文章目录(Table of Contents)
简介
这一篇会介绍数据预处理的方式,即进行如下的操作:
- 对于离散的数据 : 使用one-hot表示;
- 对于连续的数据 : 则不进行改变;
- 最后输出为X_train, Y_train, X_test, Y_test这四个文件;
数据处理
数据读取
这一步,我们导入数据,同时记录train和test数据的长度。
- # read raw data
- dfDataTrain = pd.read_csv("./data/train.csv")
- dfDataTest = pd.read_csv("./data/test.csv")
- # show Training Size and Testing Size
- intTrainSize = len(dfDataTrain)
- intTestSize = len(dfDataTest)
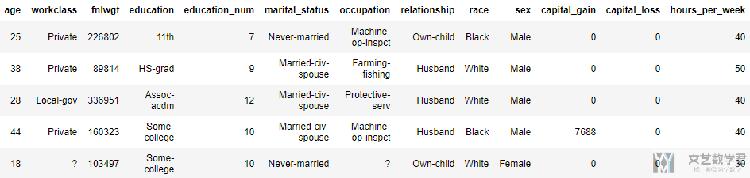
数据的样式大致如下(好像压缩了有点不清楚了,不过没事),就是数据中包含离散的数据。
处理labels标签
因为是做分类任务,原始的label是使用文字来描述的,我们先将其变为0或是1.
- # processing Training Label (Y)
- dfDataTrainY = dfDataTrain["income"]
- dfTrainY = pd.DataFrame((dfDataTrainY==" >50K").astype("int64"), columns=["income"]) # >50K 1, =<50K 0
处理之前的样子:
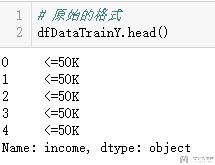
处理之后的样子

我们需要将income这一列在训练集中去除;
- dfDataTrain = dfDataTrain.drop(["income"], axis=1)
离散数据one-hot编码
- # 训练集和测试集的数据合并
- dfAllData = pd.concat([dfDataTrain, dfDataTest], axis=0, ignore_index=True)
- # 找出离散变量
- listObjectColumnName = [col for col in dfAllDataX.columns if dfAllDataX[col].dtypes=="object"] # 找到连续值得变量
- listNonObjectColumnName = [col for col in dfAllDataX.columns if dfAllDataX[col].dtypes!="object"] # 找到离散值得变量

接着我们重构数据集即可,即将连续变量放在前面,离散的使用one-hot编码后接在后面。
- # 连续变量
- dfNonObjectData = dfAllDataX[listNonObjectColumnName]
- # 离散变量
- dfObjectData = dfAllDataX[listObjectColumnName]
- dfObjectData = pd.get_dummies(dfObjectData) # 对离散变量使用one-hot编码
- # 合并连续变量与离散变量
- dfAllDataX = dfNonObjectData.join(dfObjectData)
最后的dfAllDataX就是最后需要的。
离散数据转为标号
上面是介绍了离散数据如何转换为one-hot的编码,有的时候我们不需要转为one-hot,只需要转为标号就可以了,于是我们可以使用下面的方式进行转换。
- dfObjectData = dfDataX[listObjectColumnName] # 这个是离散变量的值
- dfObjectData = dfObjectData.astype('category') # 对离散变量变成编号
- for i in dfObjectData.columns:
- dfObjectData[i] = dfObjectData[i].cat.codes
- dfDataX = dfNonObjectData.join(dfObjectData) # 合并
总体的思路是和上面转one-hot的方式是一样的,也是先把离散变量拆出来,不过上面是转为one-hot,这里是转为标号,接着把数据合并即可。
训练集,测试机分割与数据保存
- # 切分训练集和预测集
- dfTrainX = dfAllDataX[0:intTrainSize]
- dfTestX = dfAllDataX[intTrainSize:(intTrainSize + intTestSize)]
- # 数据的保存
- dfTrainX.to_csv("./ProcessData/X_train_my.csv", index=False)
- dfTestX.to_csv("./ProcessData/X_test_my.csv", index=False)
- dfTrainY.to_csv("./ProcessData/Y_train_my.csv", index=False)
- dfTestY.to_csv("./ProcessData/Y_test_my.csv", index=False)
总体代码
下面是KDD99预处理的代码,放一个总体的代码在这里,方便查看。
- # KDD99数据得预处理
- # - discrete(离散)变量使用one-hot表示
- # - continuous(连续)变量仍然保留
- import csv, os
- import numpy as np
- import pandas as pd
- COL_NAMES = ["duration", "protocol_type", "service", "flag", "src_bytes",
- "dst_bytes", "land", "wrong_fragment", "urgent", "hot", "num_failed_logins",
- "logged_in", "num_compromised", "root_shell", "su_attempted", "num_root",
- "num_file_creations", "num_shells", "num_access_files", "num_outbound_cmds",
- "is_host_login", "is_guest_login", "count", "srv_count", "serror_rate",
- "srv_serror_rate", "rerror_rate", "srv_rerror_rate", "same_srv_rate",
- "diff_srv_rate", "srv_diff_host_rate", "dst_host_count", "dst_host_srv_count",
- "dst_host_same_srv_rate", "dst_host_diff_srv_rate", "dst_host_same_src_port_rate",
- "dst_host_srv_diff_host_rate", "dst_host_serror_rate", "dst_host_srv_serror_rate",
- "dst_host_rerror_rate", "dst_host_srv_rerror_rate", "labels"] # 共42个维度
- def makeDataProcessing(dfData):
- dfDataX = dfData
- listObjectColumnName = [col for col in dfDataX.columns if dfDataX[col].dtypes=="object"]
- print("离散变量名称:{}".format(listObjectColumnName))
- listNonObjectColumnName = [col for col in dfDataX.columns if dfDataX[col].dtypes!="object"]
- print("连续变量名称:{}".format(listNonObjectColumnName))
- dfNonObjectData = dfDataX[listNonObjectColumnName] # 这个是连续变量的值
- dfObjectData = dfDataX[listObjectColumnName] # 这个是离散变量的值
- dfObjectData = pd.get_dummies(dfObjectData) # 对离散变量做one-hot编码
- dfDataX = dfNonObjectData.join(dfObjectData) # 合并
- # dfDataX = dfDataX.astype("int64")
- return dfDataX
- if __name__ == "__main__":
- # the filename
- Trainfilepath = './NSL-KDD/KDDTrain+_20Percent.txt'
- Testfilepath = './NSL-KDD/KDDTest-21.txt'
- # read raw data
- dfDataTrain = pd.read_csv(Trainfilepath, names=COL_NAMES, index_col=False)
- dfDataTest = pd.read_csv(Testfilepath, names=COL_NAMES, index_col=False)
- # show Training Size and Testing Size
- intTrainSize = len(dfDataTrain)
- intTestSize = len(dfDataTest)
- # processing Training Label (Y)
- dfDataTrainY = dfDataTrain["labels"]
- dfDataTestY = dfDataTest["labels"]
- dfTrainY = pd.DataFrame((dfDataTrainY=="normal").astype("int64"), columns=["labels"]) # normal 1, anomaly 0
- dfTestY = pd.DataFrame((dfDataTestY=="normal").astype("int64"), columns=["labels"]) # normal 1, anomaly 0
- # processing Training and Testing data (X)=>对离散的变量做one-hot
- dfDataTrain = dfDataTrain.drop(["labels"], axis=1)
- dfDataTest = dfDataTest.drop(["labels"], axis=1)
- dfAllData = pd.concat([dfDataTrain, dfDataTest], axis=0, ignore_index=True)
- dfAllData = makeDataProcessing(dfData=dfAllData)
- # sperate All data to Training and Testing
- dfTrainX = dfAllData[0:intTrainSize]
- dfTestX = dfAllData[intTrainSize:(intTrainSize + intTestSize)]
- # save Training data, Testing data and Training label
- dfTrainX.to_csv("./ProcessData/X_train_my.csv", index=False)
- dfTestX.to_csv("./ProcessData/X_test_my.csv", index=False)
- dfTrainY.to_csv("./ProcessData/Y_train_my.csv", index=False)
- dfTestY.to_csv("./ProcessData/Y_test_my.csv", index=False)
参考资料

- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-










评论