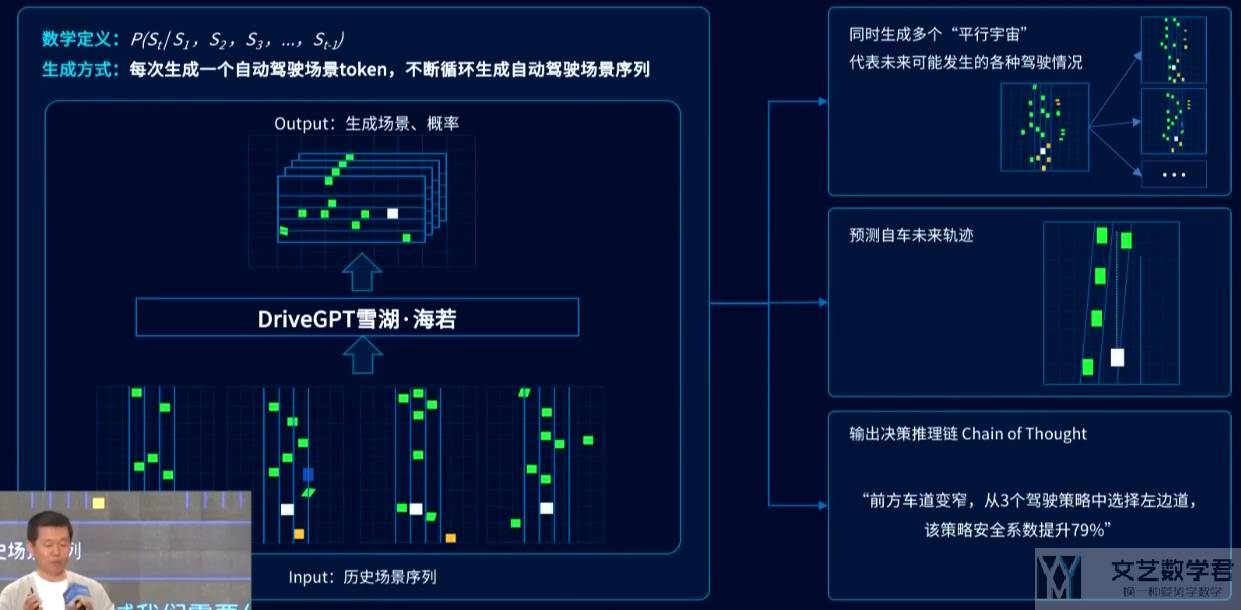
Drive Language
自然语言的单字作为 Token 输入,基于联合概率分布预测下面一个字。如果驾驶模型要使用,就需要设计自己的 Drive Language(驾驶语言)。
Drive Language 是描述驾驶实例(driving instance)的语言,可以理解为描述当前的驾驶状态(包含当前的环境和驾驶员的动作)。一个驾驶实例可以使用一个或多个 Drive sentence 来描述,每个 Drive sentence 包含多个 Drive tokens。
Drive Language Token
因为坐标等可以被量化,所以我们可以对感知结果,例如对象的坐标,对象的大小,车道坐标,自车的轨迹坐标进行量化。根据量化的方式,所需要的 drive token 可以是不同的。
例如我们想用一个 token 表示 2D 物体的坐标,那么在 2D BEV(Bird's Eye View, 鸟瞰图)空间内 token 的数量需要很多。如果我们可以使用两个 token 分别描述 2D 对象的 x 和 y 坐标,则所需的 token 数量可以显着减少(类似网格,输出网格的坐标)。
一旦一个场景中的感知信号被标记化,它们就可以用于描述场景。 例如,在一个简单的环境中,如果在有三辆车在特定的位置,x1,x2,x2,有四个车道分别在 y1,y2,y3,y4,自动驾驶车辆位置在 z1,那么 Drive sentence 可能是 Token_x1, Token_x2, ..., Token_z1。
我们也可以使用 Drive sentence 描述一系列的场景,或是自动驾驶车辆的行为。

一系列场景和自动驾驶汽车行为可能涉及人类意图或一系列人类意图,例如改变车道和超越邻居汽车。 这些人类意图也可以使用 token 或是 a sequence of token 来描述。 根据 token 工程,人类意图 token(human intention tokens)可以是来自人类自然语言的 token 或专用 token。 这样,Drive language 中的一系列场景描述也可能伴随着人类意图(也就是 Drive language 不仅包含场景描述,还包含驾驶员的描述)。
按照我的理解,这里 drive token 应该包含(交通场景和人类的动作)。目前中文是 5w 个 token,HAOMO Drive Language 是 50w 个 token(这个可以优化的少一些),可能是包含一些交通场景的描述。
Drive Language Model
因为自动驾驶制造商拥有大量的人类驾驶数据,即场景序列,而场景通常都都有标签(进行了很好的注释),会包含「感知信号标签」、「自驾车的行为」和「人类意图」的注释。在将这些数据标记化之后(after tokenizing those scenes),后端的 Drive language,基于人类驾驶逻辑,可以使用 Drive language model 来学习。
因为 Drive language model 与其他自然语言处理模型一样,是一个生成模型,它可以根据之前的标记化场景和自驾车的行为序列生成未来的场景序列和自驾汽车行为。
另外,前面提到的「人类意图标注」就是自然语言模型的提示。 在使用足够量的标记化场景、自驾汽车行为和人类意图训练 Drive language model 后,给定人类意图提示,Drive language model 可以遵循人类意图并生成未来场景和自驾车的轨迹。类似于它从训练数据中学习到的内容。 这类似于 OpenAI InstructGPT 和 ChatGPT,它们可以按照提示中的人类指令并生成所需的内容。
DriveGPT 训练细节
在 Drive language model 的选择上,正如 Haomo 首席执行官提到的,他们之前使用的是 Transformer Encoder-Decoder 的架构,但现在他们已经完全切换到著名的 OpenAI GPT 模型所使用的 Transformer 仅Decoder 的架构(可以参考, 为什么现在的LLM都是Decoder-only的架构?)。 他们将其仅 Transformer 解码器架构的 Drive 语言模型命名为 DriveGPT。
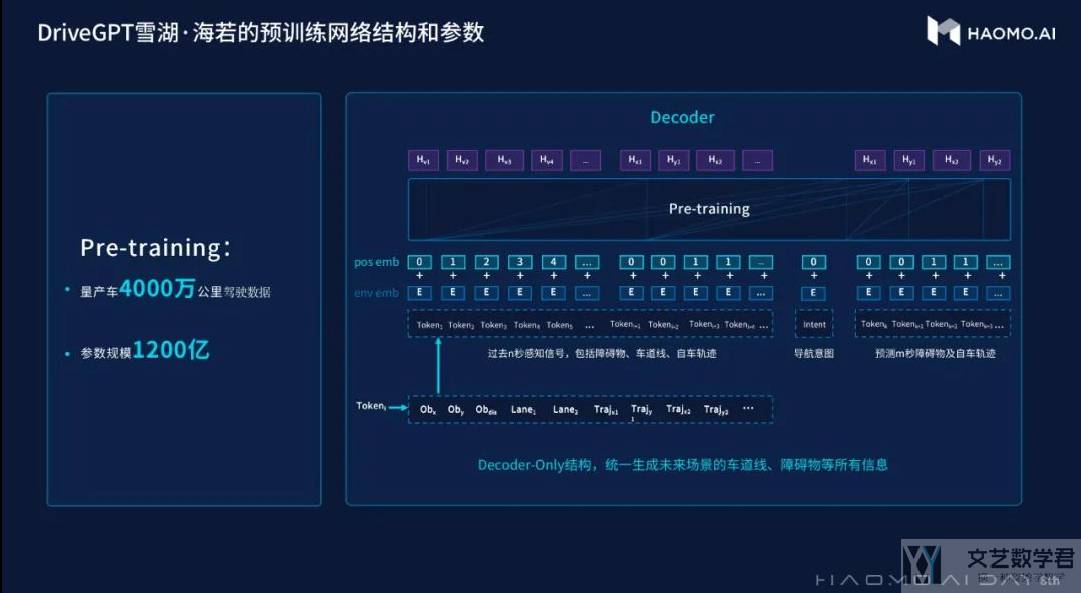
在上图中,Haomo 使用之前的「标记化场景」、「自驾汽车行为」和「人类意图」来预训练 DriveGPT,以预测未来自驾汽车行为。 但在实践中,人们还可以预训练 DriveGPT,不仅可以预测未来的标记化自驾汽车行为,还可以预测未来的标记化场景。 这样,DriveGPT就可以生成无限多个Drive实例,HAOMO 将其称为 Drive 平行宇宙。
加入人类的反馈
与 OpenAI InstructGPT 和 ChatGPT 类似,DriveGPT 训练也可以在循环中获得人类反馈。它使用人类对「未来场景」和「自驾汽车行为」的质量和安全性进行排名的数据创建奖励模型,并使用强化学习和奖励模型进一步微调预训练的 DriveGPT。
人类反馈循环奖励模型不仅使用普通人类驾驶或自动驾驶数据进行训练,还使用通常来自非常难以驾驶的场景的涉及人类参与的自动驾驶数据。
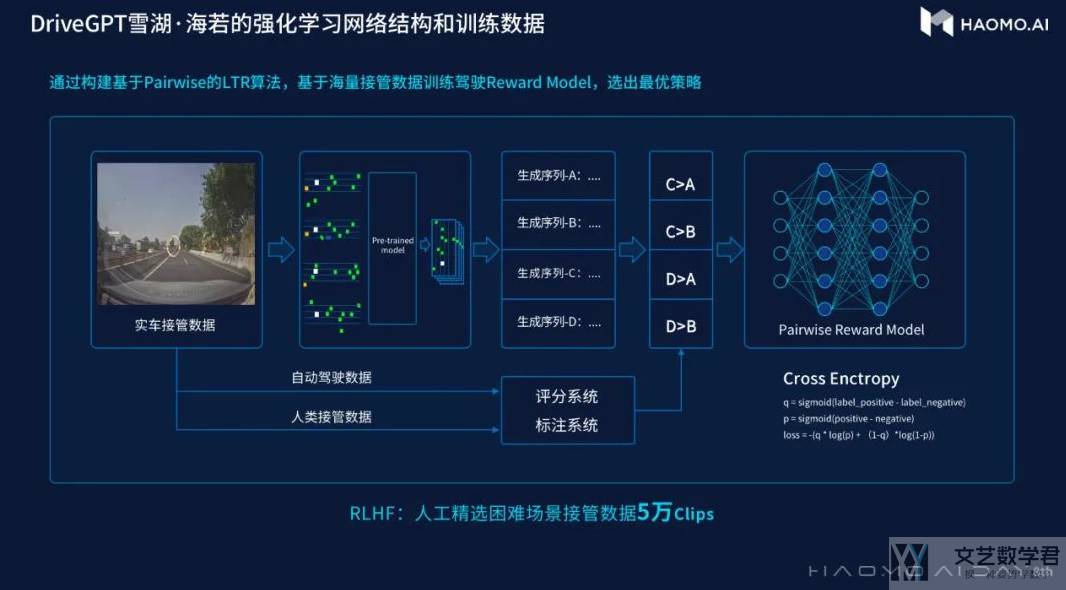
于是在有了预训练的模型之后,挑选了 5W Clip 的人驾数据,这些数据里面有一些是人类接管的,一部分是按照机器的决策执行。那么我们可以认为,(1)接管了就是人类对决策不满意;(2)没有接管就是人类对决策满意;
于是我们利用 DriveGPT 根据之前人类接管之前的标记化场景和自驾汽车行为,可以在未来生成许多标记化场景和自驾汽车行为。我们可以认为使用 DriveGPT 生成的结果没有人类的数据好,从而有了 rank,于是可以训练 reward model。
逻辑思考链条
出于安全目的,规划的推理非常重要。神经网络通常是黑匣子。 对于非安全应用,我们通常不关心它们是否是黑匣子。 然而,对于使用神经网络进行规划和决策的安全应用来说,了解「神经网络实际上在想什么」是非常有必要的。
如果存在用一系列场景的人类意图提示注释的标记化思想链,给定一系列标记化场景和自我驾车行为,该模型还可以学习生成标记化思想链,使 DriveGPT 规划“不再是一个黑盒子”。 然而,我认为人们可能仍然认为它仍然是一个黑匣子,因为思想链生成过程仍然在神经网络中。只是神经网络生成的内容似乎是人类可以解释的。

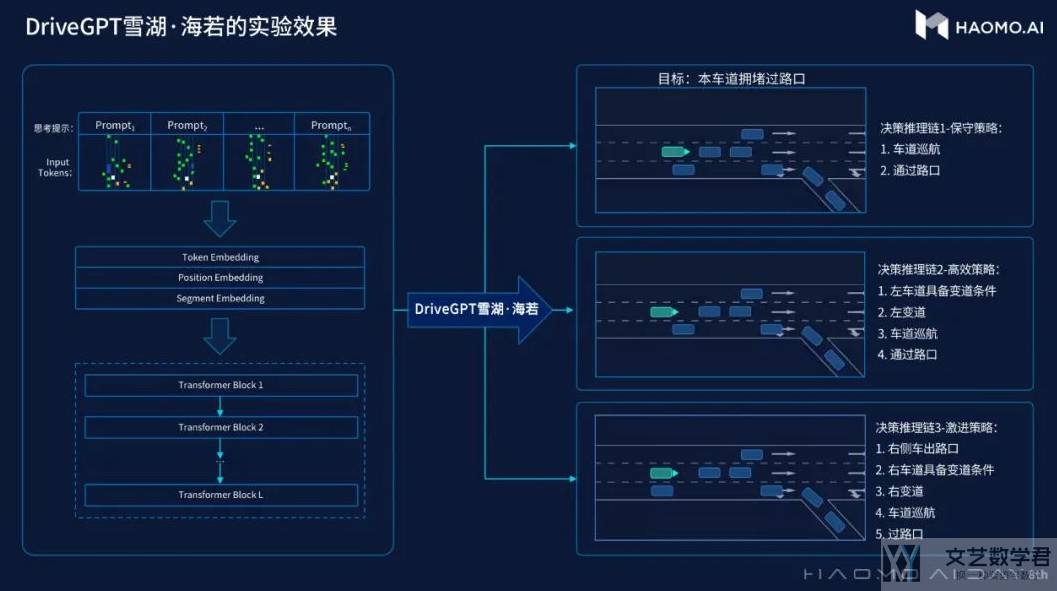
上面的图片解释了如何给出思考链条。比如左边视频是一个连续超车变道后抵达终点的例子。首先会对这段数据做细粒度的场景识别,把完整的超车决策逻辑,拆解为「直行-被压速-左变道-再直行-再右变道超车」等多个子过程。
其次,把带有 prompt 提示语和完整决策过程的样本交给模型去学习,那模型就能学到一种推理关系,即「要快速抵达路口目标处」,需要「先直行,后左右变道超车,再加速直行」,模型通过大量含有决策逻辑链的样本,就能产生一种推理能力。
下次遇到一个新的指示,例如:「慢点抵达地图上500m处目标点」,它就会生成很多比较「慢」的决策逻辑,有的是「减速跟车」,有的是「路口让行」,开得会稳重一点。那如果你换个 prompt 提示语,比如让它快一点,它又会重新生成一些「快」的逻辑。
给定之前的标记化场景、自驾汽车行为和人类意图提示,DriveGPT 可以生成未来的标记化场景和自驾汽车行为。例如下图右侧,有「保守策略」、「高效策略」。DriveGPT 可以根据用户的输入来生成不同的场景。
DriverGPT 试用
试用感受
目前 HAOMO 开放了 DriveGPT 的接口来供大家来使用。只需要进入 DriveGPT 功能体验 登陆即可。现在开放的功能是场景识别,输入照片,输出是识别到的交通参与者,如下所示:

目前感觉更多的是目标识别的功能,决策的过程还是没有演示。更多的使用介绍可以查看 毫末大模型 DriveGPT 试用。
一些思考
关于 DriveGPT 是否真的能表现出色仍然是一个问题。即使 DriveGPT 可以在离线环境下的 GPU 数据中心中表现良好,但我认为在汽车 SoC 上实时运行 DriveGPT 可能太具有挑战性,因为运行生成 GPT 模型的推理成本很高。
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论