文章目录(Table of Contents)
简介
本文会介绍,记录一些使用 SUMO 做「信号灯控制」的库。主要是看一下别人是如何从仿真过程中提取特征,提取的特征有哪些,如何下发动作,动作有哪些(我会结合我的使用来说明)。
SUMO-RL
项目链接,SUMO-RL,SUMO-RL provides a simple interface to instantiate Reinforcement Learning environments with SUMO for Traffic Signal Control.
该项目提供了一个与 SUMO 交互的简单接口,且该项目比较好理解。在安装完毕之后,可以进入 ./sumo-rl/experiments 目录下了解如何使用 sumo_rl 来与 SUMO 进行交互。
我们用 ./sumo-rl/nets/3x3grid做一下简单的解释,该环境如下所示。我们使用 sumo_rl 在下面环境下分别提取 obs,计算 reward,看一下他是如何执行 action 的:

下面代码是一段最简单的使用 sumo_rl 来与环境进行交互:
- import os
- def getAbsPath(file_relpath):
- """将相对路径转换为绝对路径
- """
- file_abspath = os.path.abspath(__file__) # 获得当前文件的绝对路径
- folder_abspath = os.path.dirname(file_abspath) # 获得所在文件夹
- return os.path.join(folder_abspath, file_relpath)
- import sumo_rl
- env = sumo_rl.SumoEnvironment(net_file=getAbsPath('../nets/3x3grid/3x3Grid2lanes.net.xml'),
- route_file=getAbsPath('../nets/3x3grid/routes14000.rou.xml'),
- delta_time=10,
- use_gui=True,
- num_seconds=3600)
- obs = env.reset()
- for run in range(1, 10000):
- actions = {ts: env.action_spaces(ts).sample() for ts in env.ts_ids}
- observation, reward, done, info = env.step(actions)
- env.close()
特征的提取
在 sumo-rl 中是按照「信号灯」来提取特征的,每个信号灯提取的特征如下所示(这部分的计算在代码 ./sumo_rl/environment/traffic_signal:computer_observation 来定义):
- obs = [phase_one_hot, min_green, lane_1_density,...,lane_n_density, lane_1_queue,...,lane_n_queue]
上面特征值每一个值得含义如下所示:
phase_one_hotis a one-hot encoded vector indicating the current active green phase(表示当前的绿灯在哪一个相位。例如某个信号灯有四个相位,当前这个时刻第三个相位的信号灯是绿灯,那么此时就是[0,0,1,0])min_greenis a binary variable indicating whether min_green seconds have already passed in the current phase(最小绿灯时间是否过,没有到min_green设定的时间,信号灯是不会改变的,这个的长度就是 1)lane_i_densityis the number of vehicles in incoming lane i dividided by the total capacity of the lane(每个车道的车道密度)lane_i_queueis the number of queued (speed below 0.1 m/s) vehicles in incoming lane i divided by the total capacity of the lane(每个车道的排队长度)
最终的 obs 如下所示,分别返回每个交叉路口的数据:

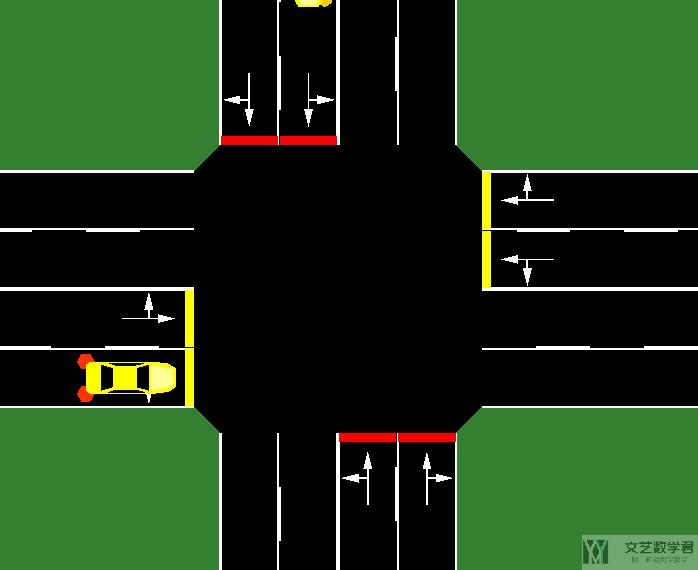
我们看一下交叉口 0,他一共有 8 个车道,如下图所示,所以他的特征大小是 21(也就是 4+1+8+8):
动作的设计
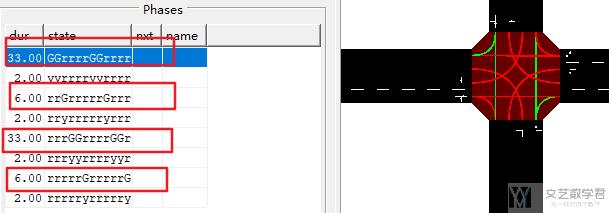
在 SUMO-RL 中,动作就是改变信号灯下一个时刻的相位。在 SUMO-RL 中,每隔 delta_time 可以修改 next phase 的值。例如对于 2-way single intersection 环境来说,他的相位情况如下,其中共有四个绿灯相位:
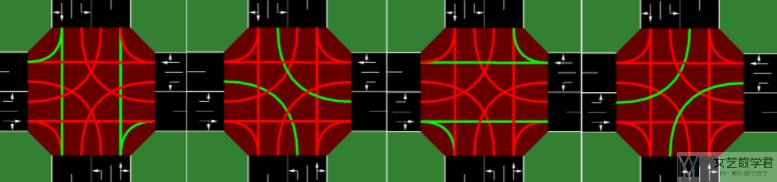
其中的四个绿灯相位如下所示,相当于是有 4 个动作,从下面的绿灯相位中选择一个:
奖励的计算
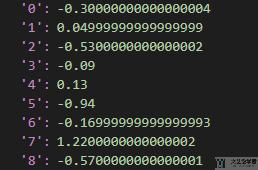
默认的奖励是当前车辆的「waiting time」与上一次车辆的「waiting time」的差,最后每一个信号灯都会有一个奖励。(这部分的计算在代码 ./sumo_rl/environment/traffic_signal:computer_reward 来定义)
下面是在环境 ./sumo-rl/nets/3x3grid 中每一个信号灯返回的奖励:
CityFlow
CityFlow文档链接,CityFlow's Documentation;CityFlow的Github仓库,CityFlow's Github;
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-








评论