文章目录(Table of Contents)
简介
上一篇我们介绍了全连接网络在手写数字上的识别。这一篇我们介绍卷积神经网络在 CIFAR-10 数据集上的分类。除了介绍完整的训练过程以外,我们还会对「卷积操作」进行相应的介绍。
参考资料
- 关于 Pytorch 中对图片的显示与保存,Pytorch图像处理,显示与保存
- 本实验的 Github 仓库链接: 卷积神经网络的CIFAR_10的识别.ipynb
- 卷积网络的文章汇总: CNN文章总结(简单汇总)
- 这一篇文章的实验部分来自 Pytorch 官方教程: TRAINING A CLASSIFIER
- 一些最新的卷积网络的结构说明和 Pytorch 实现, Development of Convolutional Neural Network(CNN的发展简介)
卷积的一些介绍
卷积的实际意义
我们可以人为的去设计一些卷积核来达到相应的目的。例如下图所示的卷积核,可以进行边缘检测。仔细看下面的卷积,相当于「中间像素值与周围的差」:

若一个像素点周围的像素值与该像素相当(或是接近),用此卷积计算的结果接近 0,如下所示:

若某像素值与周围点相差较大,此时则可以突出这种差异。

我们使用这个卷积做一个例子,查看是否可以用来检测图像的边缘。在下面的代码中,我们首先导入图片,接着初始化 kernel,最后导入图片通过 kernel 并保存:
- import torch
- import torch.nn as nn
- import cv2
- from torchvision.utils import save_image
- if __name__ == '__main__':
- # 导入图片
- img_path = './kenan.png'
- save_path = './output'
- img = cv2.imread(img_path, 0) # 黑白图像
- # 初始化 kernel
- edge_detect = nn.Conv2d(1,1,(3,3)) # 边缘检测 kernel
- edge_detect.weight.data = torch.tensor(
- [[[
- [-1,-1,-1],
- [-1,8,-1],
- [-1,-1,-1]
- ]]], dtype=torch.float32) # 指定 weight
- edge_detect.bias.data = torch.tensor([0.0], dtype=torch.float32)
- # 输出图片
- torch_img = torch.from_numpy(img/255).view(1, 1, img.shape[0], img.shape[1])
- save_image(torch_img, f'{save_path}/gray.jpg', normalize=True, range=(-1,1), scale_each=False, pad_value=0)
- filter_img = edge_detect(torch_img.float())
- save_image(filter_img, f'{save_path}/edge.jpg', normalize=True, range=(-1,1), scale_each=False, pad_value=0)
最终的结果如下图所示,可以看到成功提取了边缘:

关于通过卷积后图像的大小
首先我们说明一下通过卷积之后图像大小的变化. 假设有以下的参数:
- 原始图像的大小是, (N_h, N_w);
- 卷积核大小是, (K_h, K_w);
那么此时output的大小如下:
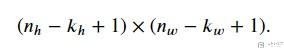
接着我们加上padding, 此时在行的padding是P_h, 在列的padding是P_w, 此时的output的大小是:
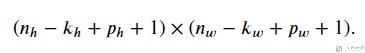
与上面相比, 只是单纯的在 height 和 width 上加上了P_h和P_w. 通常情况下, 我们会进行如下的设置:
- P_h = K_h - 1
- P_w = K_w - 1
这样输出图形的大小和输入图像的大小是一样的. 于是, 当我们将kernel size的大小选择为奇数的时候, 最后padding是偶数, 这样就可以在图像上下(或是左右)进行平均分配.
我们看下面的例子, 为了简单起见, 我们将input channel和output channel都设置为1. kernel size=(5,3), 这时候我们按照上面的式子进行设置, padding应该是(4,2). 但是实际上我们4的话需要左右平分, 所以最后padding是(2,1), 这样可以保持输入图形大小和输出图形大小是一样的. 下面是详细的代码.
- conv2d = nn.Conv2d(1, 1, kernel_size=(5, 3), padding=(2, 1))
- X = torch.rand(size=(8, 8))
- conv2d(X.reshape(1,1,8,8)).shape
- """
- torch.Size([1, 1, 8, 8])
- """
这个时候如果我们再加上stride, 例如在height上stride是S_h, 在width上的stride是S_w. 此时输出大小是:
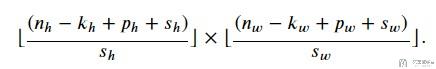
下面看一个比较复杂的例子, 此时:
- input size, 8*8 (H*W)
- kernel size, 5*6
- padding, 0*1, 注意这里padding的只代表一侧的, 比如说此时W是1, 表示是在侧面加1, 因为有左右, 实际上padding=2
- stride, 3*4
于是我们按照上面的公式进行计算, 得到下面的式子.
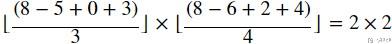
我们使用Pytorch做一下相应的实验, 结果也是和我们预期是一样的.
- conv2d = nn.Conv2d(1, 1, kernel_size=(5, 6), padding=(0, 1), stride=(3, 4))
- X = torch.rand(size=(8, 8))
- conv2d(X.reshape(1,1,8,8)).shape
- """
- torch.Size([1, 1, 2, 2])
- """
关于多通道的说明
当 input data 有多个 channel 的时候,例如此时是 channel=c,那么此时 kernel 也是拥有相应数量的通道,也就是 c。我们可以将 kernel 想成一个立方体。下面看一个例子:
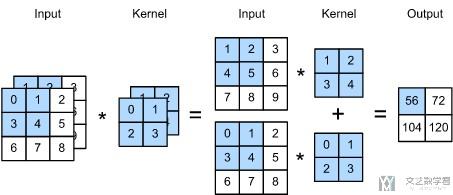
此时原始数据是双通道的, 于是kernel也是双通道的. 我们就可以把其看成一个2×2×2的正方体. 比如说上图中的运算, 就是在每一个channel分别计算, 最后相加有下面的式子:
- (1×1+2×2+3×4+5×4)+(0×0+1×1+3×2+4×3)=56.
我们使用Pytorch实现以上面的操作, 看一下最终结果是否可以预期的是一样的. 可以看到最终输出的结果与上面图中是一样的.
- # 得到模拟的训练样本
- X = torch.tensor([[[0, 1, 2], [3, 4, 5], [6, 7, 8]],
- [[1, 2, 3], [4, 5, 6], [7, 8, 9]]], dtype=torch.float32)
- conv2d = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=2, bias=False)
- # 初始化kernel的系数
- conv2d.weight.data = torch.tensor([[[0, 1], [2, 3]], [[1, 2], [3, 4]]], dtype=torch.float32).unsqueeze_(0)
- conv2d(X.unsqueeze_(0))
- """
- tensor([[[[ 56., 72.],
- [104., 120.]]]], grad_fn=<MkldnnConvolutionBackward>)
- """
接下来讨论当output有多个channels的时候. (通常情况下, 每一个channel都会表示不同的特征.) 于是, 这里output有多个channel的时候, 相当于有多个立方体, 每一个立方体输出是一个channel.
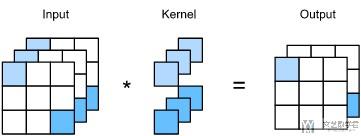
下面我们来看一下1×1的卷积, 来看一下有多个input channel和多个output channel下的情况. 1×1的卷积只会计算channel与channel之间的关系. 例如下图展示了input channel=3, output channel=2的情况. 这个时候1个output channel就是对应一个1×1×3的立方体, 这里因为output channel=2, 共有两个这样的立方体.
关于池化(Pooling)的一些说明
池化是为了解决图像对于位置敏感的问题. 例如现在有一个像素点是在 x[i,j] 的位置, 可能在别的图片中进行了位移, 在x[i+k, j+k]的位置, 如果是池化的化, 这一片输出值是相同的.
同时, 我们需要注意池化层是没有参数的, 常见的池化操作有max和average. 同时对于多通道的数据进行池化操作, 就是对每个channel进行单独操作, 并不会像卷积操作那样, 不同channel之间会有运算. 且池化操作, 输入的channel和输出的channel是相同的. 下面来看一个例子.
现在我们有如下的数据, 是一个两通道的数据.
- X = torch.arange(16, dtype=torch.float32).reshape((1, 1, 4, 4))
- X = torch.cat((X, X + 1), dim=1)
- """
- tensor([[[[ 0., 1., 2., 3.],
- [ 4., 5., 6., 7.],
- [ 8., 9., 10., 11.],
- [12., 13., 14., 15.]],
- [[ 1., 2., 3., 4.],
- [ 5., 6., 7., 8.],
- [ 9., 10., 11., 12.],
- [13., 14., 15., 16.]]]])
- """
我们对其进行最大池化, 最终的结果也是2个channel, 最终结果如下所示.
- pool2d = nn.MaxPool2d(3, padding=0, stride=1)
- pool2d(X)
- """
- tensor([[[[10., 11.],
- [14., 15.]],
- [[11., 12.],
- [15., 16.]]]])
- """
例如输出的14, 就是max(4,5,6,8,9,10,12,13,14)=14, 其余位置的计算均类似.
CIFAR-10数据集介绍
CIFAR-10数据集有10个类, 每类6000个332*32的彩色图像, 共60000个32x32 的彩色图像组成. 下面是从每一类挑出10张照片:

这10类图片分别是:
- airplane, 飞机
- automobile, 汽车
- bird, 小鸟
- cat, 小猫
- deer, 小鹿
- dog, 小狗
- frog, 青蛙
- horse, 小马
- ship, 小船
- trunk, 卡车
这10类中, 每一类有6000张照片, 其中有5000张在训练集中, 1000张在测试集中. 所以训练集有500010=50000张图片; 测试集中有100010=10000张图片.
卷积网络在CIFAR-10的识别
准备工作
这次的数据量还是比较大的, 我们使用GPU来进行训练.
- import torch
- import torch.nn as nn
- import torchvision
- import torchvision.transforms as transforms
- import torch.nn.functional as F
- import numpy as np
- import pandas as pd
- import matplotlib.pyplot as plt
- %matplotlib inline
- # Device configuration
- device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
- device
- """
- device(type='cuda')
- """
接着我们定义一下数据集中的10个类别和他们对应的名字.
- # 定义class
- classes = ('plane', 'car', 'bird', 'cat',
- 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
数据加载与数据预处理
我们使用CIFAR-10数据集, 该数据集可以使用torchvision.datasets.CIFAR10获得. 这一阶段的任务如下所示:
- 创建dataset
- 加载CIFAR10数据
- 进行数据预处理, (转换为tensor, 进行标准化)
- 下面简单说明以下为什么标准化里的参数都是0.5, 这可以保证标准化之后的图像的像素值在-1到1之间. 这是因为: For example, the minimum value 0 will be converted to (0-0.5)/0.5=-1, the maximum value of 1 will be converted to (1-0.5)/0.5=1.
- 创建dataloader
- 将dataset传入dataloader, 设置batchsize
首先我们创建dataset, 同时进行数据预处理(数据预处理有两个步骤, 如上面所介绍的).
- # 将数据集合下载到指定目录下,这里的transform表示,数据加载时所需要做的预处理操作
- transform = transforms.Compose(
- [transforms.ToTensor(),
- transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
- # 加载训练集合(Train)
- train_dataset = torchvision.datasets.CIFAR10(root='./data',
- train=True,
- transform=transform,
- download=True)
- # 加载测试集合(Test)
- test_dataset = torchvision.datasets.CIFAR10(root='./data',
- train=False,
- transform=transform,
- download=True)
接着设置dataloader, 设置batchsize的大小. 这里的dataloader就是训练的时候会用到的.
- batch_size = 10
- # 根据数据集定义数据加载器
- train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
- batch_size=batch_size,
- shuffle=True)
- test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
- batch_size=batch_size,
- shuffle=False)
最后查看一下样例数据(样例图像), 注意如何查看dataloader中的数据(这里查看的时候, 我们要对图像进行反归一化):
- def imshow(img):
- img = img / 2 + 0.5 # unnormalize
- npimg = img.numpy()
- plt.imshow(np.transpose(npimg, (1, 2, 0)))
- plt.show()
- # get some random training images
- dataiter = iter(train_loader)
- images, labels = dataiter.next()
- # show images
- imshow(torchvision.utils.make_grid(images, nrow=5))
- # print labels
- print(' '.join('%5s' % classes[labels[j]] for j in range(10)))

卷积网络的构建
接下来我们定义卷积网络, 我们测试一下浅层的卷积网络.
- class Net(nn.Module):
- def __init__(self):
- super(Net, self).__init__()
- self.conv1 = nn.Conv2d(3, 6, 5)
- self.pool = nn.MaxPool2d(2, 2)
- self.conv2 = nn.Conv2d(6, 16, 5)
- self.fc1 = nn.Linear(16 * 5 * 5, 120)
- self.fc2 = nn.Linear(120, 84)
- self.fc3 = nn.Linear(84, 10)
- def forward(self, x):
- x = self.pool(F.relu(self.conv1(x))) # n*6*14*14
- x = self.pool(F.relu(self.conv2(x))) # n*16*5*5
- x = x.view(-1, 16 * 5 * 5) # n*400
- x = F.relu(self.fc1(x)) # n*120
- x = F.relu(self.fc2(x)) # n*84
- x = self.fc3(x) # n*10
- return x
- net = Net().to(device)
- print(net)
- """
- Net(
- (conv1): Conv2d(3, 6, kernel_size=(5, 5), stride=(1, 1))
- (pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
- (conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
- (fc1): Linear(in_features=400, out_features=120, bias=True)
- (fc2): Linear(in_features=120, out_features=84, bias=True)
- (fc3): Linear(in_features=84, out_features=10, bias=True)
- )
- """
网络定义好之后, 为了测试是否可以使用, 我们用数据集简单测试一下.
- # 简单测试模型的输出
- examples = iter(test_loader)
- example_data, _ = examples.next()
- net(example_data.to(device)).shape
- """
- torch.Size([10, 10])
- """
定义损失函数和优化器
这一步没有什么特殊的, 损失函数为交叉熵损失, 优化器为SGD优化器.
- criterion = nn.CrossEntropyLoss()
- optimizer = torch.optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
模型的训练与测试
接下来就是模型的训练和测试. 这一部分的代码和前面全连接部分是差不多的.
- num_epochs = 10
- n_total_steps = len(train_loader)
- LossList = [] # 记录每一个epoch的loss
- AccuryList = [] # 每一个epoch的accury
- for epoch in range(num_epochs):
- # -------
- # 开始训练
- # -------
- net.train() # 切换为训练模型
- totalLoss = 0
- for i, (images, labels) in enumerate(train_loader):
- images = images.to(device) # 图片大小转换
- labels = labels.to(device)
- # 正向传播以及损失的求取
- outputs = net(images)
- loss = criterion(outputs, labels)
- totalLoss = totalLoss + loss.item()
- # 反向传播
- optimizer.zero_grad() # 梯度清空
- loss.backward() # 反向传播
- optimizer.step() # 权重更新
- if (i+1) % 1000 == 0:
- print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, i+1, n_total_steps, totalLoss/(i+1)))
- LossList.append(totalLoss/(i+1))
- # ---------
- # 开始测试
- # ---------
- net.eval()
- with torch.no_grad():
- correct = 0
- total = 0
- for images, labels in test_loader:
- images = images.to(device)
- labels = labels.to(device)
- outputs = net(images)
- _, predicted = torch.max(outputs.data, 1) # 预测的结果
- total += labels.size(0)
- correct += (predicted == labels).sum().item()
- acc = 100.0 * correct / total # 在测试集上总的准确率
- AccuryList.append(acc)
- print('Accuracy of the network on the {} test images: {} %'.format(total, acc))
- print("模型训练完成")
- """
- Accuracy of the network on the 10000 test images: 62.8 %
- Epoch [9/10], Step [1000/5000], Loss: 0.8864
- Epoch [9/10], Step [2000/5000], Loss: 0.8912
- Epoch [9/10], Step [3000/5000], Loss: 0.9013
- Epoch [9/10], Step [4000/5000], Loss: 0.9046
- Epoch [9/10], Step [5000/5000], Loss: 0.9081
- Accuracy of the network on the 10000 test images: 62.28 %
- Epoch [10/10], Step [1000/5000], Loss: 0.8363
- Epoch [10/10], Step [2000/5000], Loss: 0.8451
- Epoch [10/10], Step [3000/5000], Loss: 0.8562
- Epoch [10/10], Step [4000/5000], Loss: 0.8617
- Epoch [10/10], Step [5000/5000], Loss: 0.8699
- Accuracy of the network on the 10000 test images: 62.26 %
- 模型训练完成
- """
可以看到, 这里模型最终的准确率在60%左右. 这可能是因为模型不够复杂, 无法解决现有的问题. (关于loss和accurcy的变化, 可以查看原始notebook, 卷积神经网络的CIFAR_10的识别.ipynb)
分析每一类的准确率
上面我们获得了模型的一个总的准确率, 下面我们看一下模型对于每一小类的准确率.
- class_correct = list(0. for i in range(10)) # 每一类预测正确的个数
- class_total = list(0. for i in range(10)) # 每一类的总个数
- with torch.no_grad():
- for images, labels in test_loader:
- images = images.to(device)
- labels = labels.to(device)
- outputs = net(images)
- _, predicted = torch.max(outputs, 1)
- c = (predicted == labels).squeeze()
- for i in range(10): # 一个batch中的个数
- label = labels[i]
- class_correct[label] += c[i].item()
- class_total[label] += 1
- for i in range(10):
- print('Accuracy of %5s : %2d %%' % (
- classes[i], 100 * class_correct[i] / class_total[i]))
- """
- Accuracy of plane : 65 %
- Accuracy of car : 81 %
- Accuracy of bird : 43 %
- Accuracy of cat : 25 %
- Accuracy of deer : 60 %
- Accuracy of dog : 66 %
- Accuracy of frog : 73 %
- Accuracy of horse : 67 %
- Accuracy of ship : 73 %
- Accuracy of truck : 65 %
- """
到这里, 我们简单看了一下如何使用Pytorch实现卷积网络, 并完成在CIFAR10数据集上的分类. 但是可以看到, 最终的分类结果不是很理想, 下面我们尝试将网络变深, 来看一下准确率的变化.
VGG16测试
下面的代码和上面是差不多的, 唯一的不同就是把网络的结构变得更加复杂了. 其他的训练方法, 测试方法都是一模一样的.
下面就贴一下模型的代码, 训练部分查看notebook, 卷积神经网络的CIFAR_10的识别.ipynb.
- class VGG16(nn.Module):
- def __init__(self, num_classes=10):
- super(VGG16, self).__init__()
- self.features = nn.Sequential(
- # 1
- nn.Conv2d(3, 64, kernel_size=3, padding=1),
- nn.BatchNorm2d(64),
- nn.ReLU(True),
- # 2
- nn.Conv2d(64, 64, kernel_size=3, padding=1),
- nn.BatchNorm2d(64),
- nn.ReLU(True),
- nn.MaxPool2d(kernel_size=2, stride=2),
- # 3
- nn.Conv2d(64, 128, kernel_size=3, padding=1),
- nn.BatchNorm2d(128),
- nn.ReLU(True),
- # 4
- nn.Conv2d(128, 128, kernel_size=3, padding=1),
- nn.BatchNorm2d(128),
- nn.ReLU(True),
- nn.MaxPool2d(kernel_size=2, stride=2),
- # 5
- nn.Conv2d(128, 256, kernel_size=3, padding=1),
- nn.BatchNorm2d(256),
- nn.ReLU(True),
- # 6
- nn.Conv2d(256, 256, kernel_size=3, padding=1),
- nn.BatchNorm2d(256),
- nn.ReLU(True),
- # 7
- nn.Conv2d(256, 256, kernel_size=3, padding=1),
- nn.BatchNorm2d(256),
- nn.ReLU(True),
- nn.MaxPool2d(kernel_size=2, stride=2),
- # 8
- nn.Conv2d(256, 512, kernel_size=3, padding=1),
- nn.BatchNorm2d(512),
- nn.ReLU(True),
- # 9
- nn.Conv2d(512, 512, kernel_size=3, padding=1),
- nn.BatchNorm2d(512),
- nn.ReLU(True),
- # 10
- nn.Conv2d(512, 512, kernel_size=3, padding=1),
- nn.BatchNorm2d(512),
- nn.ReLU(True),
- nn.MaxPool2d(kernel_size=2, stride=2),
- # 11
- nn.Conv2d(512, 512, kernel_size=3, padding=1),
- nn.BatchNorm2d(512),
- nn.ReLU(True),
- # 12
- nn.Conv2d(512, 512, kernel_size=3, padding=1),
- nn.BatchNorm2d(512),
- nn.ReLU(True),
- # 13
- nn.Conv2d(512, 512, kernel_size=3, padding=1),
- nn.BatchNorm2d(512),
- nn.ReLU(True),
- nn.MaxPool2d(kernel_size=2, stride=2),
- nn.AvgPool2d(kernel_size=1, stride=1),
- )
- self.classifier = nn.Sequential(
- # 14
- nn.Linear(512, 4096),
- nn.ReLU(True),
- nn.Dropout(),
- # 15
- nn.Linear(4096, 4096),
- nn.ReLU(True),
- nn.Dropout(),
- # 16
- nn.Linear(4096, num_classes),
- )
- #self.classifier = nn.Linear(512, 10)
- def forward(self, x):
- out = self.features(x)
- out = out.view(out.size(0), -1)
- out = self.classifier(out)
- return out
- # 定义当前设备是否支持 GPU
- net = VGG16().to(device)
- # 定义损失函数和优化器
- criterion = nn.CrossEntropyLoss()
- optimizer = torch.optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
最终的模型的准确率在80%左右, 可以看到在模型变深, 变复杂之后, 在测试集上的准确率得到了上升.

关于每一类的准确率, 请查看notebook, 卷积神经网络的CIFAR_10的识别.ipynb.
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论