文章目录(Table of Contents)
简介
这一篇是关于课程Data Science Applications的作业的相关内容. 因为作业的内容会比较多, 所以单独写一篇(一开始是这么想的, 实际发现内容不是很多).
关于课程内容可以查看链接: University of Agder交换记录–Data Science Applications(课程)
关于最后作业的内容, 可以查看github链接: data science作业内容
作业内容
个人作业
这门课是没有期末考试的, 所有的内容都是小组合作或者是自己探索的模型. 其中两个个人作业是:
- 第一个作业说明自己研究问题的重要性
- 第二个作业是针对自己第一个问题, 使用实际数据来解决这个问题
虽说这是两个个人作业, 但是做的时候实际上也是要事先进行小组讨论的, 需要确定整个小组的选题.
小组作业
关于最后一个大作业, 是写一份完整的实验报告. 这个就是需要涉及整个小组的选题. 比如我们小组选题是关于健康类的, 那么我们每个人的作业可能是写数据分析在心脏病上的应用, 在感冒上的应用等.
最后的一个大作业, 就是将以前写的作业合起来, 同时着重写其中的一个实验. 将其中的一个实验展开来写. 在我们这次作业里, 我们最后决定分析Coronavirus, 在欧洲这里也是挺严重的, 我们就对各个国家发展来进行可视化, 并进行简单的分析.
关于小组作业的要求, 和需要写的每一部分的内容, 如下图所示:

下面是我们小组作业最后提交的内容, 可以做一下参考, 我把老师给的example也上传了.
数据集介绍
其实这个选题是一个漫长的过程, 我们一开始定的是关于traffic的主题, 自己也找了相关的内容, 最后才是定下来关于做health相关的内容.
我一开始的作业是使用的关于Heart Disease的数据集, 后面才是决定做关于Coronavirus的相关内容的, 因为都是关于健康类的话题, 所以之前的作业也不需要进行修改.
我在下面简单介绍一下我在这次作业用到的数据集, 包括一开始想用, 但最后没有用到的关于heart disease的数据.
Coronavirus数据集
首先关于Coronavirus的数据集来自github, COVID-19 Data Repository by the Center for Systems Science and Engineering (CSSE) at Johns Hopkins University
在这个仓库里面, 他会更新每一天的, 每一个国家的Coronavirus的确诊人数, 死亡人数和恢复人数. 也就是会有三张表格, 分别记录confirmed, death和recovered.
我们看一下数据的样例, 可以看到数据包括国家名称, 省或州的名字, 精度和纬度, 和每一天的人数(confirmed, death, recovered):
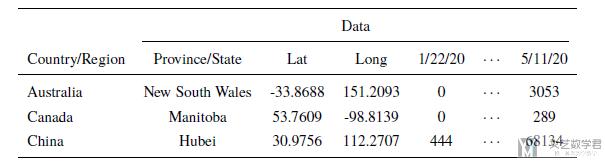
因为我们想要分析人数与国家发展, 国家人口和老龄化之间的关系, 所以我们还用到了另外三个数据集, 链接如下:
- GDP dataset (每个国家的GDP数据), https://data.worldbank.org/indicator/NY.GDP.PCAP.CD?locations=MC&name_desc=false
- Population dataset (每个国家的人口数据), https://data.worldbank.org/indicator/sp.pop.totl?end=2018&start=2018
- Aging dataset (每个国家的人口老龄化数据), https://data.worldbank.org/indicator/SP.POP.65UP.TO.ZS?end=2018&locations=LK&most_recent_value_desc=true&start=2018&view=map&year=2018
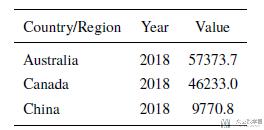
这些数据的格式基本都是一样的, 我们就看一下每个国家的人均GDP的数据的数据样例.
Heart Disease UCI
数据集链接: Heart Disease UCI
数据集介绍:
- 这个数据集是关于心脏病的数据集, 共有14个维度的特征
- 下面是14个特征的介绍:
- age
- sex
- chest pain type (4 values)
- resting blood pressure
- serum cholestoral in mg/dl
- fasting blood sugar > 120 mg/dl
- resting electrocardiographic results (values 0,1,2)
- maximum heart rate achieved
- exercise induced angina
- oldpeak = ST depression induced by exercise relative to rest
- the slope of the peak exercise ST segment
- number of major vessels (0-3) colored by flourosopy
- thal: 3 = normal; 6 = fixed defect; 7 = reversable defect
一些可供参考的资料:
一些其他的
下面是当时一开始的时候, 准备做关于traffic的内容, 所以查的一些数据集, 也就放在这里了(这个没什么用, 就是当时查了很多的数据).
New York City Airbnb Open Data
数据集链接: Kaggle-New York City Airbnb Open Data (2019)
数据集介绍:
- 这个数据集是Airbnb在New York City的数据. 其中大致包含房子的位置, 每一晚的价格等信息.
- This dataset has around 49,000 observations in it with 16 columns and it is a mix between categorical and numeric values.
一些研究的点:
- The relationship between price and neighborhood. (房屋价格与所在地区的关系, 在地图上进行价格的可视化)
- What can we learn about different hosts and areas? (不同地区的房源的分别)
- What can we learn from predictions? (ex: locations, prices, reviews, etc)
- Which hosts are the busiest and why? (分析哪一块地区最繁忙, 并分析为什么)
- Is there any noticeable difference of traffic among different areas and what could be the reason for it?
一些可供参考的代码(项目):
- 一个总体的数据集分析. 包含基本的数据处理, 例如缺失数据处理, 包含对每一列数据的分析: Data Exploration on NYC Airbnb
- 计算了相关系数, 价格分布, 不同类型的房间的占比(这里的图很好看): Hospitality in Era of Airbnb
- 价格的预测和模型的解释: Smart Pricing with XGB, RFR + Interpretations
- 地理位置空间的分析: Spatial Analysis of Airbnb listings in NYC
Europe Datasets
数据集链接: Kaggle-Europe Datasets (2019)
数据集介绍:
- 这个数据集包含欧洲各个国家的一些基本的属性, 例如每个国家的人口, GDP等.
- 我们可以用无监督的算法来处理一下这个数据集, 找出各个国家之间的关系.
一些研究点:
- GDP vs Job Satisfacction vs Population(bubble size)
- Income vs Environment Satisfaction
- Life Expectancy vs Pollution
- Analysis each country (对每个国家画出雷达图进行分析)
- Analysis under employment and unemployment (分析每个国家的就业率和失业率)
- As a person interested in travelling in Europe, I want to know which countries may have similar characteristics for my own safety. For example, I would be more cautious when travelling to countries that are grouped together because they have a higher crime rate and their citizens have a low confidence rating in the legal system. Hence, I would like to group similar countries together via k-means clustering. (分析国家与国家之间的相似性)
一些可供参考的代码(项目):
- 基础的数据集的处理, 基础的信息分析, 基本对所有的属性都有分析(这里的气泡图很好看): Comparing European Countries !!!
- 使用K-means算法将国家分为两类, 接着对每一个属性进行可视化: K-Means Clustering for Travelling in Europe
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论