文章目录(Table of Contents)
简介
在多智能体系统中,各个智能体的决策通常是相互依赖的,这增加了强化学习的复杂性。早期的多智能体强化学习方法往往采用了独立学习的策略,其中每个智能体独立地更新其策略,忽略了其他智能体的存在。然而,这种方法忽略了智能体之间的相互作用,导致学习过程不稳定,难以收敛到最优策略。
为了解决这些问题,Value Decomposition Networks(VDN)方法被提出。VDN 的核心思想是将多智能体环境中的全局价值函数分解为各个智能体的局部价值函数之和。这种分解方式既能够保持智能体之间的协作,又能维持计算的可行性。通过这种方法,VDN 能够有效地训练出在多智能体环境中共同作用的策略。本文会结合代码介绍一下 VDN 的方法。
下图是关于 VDN,和独立训练以及联合训练这两者的区别(可以点击看大图):
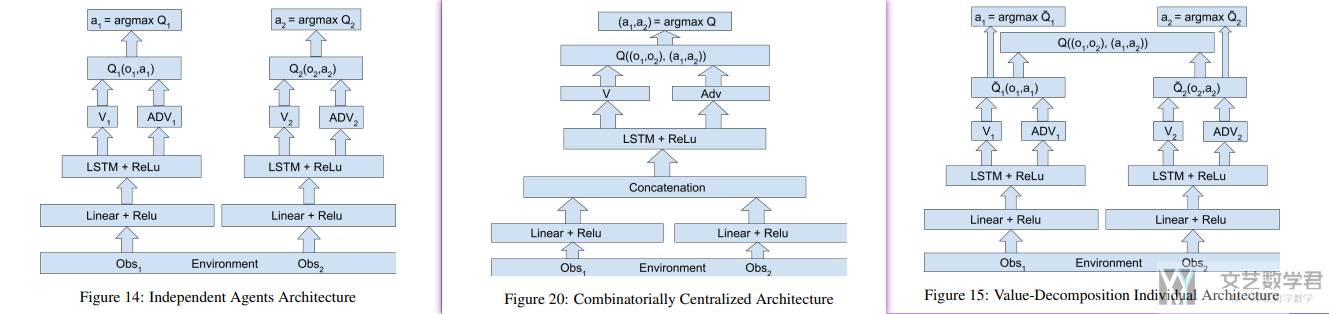
- 独立训练:都使用局部观测,各自奖励进行训练;
- 联合训练:将局部奖励合并,动作也进行组合(可能动作空间很大);
- VDN 方法:独立计算每个的 Q,然后进行求和,最后通过优化求和后的 Q,从而可以优化各自的 Q,也可以保证相互之间的协作。
参考资料
- 【多智能体强化学习】[learn to cooperate] VDN阅读笔记
- 多智能体强化学习(一) IQL、VDN、QMIX、QTRAN算法详解
- Value-Decomposition Networks For Cooperative Multi-Agent Learning,原文
VDN 算法解读
价值分解
基于价值分解的方法训练一个全局的 Q 网络,该 Q 网络考虑了全局信息,能够克服 MARL 的不稳定性,此时的问题在于如何通过价值的分解将智能体局部观测得到的独立Q网络与这个全局Q网络联系起来,从而我们只需在训练时获取全局Q网络,即可在执行过程中利用各个智能体的独立Q网络。
实际上,值函数分解理解为值函数近似更为合适,即如何利用局部的Q网络得到全局的Q网络,如何利用某些函数来近似该关系是该类方法的关键。
VDN 核心思想
VDN 来进行值分解的方法非常简单粗暴,他将系统的整体 Q 值看做是单个智能体 Q 值的总和。
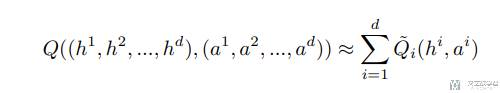
这里 a_i 是表示每个 agent 的动作,h_i 表示每个 agent 的观测(是一个时间序列,所有没有用 s_i)。这样设计可以使得:
- 我们可以有一个网络来计算每个 agent 的 Q 值,然后进行求和,最后通过求和后的
Q_total值来隐式学习各个 agent 的独立的 Q。 - 相当于对
Q_total进行梯度更新,梯度会经过Q_total传到每一个Q_i上面,从而更新每一个 agent 的 Q-network。 - 此时 VDN 可以集中式学习,分布式执行。也就是训练的时候通过
Q_total去更新每一个Q_i。执行的时候只需要Q_i就可以了。
VDN 模型框架
VDN 的核心框架如下图所示。下图左侧是独立 agent,每一个 agent 独立计算 Q 值。右侧是 VDN 的想法,将每个 agent 独立计算的 Q 值求和得到 Q_total,然后通过优化 Q_total 从而可以优化到每一个 agent。
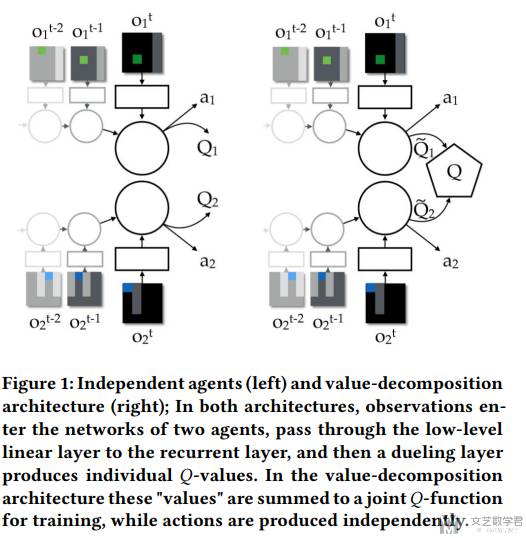
我的理解,这样做的好处是此时 Q 相当于考虑了两个 agent 合作之后的奖励的和,而不是独立的两个智能体。如果分开考虑,可能会出现一个 Agent 不做动作的情况,下面我们看一个简单的例子。
VDN 简单例子
现在有两个智能体(两名球员)需要合作得分。我们将这两名球员称为 Agent A 和 Agent B。比赛的目标是两名球员合作将球传进对方的球门得分。Agent A更接近球门,而 Agent B 控制着球。在这个游戏中,只有当球被传给 Agent A 并且 Agent A 得分时,团队才能获得奖励。
独立训练(IDQN)
在IDQN中,每个智能体独立学习,不考虑另一个智能体的行为。这可能导致以下情况:
- Agent B 可能选择直接射门,因为这看起来是立即获得奖励的最简单方法,尽管它距离球门较远,成功率不高。
- Agent A 由于经常接不到球(因为Agent B总是尝试直接射门),可能学会不活跃地等待(成为一个"懒惰"智能体),因为它发现自己的行动对结果影响不大。
结果是,两个智能体可能都没有学习到如何有效地合作,因为它们各自追求最大化自己的即时奖励,而不是团队的长期奖励。
使用VDN
在 VDN 中,智能体的学习是为了最大化整个团队的奖励,这导致了不同的学习动态:
- Agent B 学习到传球给Agent A是一个更可靠的得分策略,因为这样可以增加整个团队的总奖励。
- Agent A 学习到它需要积极地移动到一个更佳的位置来接球和射门,因为这样可以更好地利用Agent B的传球来得分。
通过 VDN,两个智能体都有动机去学习如何更好地合作,因为他们的奖励是共享的。Agent B不太可能成为一个"懒惰"的智能体,因为它知道传球给Agent A将增加团队得分的可能性,这反过来也会提高它自己的奖励。
VDN 中的小技巧
VDN 原文中还讲了一些其他的小技巧,分别是,参数共享(parameter sharing),角色信息(role information)和 信息信道(information channels),这里简单介绍一下。
Weight Sharing
VDN 方法中的一个关键特性是权重共享。在实践中,智能体可以共享参数,特别是当它们执行类似的任务或在环境中扮演相似角色时。权重共享可以减少需要学习的参数数量,加快学习速度,并提高策略的泛化能力。相同任务类型的 agent 的权重可以是一样的。
Role Information
智能体可以被赋予不同的角色,这些角色定义了它们在环境中的职责和期望行为。VDN 方法给每个智能体提供一个 one-hot 编码作为它们的标识(identifier)与观测连接起来输入到网络。因而参数共享也是有条件的,只有相同角色的智能体会共享参数。
Information Channel
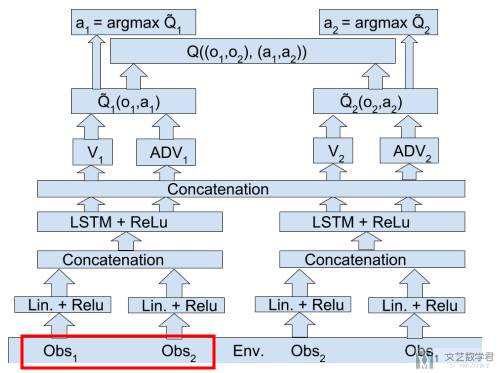
信息通道是智能体之间传递信息的途径。在VDN中,智能体可以通过显式或隐式的通信来协调它们的行动。其实这里本质上就是 agent 之间可以共享观测,这里作者还设置了 Low-level 和 High-level 的通信,以及可以两者都有。
Low-level communication Architecture:这里注意一下最底层,每一个 agent 预测 Q 的时候,会需要同时输入 obs1 和 obs2 的信息。
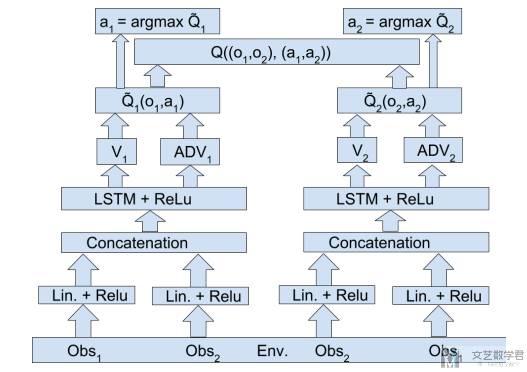
High-level communication Architecture
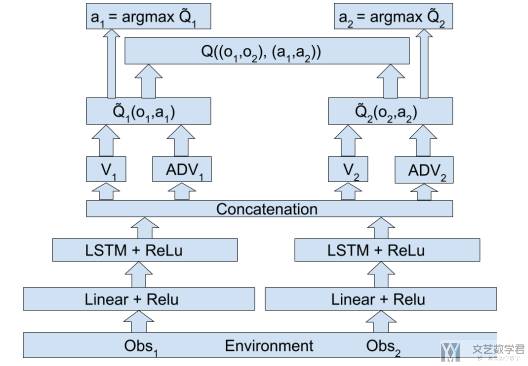
High+Low-level communication Architecture:这里作者不仅在输入部分同时输入两个的观测,还在上层做了信息融合。
VDN 简单代码介绍
VDN 伪代码
整体的 VDN 思路非常简单。假设有两个智能体,它们在某个状态下的个体Q值分别为2和3。vqn mixer网络可能简单地将这些值相加,得到整体Q值为5。如果下一个状态下的最优个体Q值分别为4和5,target_mixer网络同样将它们相加,得到整体最优Q值为9。
- # 假设的个体Q值和状态
- chosen_action_qvals = [2, 3] # 当前状态下智能体的Q值
- target_max_qvals = [4, 5] # 下一个状态下智能体的最优Q值
- # 使用 mixer 网络计算整体Q值
- total_qval = sum(chosen_action_qvals) # mixer 为 vdn
- total_target_qval = sum(target_max_qvals) # 同上
- # 假设的alpha和gamma值
- alpha = 0.1
- gamma = 0.9
- # 计算TD目标和更新整体Q值
- td_target = r + gamma * total_target_qval
- td_error = mean((total_qval - td_target)**2)
VDN 具体实现
在 Q Learner 的基础上,使用 torch.sum 进行求和即可。下面是 VDNMixer 部分代码(十分简单),直接求和:
-
- import torch
- import torch.nn as nn
- class VDNMixer(nn.Module):
- def __init__(self):
- super(VDNMixer, self).__init__()
- def forward(self, agent_qs, batch):
- return torch.sum(agent_qs, dim=2, keepdim=True)
关于详细的调用指南,可以查看 epymarl 部分的代码:
- epymarl---q_learner,这个代码的 Mixer 部分;
- epymarl--vdn Mixer,然后 Mixer 部分会调用这个的代码实现;
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论