Pandas 建立在 NumPy 基础之上,但增加了更加高级实用的功能,比如数据自动对齐功能,时间序列的支持,缺失数据的灵活处理等等。这里我们就会介绍一下 Pandas 的简单的使用。
文章目录(Table of Contents)
Pandas介绍
在数据分析中,我们更多的针对表格数据进行处理,也就是 NumPy 中的二维数组数据,尽管 NumPy 对于多维数组的支持已经足够强大,但 Pandas 处理这些二维数据时更加得心应手。Pandas 建立在 NumPy 基础之上,但增加了更加高级实用的功能,比如数据自动对齐功能,时间序列的支持,缺失数据的灵活处理等等。
为了方便,下面代码中出现的pd,Series和DataFrame已经在 IPython终端中通过以下方式导入:
- import numpy as np
- import pandas as pd
- from pandas import Series,DataFrame
Series和DataFrame
Series和DataFrame是Pandas中的两种核心数据结构,大部分Pandas的功能都围绕着两种数据结构进行。下面分别对这两个数据结构进行介绍.
Series介绍
创建Series数据
Series是值的序列,可以理解为一维数组,它只有一个列和索引。索引可以定制,当不指定时默认使用整数索引,而且索引可以被命名:
我们首先生成一个默认的整数索引的Series
- s1 = Series([1,2,3,4,5])
- >>
- 0 1
- 1 2
- 2 3
- 3 4
- 4 5
- dtype: int64
默认索引可以看到是使用整数索引的。接下来我们看一下对索引进行重命名,并且对索引进行命名。
s1 = Series([1,2,3,4,5],index=['a','b','c','d','e'])
s1.index.name = 'index'
>>
index
a 1
b 2
c 3
d 4
e 5
dtype: int64Series的选择
当我们生成了Series数据后,我们应该如何选择其中的部分数据呢。对于Series数据,我们主要通过索引来进行选择。
可以看到对于指定了索引的Series序列来说,我们有两种选择元素的方式,一种是以整数索引(这说明整数索引一直默认存在),第二种方式是通过指定的字符索引进行。
s1 = Series([1,2,3,4,5],index=['a','b','c','d','e'])
>>
a 1
b 2
c 3
d 4
e 5
dtype: int64
s1[0]
>> 1
s1['a']
>> 1
s1[1:3]
>>
b 2
c 3
dtype: int64
s1['b':'c']
>>
b 2
c 3
dtype: int64其实整数索引和字符索引,分别调用了s1.iloc和s1.loc索引,其中iloc代表整数索引,如下代码:
s1.iloc[1:3]
>>
b 2
c 3
dtype: int64
s1.loc['b':'c']
>>
b 2
c 3
dtype: int64上面这种选则方法在DataFrame会有用到。对于Series数据,我们只要直接使用索引来获取部分元素即可。
使用滑动窗口-移动平均值计算
我们使用 pandas.Series.rolling 来完成移动平均的操作。该函数可以根据设置的 window 来计算一些统计值。其中常见的参数为:
- window,Size of the moving window. This is the number of observations used for calculating the statistic. Each window will be a fixed size.
- min_periods,Minimum number of observations in window required to have a value (otherwise result is NA)
- win_type,Provide a window type. If
None, all points are evenly weighted.
下面我们来看一个例子,滑动窗口大小是2,进行求和和求平均。我们首先创建测试使用的数据。
- df = pd.DataFrame({'B': [0, 1, 2, 3, 4]})
- """
- B
- 0 0
- 1 1
- 2 2
- 3 3
- 4 4
- """
接着我们设置滑动窗口为2,来计算和。用法简单如下所示:
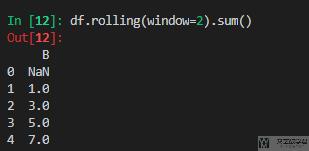
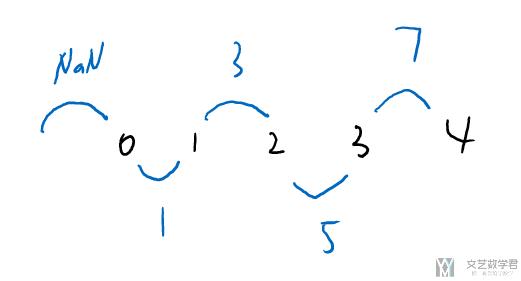
这里求和的方式如下所示:
同时,我们也求一下平均值。
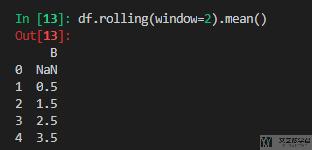
这里平均值的求法如下所示:
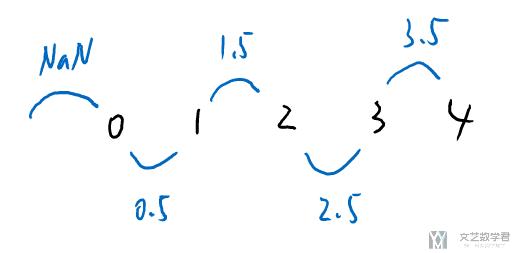
DataFrame介绍
创建DataFrame数据
DataFrame类似于二维数组,有行和列之分,除了像Series一样,多个行有索引而外,每个列上面还可以有标签label, 索引和标签本身都可以被命名:
- df = DataFrame(np.random.random((5,4)),index=['a','b','c','d','e'],columns=['A','B','C','D'])
- >>
- A B C D
- a 0.095161 0.982524 0.253735 0.105706
- b 0.795408 0.727552 0.183551 0.565994
- c 0.968957 0.283453 0.630097 0.308991
- d 0.310784 0.677971 0.417679 0.793429
- e 0.042881 0.817054 0.508455 0.914367
上面的代码中,我们通过指定索引和标签来创建了一个DataFrame实例。如果不指定的话,默认就是整数索引和标签。
除了上面的创建方式之外, 有的时候我们会首先创建一列, 之后使用往里面增加列的方式进行添加, 这样做的好处是不用处理列与列数据之间的形状, 我们看下面的一个例子.
我们有下面这样的x和y, 如果直接放进去需要使用reshape进行转换, 但是我们可以逐个创建.
- x_test = np.array([1,2,3])
- y_test = np.array([[4],[5],[6]])
首先创建只有一列的dataframe
- pdd = pd.DataFrame(x_test, columns=['x'])
- pdd
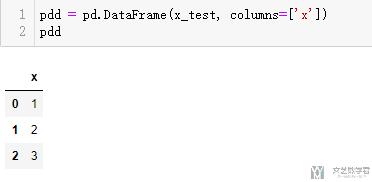
接着往里面增加一列, 这样会使很容易的
- pdd['y'] = y_test
- pdd

按行获取 Dataframe 的信息
有的时候我们需要按行来获取 Dataframe 的信息,这里可以使用 .iterrows() 来按行获取。我们下面来看一个例子:
- import pandas as pd
- df = pd.DataFrame({'c1': [10, 11, 12], 'c2': [100, 110, 120]})
- for index, row in df.iterrows():
- print('行', index, row['c1'], row['c2'])
最终的结果如下所示:
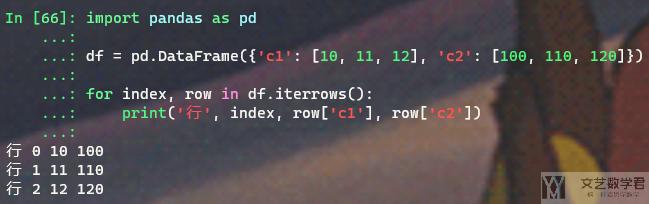
参考资料,How to iterate over rows in a DataFrame in Pandas
Dataframe 完整显示
有的时候当 dataframe 较大的时候,我们使用 print 进行显示会出现显示不全的问题,这个时候可以使用 pd.set_option 来进行设置,如下所示:
- def print_full(x):
- pd.set_option('display.max_rows', None)
- pd.set_option('display.max_columns', None)
- pd.set_option('display.width', 2000)
- pd.set_option('display.float_format', '{:20,.2f}'.format)
- pd.set_option('display.max_colwidth', None)
- print(x)
- pd.reset_option('display.max_rows')
- pd.reset_option('display.max_columns')
- pd.reset_option('display.width')
- pd.reset_option('display.float_format')
- pd.reset_option('display.max_colwidth')
其实比较重要的是设置下面几个选项:
- pd.set_option('display.max_rows', None)
- pd.set_option('display.max_columns', None)
- pd.set_option('display.width', 2000)
- pd.set_option('display.max_colwidth', None)
把上面几个设置放在 print 前面即可使得打印的内容变得更全。
Dataframe 的显示-在 jupyter notebook 显示
对于dataframe最简单的显示方式就是直接进行print显示, 但是print的结果有的时候不是很美观, 特别是在jupyter中显示的时候.
- table = pd.DataFrame(np.zeros((3, 2)))
- print(table)
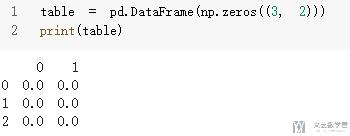
这个时候我们可以将 dataframe 转换为 html 进行显示. 下面看一个例子. 首先导入 Ipython.display, 我们需要使用到这一部分的库
- from IPython import display
- from IPython.display import HTML # 引入 display 模块目的方便程序运行展示
最后将dataframe转换为html再进行显示即可.
- html = table.to_html()
- display.display(HTML(html))
这样最后的结果就很好看很多.

参考资料:
Dataframe 的显示-在文件中打印
上面是在 jupyter notebook 的时候对 dataframe 来进行可视化,对于普通的文件的时候,我们需要别的方式来打印 dataframe 的内容。这里可以使用 tabulate 来进行打印。下面看一个简单的例子:
- from tabulate import tabulate
- import pandas as pd
- df = pd.DataFrame({'col_two' : [0.0001, 1e-005 , 1e-006, 1e-007],
- 'column_3' : ['ABCD', 'ABCD', 'long string', 'ABCD']})
- print(tabulate(df, headers='keys', tablefmt='psql'))
最后的显示情况如下所示:
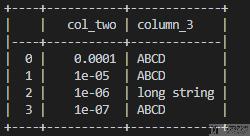
如果我们不需要左侧的 index,可以设置 showindex='False' 来屏蔽 index 的内容。具体可以写成下面的样子
- print(tabulate(df, headers='keys', tablefmt='psql', showindex='False'))
此时的输出结果如下所示:
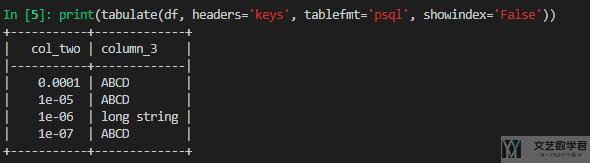
上面的 table format,我们还可以设置成不同的样式,例如下面可以加上横向的线条,这里的样式是 grid:
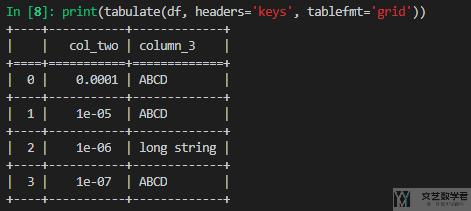
或者下面使用实线来进行绘制,这里的样式是 fancy_grid:
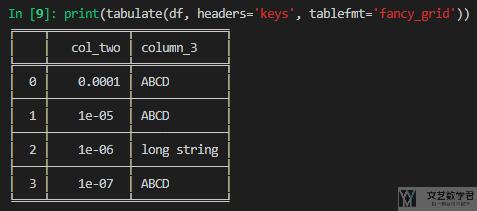
参考资料:Pretty Printing a pandas dataframe
Dataframe重命名-rename
在我们完成dataframe创建之后, 我们可能会需要修改行或者列的名称, 我们可以使用rename来进行名称的修改. 我们看一下下面的这个例子.
- test = pd.DataFrame([[1,2,3],[4,5,6]])
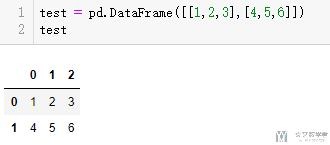
我们首先修改列名, 这里需要指定columns, 我们这里使用了inplace=True的设置, 直接替换原始的变量.
- test.rename(columns={0:'A',1:'B',2:'C'}, inplace=True)
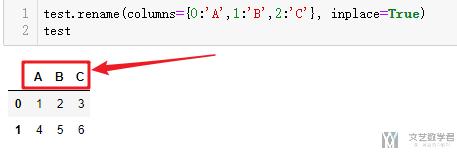
我们同样的方法也是可以修改行的名称, 行的时候使用Index即可.
- test.rename(index={0:'C1',1:'C2'}, inplace=True)
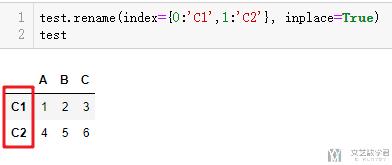
参考资料: pandas.DataFrame.rename
直接对原始变量修改-inplace
在上面介绍重命名的时候, 我们看到了 inplace 的使用, 这个表示的是在对原始变量进行修改的时候,不创建 copy,而是直接在原始内容上进行修改。我们可以看一下下面的例子.
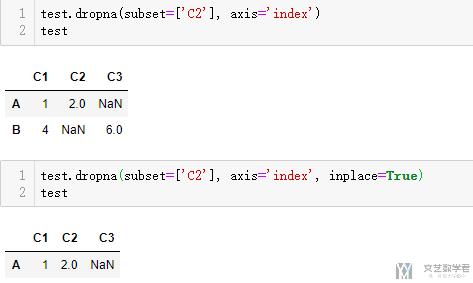
上面的例子可以看到, 如果不使用 inplace=True(第一个例子), 那么test的结果是不会改变的. 如果使用 inplace=True, 则会直接修改原始内容.
Dataframe删除行或列-drop
我们用下面的一个例子, 分别来看一下dataframe删除行或是删除列的操作. 还是使用下面的测试用例.
- test = pd.DataFrame([[1,2,3],[4,5,6]], index=['A','B'], columns=['C1','C2','C3'])
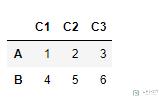
首先看一下删除行的操作.
- test.drop(['A'], axis=0) # 删除行

接着看一下删除列的操作.
- test.drop(['C2','C3'], axis=1) # 删除列

参考资料: Dropping Rows And Columns In pandas Dataframe
选择 Dataframe 元素
由于 DataFrmae 有行列之分,于是我们如果只使用df['A']会无法判断是行还是列,于是就要与之前讲到的loc了。首先我们先看一下获取一列数据:
df = DataFrame(np.random.random((5,4)),index=['a','b','c','d','e'],columns=['A','B','C','D'])
>>
A B C D
a 0.798929 0.987169 0.495320 0.623631
b 0.000925 0.335466 0.117363 0.007925
c 0.730285 0.616586 0.972650 0.503028
d 0.783396 0.246152 0.084311 0.977647
e 0.105396 0.123413 0.284357 0.292990
df['A'] #获取一列的数据
>>
a 0.798929
b 0.000925
c 0.730285
d 0.783396
e 0.105396
Name: A, dtype: float64
df[df.columns[0:3]] #获取多列数据
>>
A B C
a 0.798929 0.987169 0.495320
b 0.000925 0.335466 0.117363
c 0.730285 0.616586 0.972650
d 0.783396 0.246152 0.084311
e 0.105396 0.123413 0.284357
"""
我们看一下df.columns是什么数据
"""
df.columns
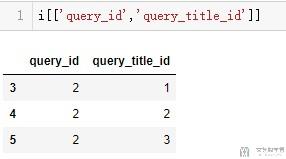
>> Index(['A', 'B', 'C', 'D'], dtype='object')对于获取多列的情况,我们可以使用下面这种方式来进行获取(别的地方的一个例子)。
- i[['query_id','query_title_id']]
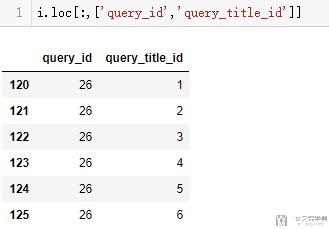
或是,我们可以使用下面的方式来获取多列(这个方式比较推荐)
- i.loc[:,['query_id','query_title_id']]
下面我们来看一下如何来选择单行或者多行数据
df.loc['a'] #选择一行数据
>>
A 0.798929
B 0.987169
C 0.495320
D 0.623631
Name: a, dtype: float64
df.loc['a':'c'] #选择多行数据
>>
A B C D
a 0.798929 0.987169 0.495320 0.623631
b 0.000925 0.335466 0.117363 0.007925
c 0.730285 0.616586 0.972650 0.503028当然loc还是支持行和列的,我们接下去看。
下面我们来看一下如何选定具体的某行某列的数据,并且如何选中部分数据
df.loc['a','A']
>> 0.79892857875107204
df.loc['a':'c','A':'C']
>>
A B C
a 0.798929 0.987169 0.495320
b 0.000925 0.335466 0.117363
c 0.730285 0.616586 0.972650对于上面的,我们需要注意顺序,即df.loc['a':'c','A':'C'],首先是行的索引,接着是列的索引。
对dataframe内元素排序-sort_values
有的时候, 我们会用到按照dataframe中元素的大小对dataframe进行重新排序. 我们举下面的一个例子, 注意看列C1的不是按照大小的顺序进行排序的.
- test = pd.DataFrame([[1,2],[3,4],[2,1]], index=['A','B','C'], columns=['C1','C2'])
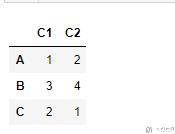
我们使用sort_values对dataframe进行重新排序.
- test.sort_values(by=['C1'], ascending=True)
最后排序的结果如下所示:

参考资料: pandas.DataFrame.sort_values
重新排序index
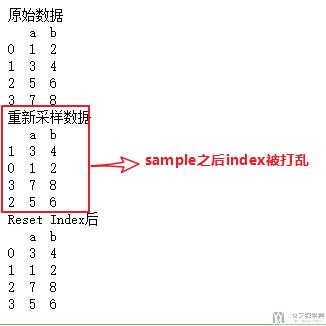
有的时候我们需要对index进行重新的排序,这个时候使用reset_index即可,下面一个例子.
- # index重新排序
- test = pd.DataFrame(np.array([[1,2],[3,4],[5,6],[7,8]]),columns=['a','b'])
- print("原始数据\n{}".format(test))
- test = test.sample(frac=1)
- print("重新采样数据\n{}".format(test))
- test.reset_index(drop=True, inplace=True)
- print("Reset Index后\n{}".format(test))
缺失值和数据自动对齐
在Pandas中最重要的一个功能是,它可以对不同索引的对象进行算术运算。比如将两个Series数据进行相加时,如果存在不同的索引,则结果是两个索引的并集,什么意思呢?通过例子看下:
s1 = Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])
>>
a 1
b 2
c 3
d 4
dtype: int64
s2 = Series([2, 3, 4, 5], index=['b', 'c', 'd', 'e'])
>>
b 2
c 3
d 4
e 5
dtype: int64
s1+s2
>>
a NaN
b 4.0
c 6.0
d 8.0
e NaN
dtype: float64以上代码中创建了两个s1和s2两个Series序列,两者具有相同的索引['b', 'c', 'd'], 所以在进行相加时,相同索引上的值会相加,但不重叠的索引引入NaN值,也就是缺失值。
而缺失值会在运算中传播,所以最终结果也是NaN值。根据相同的索引进行自动计算,这就是自动对齐功能。
同样的规则,在DataFrame数据中也生效:
df1 = DataFrame(np.arange(9).reshape(3,3), columns=list('ABC'), index=list('abc'))
>>
A B C
a 0 1 2
b 3 4 5
c 6 7 8
df2 = DataFrame(np.arange(12).reshape(3,4),columns=list('ABDE'), index=list('bcd'))
>>
A B D E
b 0 1 2 3
c 4 5 6 7
d 8 9 10 11
df1+df2
>>
A B C D E
a NaN NaN NaN NaN NaN
b 3.0 5.0 NaN NaN NaN
c 10.0 12.0 NaN NaN NaN
d NaN NaN NaN NaN NaN可以看到DataFrame的计算也会进行自动对齐操作,这个时候没有的行或者列会使用NaN值自动填充,而由于NaN值会传播,所以相加的结果也是NaN。
当然我们在计算时,可以指定使用值来填充NaN值,然后带入计算过程,如下所示:
df1.add(df2,fill_value=0)
>>
A B C D E
a 0.0 1.0 2.0 NaN NaN
b 3.0 5.0 5.0 2.0 3.0
c 10.0 12.0 8.0 6.0 7.0
d 8.0 9.0 NaN 10.0 11.0我们可以看到结果中仍有NaN,这是因为在那几个位置中df1和df2都没有定义,所以是NaN。
缺失内容的删除-dropna
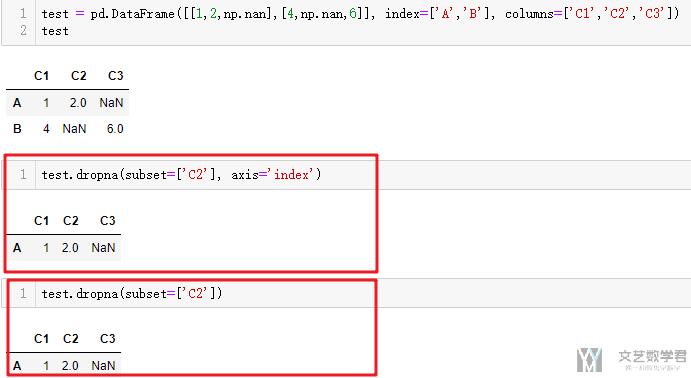
有的时候, 当只有少数缺失的时候, 并且可以删除不影响结果的时候, 我们可以将有缺失值的行或者列进行删除, 我们可以看一下下面的例子, 我们创建一个dataframe包含缺失数据.
- test = pd.DataFrame([[1,2,3],[4,np.nan,6]], index=['A','B'], columns=['C1','C2','C3'])
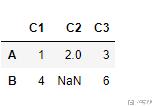
第一种情况是直接, 如果有缺失数据, 就把有缺失数据的那一行或者那一列直接删掉. 我们看一下如果有缺失数据, 就删掉一行的操作.
- test.dropna(axis='index') # 按行删除
- test.dropna(axis='columns') # 按列删除
最终的结果如下所示:
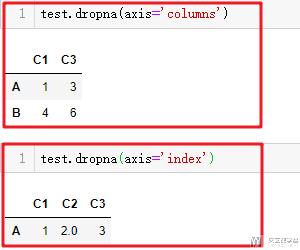
有的时候, 我们希望可以指定, 某一列元素有缺失的时候进行删除, 我们可以使用subset来指定自己要查看的列, 哪一列元素有缺失就进行删除.
- # 下面两种写法是一样的
- test.dropna(subset=['C2'], axis='index')
- test.dropna(subset=['C2'])
参考资料: pandas.DataFrame.dropna
常用统计
对于一些数据,我们可以直接使用describe来得到一些常用的统计信息。
df1 = DataFrame(np.arange(9).reshape(3,3), columns=list('ABC'), index=list('abc'))
df1.describe()
>>
A B C
count 3.0 3.0 3.0
mean 3.0 4.0 5.0
std 3.0 3.0 3.0
min 0.0 1.0 2.0
25% 1.5 2.5 3.5
50% 3.0 4.0 5.0
75% 4.5 5.5 6.5
max 6.0 7.0 8.0可以看到默认是按列来统计的,我们看一下每一个参数是什么意思。
count元素值的数量;mean平均值;std标准差;min最小值;25%下四分位数;50%中位数;75%上四分位数;max最大值;
按行或列进行运算
除了上面讲到的常用的运算,我们还可以自定义一些运算,如下面我们可以自定义一下极差的运算
df1 = DataFrame(np.arange(9).reshape(3,3), columns=list('ABC'), index=list('abc'))
>>
A B C
a 0 1 2
b 3 4 5
c 6 7 8
f = lambda x: x.max() - x.min() #这里也可以不使用匿名函数
def f(x):
return x.max()-x.min()
df1.apply(f)
>>
A 6
B 6
C 6
dtype: int64
df1.apply(f,axis=1)
>>
a 2
b 2
c 2
dtype: int64
数组的变形
关于这部分的内容, 强烈推荐这个链接, 里面讲的更加详细, 图也更加多: Reshaping and pivot tables
Melt-dataframe变形
melt是将宽表变为长表, 我自己感觉melt还是很好用的. 我们下面看一个例子, 比如有如下形式的数据.
- df = pd.DataFrame(([1,2,3,4,5,6],[7,8,9,10,11,12],[13,14,15,16,17,18]),
- index=['A','B','C'],
- columns=['Pop', 'GDP', '1/2', '1/3', '1/4', '1/5'])
- df
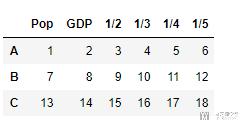
上面数据中1/2, 1/3表示日期. 我们希望将上面数据转换为每一行是一天的数据, 也就是说多一个变量, 表示日期, 然后还有一个变量表示日期对应的数字. 此时我们就可以使用melt来完成操作. 可能有点抽象, 我们看下面的实际例子.
- pd.melt(df, id_vars=['Pop','GDP'], var_name = 'date', value_name='Confirmed')
其中
- id_vars: 表示不展开的列, 最后是保留的变量
- var_name: 变量的名字, 在这里我们是要将1/2, 1/3展开, 这里都是日期.
- value_name: 这个是展开之后数字的名称.
最终的结果如下所示, 这个我是在使用Plotly绘制动态图的时候有用到, 需要这样进行转换一次:
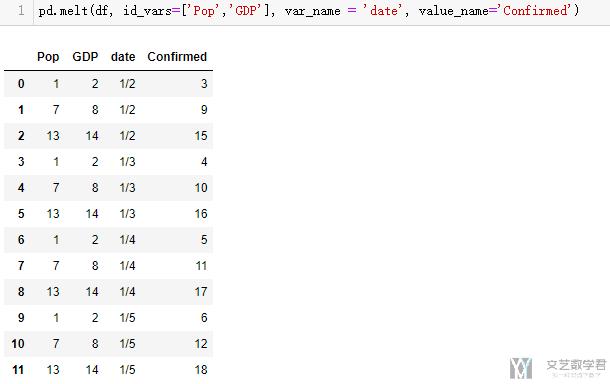
参考资料: 这个资料还是很不错的, 里面stack介绍的还是很全面的, Reshape a pandas DataFrame using stack,unstack and melt method
Pivot-透视表
在上面, 我们将宽表变为了长表, 这里我们可以使用pivot离开进行实现, 我们看下面的这个例子.
- pd.pivot(test, index='Name', columns='date', values='Confirmed')
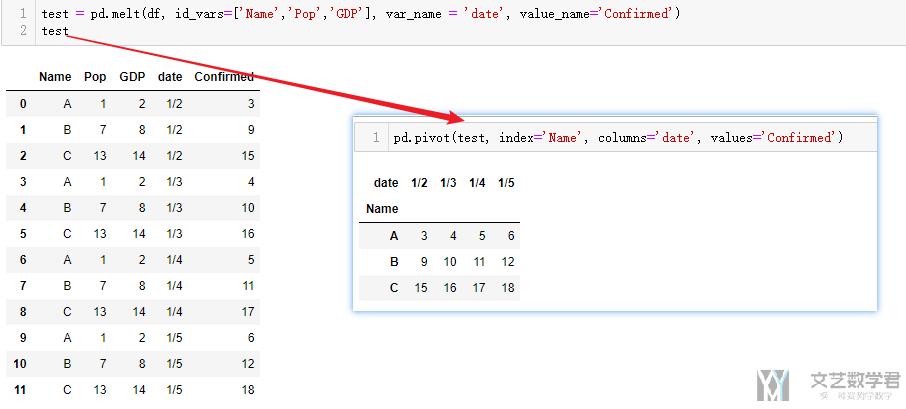
这个还原的表可以与上面melt部分最初的表结合着看.
Stack与Unstack-01
在pandas中, 我们使用stack来完成列向行的堆叠. 这么讲比较抽象, 我们看下面的一张图片就可以很好的理解stack在完成什么样子的功能了.
下面从左侧的dataframe到右侧的dataframe就是完成了stack的功能.
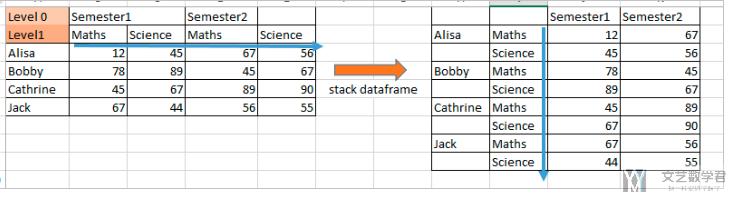
我们来看一下下面的这个例子, 具体看一下stack的效果, 首先我们生成测试数据.
- header = pd.MultiIndex.from_product([['Semester1','Semester2'],['Maths','Science']])
- d=([[12,45,67,56],[78,89,45,67],[45,67,89,90],[67,44,56,55]])
- df = pd.DataFrame(d,
- index=['Alisa','Bobby','Cathrine','Jack'],
- columns=header)
- df
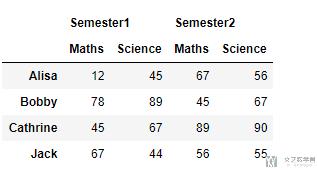
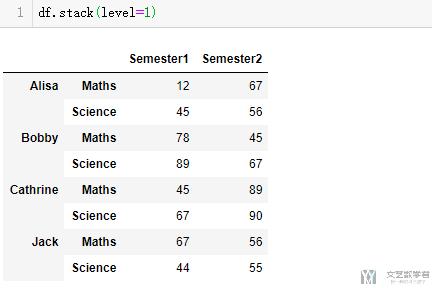
接着对上面的测试数据进行stack, 我们来查看stack之后的结果, 这里我们首先对level=1进行stack, level也就是Maths和Science, 可以看到下面的结果, 我们将列转换到了行.
- df.stack(level=1)
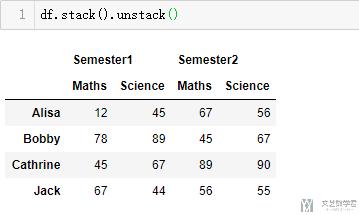
接着我们看一下对上面的数据进行unstack, 这一步也就是上面操作的逆操作, 可以进行还原.
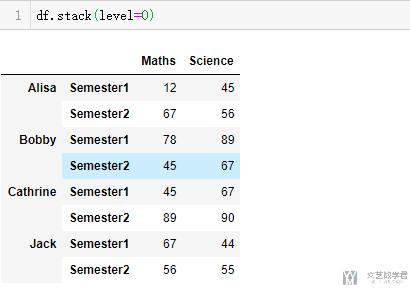
我们这里也看一下level=0的时候的结果, 也就是将semester1和semester2转换到行的位置.
参考资料:
- Pandas官网Stack说明: pandas.DataFrame.stack
- 一个介绍stack与unstack的网站, 上面主要内容来自于此: Reshape using Stack() and unstack() function in Pandas python
Stack与Unstack-02
stack除了上面的情况外, 我们更多的是见到一行列标题的表, 此时stack的作用就是将宽表变为长表. 我们看下面这个例子.
- df = pd.DataFrame(([1,2],[3,4],[5,6]), index=['A','B','C'], columns=['1/2','1/3'])
- df
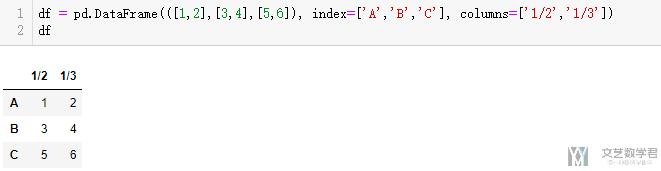
现在我们想将其变为长表格

参考资料: 这个资料还是很不错的, 里面stack介绍的还是很全面的, Reshape a pandas DataFrame using stack,unstack and melt method
数据合并和分组
关于这一部分的内容, 强烈推荐这个链接进行参考: Merge, join, and concatenate
数组合并-concat
有的时候需要合并两个DataFrame数据,合并数据的方式主要有两种,一种简单的进行拼接(列是一样的,直接按照行接下去),另一种是根据列名类像数据库表查询一样进行合并(有一个或多个相同的列,按照这些列进行合并)。
这两种操作可以分别通过调用pandas.concat和pandas.merge方法实现。后面多加了一种df.join()的方法进行操作。
首先看一下pandas.concat,这个可以完成纵向的合并,即行数变多。
- df1 = DataFrame(np.random.randn(3, 3))
- >>
- 0 1 2
- 0 0.506929 0.482098 0.142396
- 1 -1.431190 0.527396 0.784056
- 2 -1.184716 2.082178 0.666990
- df2 = DataFrame(np.random.randn(3, 3), index=[5, 6, 7])
- >>
- 0 1 2
- 5 0.611993 -0.264532 -0.022721
- 6 0.436712 -0.365940 1.430864
- 7 -0.646884 0.368955 -0.704303
- pd.concat([df1,df2])
- >>
- 0 1 2
- 0 0.506929 0.482098 0.142396
- 1 -1.431190 0.527396 0.784056
- 2 -1.184716 2.082178 0.666990
- 5 0.611993 -0.264532 -0.022721
- 6 0.436712 -0.365940 1.430864
- 7 -0.646884 0.368955 -0.704303
数组的添加-append
我们可以使用append来向数组进行添加一行. 我们看下面的例子. 首先我们初始化一个dataframe.
- df1 = pd.DataFrame(np.random.randn(3, 3))
- df1

接着我们定义要往里面添加的数据. 这里的name指这一行的名字.
- df2 = pd.Series([np.NAN]*3, index=df1.columns, name=str(['Append']))
- df2
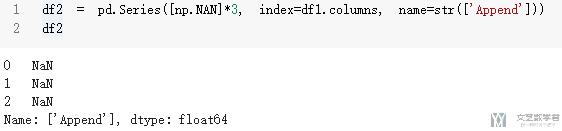
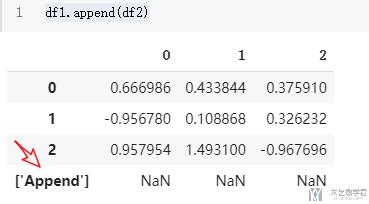
最后我们将df1和df2进行合并, 得到下面的内容.
- df1.append(df2)
数组的合并-merge
接着我们来看一下pandas.merge的操作,使用这个操作必须有一个相同的列,如下面;例子中有相同的列course。
- df1 = DataFrame({'user_id': [5348, 13], 'course': [12, 45], 'minutes': [9, 36]})
- >>
- course minutes user_id
- 0 12 9 5348
- 1 45 36 13
- df2 = DataFrame({'course': [12, 45], 'name': ['Linux 基础入门', '数据分析']})
- >>
- course name
- 0 12 Linux 基础入门
- 1 45 数据分析
- pd.merge(df1,df2)
- >>
- course minutes user_id name
- 0 12 9 5348 Linux 基础入门
- 1 45 36 13 数据分析
关于merge的操作,我们可以指定列, 使用on来进行指定. 这个也就是指定两个dataframe中相同的列, 所以写出来的代码如下所示:
- inputData = pd.merge(inputData,tf_idf_group_datafram,on=['query_id','query_title_id'])
多个dataframe的merge
关于merge有一个问题就是, merge只能两两进行操作, 那么如果同时有多个dataframe需要使用merge, 我们应该如何操作呢. 这个时候我们就需要使用reduce来完成相应的操作, 关于reduce的介绍可以查看链接, Python高级特性--Reduce的使用
我们下面就看一个小的例子, 我们现在有如下的三种表:
- left = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
- 'A': ['A0', 'A1', 'A2', 'A3'],
- 'B': ['B0', 'B1', 'B2', 'B3']})
- middle = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
- 'C': ['C0', 'C1', 'C2', 'C3'],
- 'D': ['D0', 'D1', 'D2', 'D3']})
- right = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
- 'E': ['E0', 'E1', 'E2', 'E3'],
- 'F': ['F0', 'F1', 'F2', 'F3']})
显示结果如下所示:
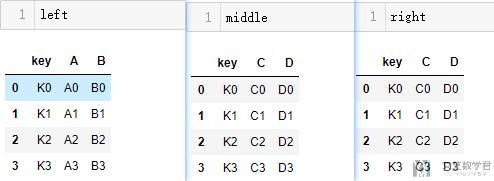
他们有一个共同的列是key, 所以我们可以按照key来进行合并. 但是pd.merge只能两个两个合并, 这个时候我们就可以使用merge来进行合并操作了.
- functools.reduce(lambda x,y: pd.merge(x,y,on='key'),[left,middle,right])
最终的结果如下所示, 完成了3个表的合并:
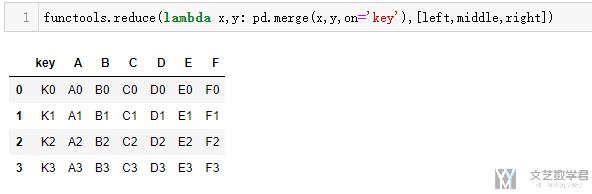
参考链接: Python: pandas merge multiple dataframes
数组的合并-join
我们还可以使用df.join()来进行列的合并.
- df1 = pd.DataFrame(np.array([[1,2],[3,4],[5,6]]),columns=['a','b'])
- df2 = pd.DataFrame(np.array([[7],[8],[9]]),columns=['c'])
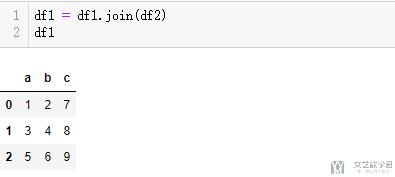
- df1 = df1.join(df2)
首先看一下合并前的数据的样式:
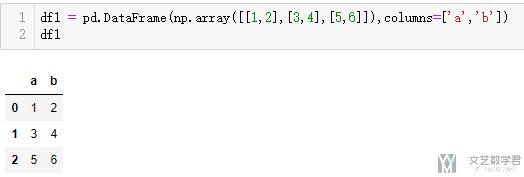
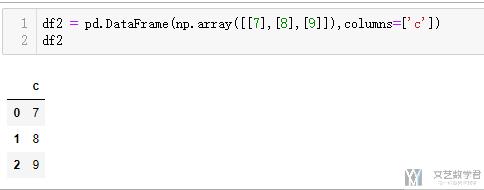
接着看一下合并后数据的样子
分组-groupby操作
groupby基础操作
在 Pandas 中,也支持类似于数据库查询语句GROUP BY的功能,也就是按照某列进行分组,然后再分组上进行一些计算操作,假如我们有如下的数据集,那么如何计算其中user_id是5348的用户的学习时间呢?
- df = DataFrame({'user_id': [5348, 13, 5348], 'course': [12, 45, 23], 'minutes': [9, 36, 45]})
- >>
- course minutes user_id
- 0 12 9 5348
- 1 45 36 13
- 2 23 45 5348
我们可以首先筛选出所有user_id为5348的行,我们通过df[df['user_id']==5348]来进行寻找出需要用的行,然后找出时间的列,然后进行求和统计,我们可以看一下下面的具体代码。
- df['user_id']==5348
- >>
- 0 True
- 1 False
- 2 True
- Name: user_id, dtype: bool
- df[df['user_id']==5348]
- >>
- course minutes user_id
- 0 12 9 5348
- 2 23 45 5348
- df[df['user_id']==5348]['minutes'].sum()
- >> 54
当然,我们可以使用group_by进行直接求和。
- df.groupby('user_id').sum()
- >>
- user_id course minutes
- 13 45 36
- 5348 35 54
高级分组-对多个列同时进行分组与选择
有的时候, groupby可以对多个列进行处理, 我们看下面的一个例子. 我们同时按照 continent 和 date 进行分组.
- df_mergedN = df_merged.groupby(['continent','date']).agg(dict_groupby)
- df_mergedN.drop(['Country/Region', 'ISO3', 'Lat', 'Long'], axis=1, inplace=True)
- df_mergedN
分组的结果如下所示:
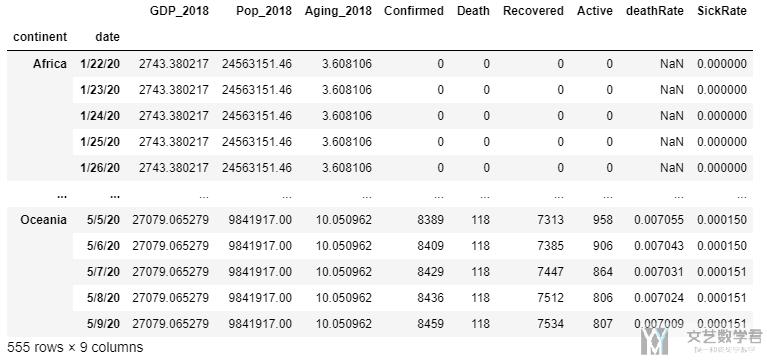
如果我们要选择全部Africa的数据, 可以使用下面的方式.
- df_mergedN[df_mergedN.index.get_level_values('continent') == 'Africa']
也就是上面的get_level_values.
高级分组-不同列执行不同操作
有的时候, 我们想要对不同的列进行不同的操作, 这个时候就需要用到groupby.agg的功能了, 我们看一下下面这个简单的例子.
我们原始的数据如下所示:
- Name Missed Credit Grade
- A 1 3 10
- A 1 1 12
- B 2 3 10
- B 1 2 20
我们想要生成如下的结果, 也就是Missed和Credit两部分进行求和, Grade部分进行求平均.
- Name Sum1 Sum2 Average
- A 2 4 11
- B 3 5 15
于是, 我们可以按照下面的方式来进行操作.
- df = (df.groupby('Name', as_index=False)
- .agg({'Missed':'sum', 'Credit':'sum','Grade':'mean'})
- .rename(columns={'Missed':'Sum1', 'Credit':'Sum2','Grade':'Average'}))
参考资料: Python pandas: mean and sum groupby on different columns at the same time
高级分组-不同列执行不同操作例子
对于一些表格中含有较多的列元素的时候, 我们可以首先建立一个字典类型数据, 接着应用到dataframe上即可. 我们看一下下面的例子.
首先我们建立一个字典, 为index名称对应执行的操作(就是可以在这里建立一个字典, 方便我们后续的操作).
- dict_groupby = {i:'sum' for i in confirm.columns.values[4:]}
- dict_groupby['Lat'] = 'mean'
- dict_groupby['Long'] = 'mean'
- dict_groupby
例如, 在这里建立的字典最终的结果大致如下.
- {...
- '5/9/20': 'sum',
- '5/10/20': 'sum',
- '5/11/20': 'sum',
- 'Lat': 'mean',
- 'Long': 'mean'}
接着, 我们对每一个table应用上面的dict即可.
- # confirmed cases
- confirmCountry = confirm.groupby('Country/Region').agg(dict_groupby)
- # confirmCountry.drop('Cruise Ship', inplace=True)
- confirmCountry.head()
上面就完成了对confirmed这个表格数据各省的合并.
Map的使用
我们有时需要给dataframe添加一列, 这一列可能和前面的有关系, 我们就可以使用Map的这个功能. 例如下面对的例子, 我们希望增加一列'E', 这一列是前面列'D'数字的平方, 我们就可以使用下面的方式来进行添加.
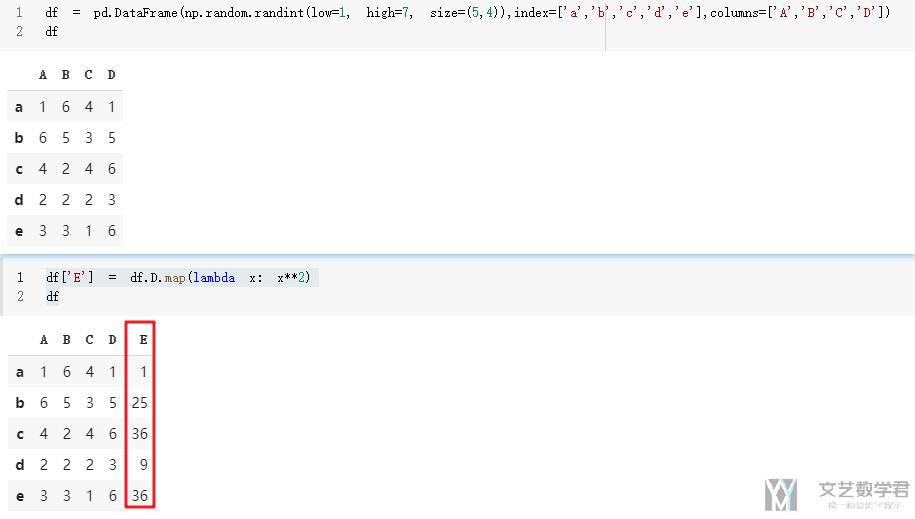
Apply与Transform的使用
这里简单介绍一下Apply和transform的使用。这个在处理数据的时候是很常用的一个功能。
我们生成一些测试的数据。
- df = pd.DataFrame(np.random.randint(low=0, high=10, size=(5,4)),index=['a','b','c','d','e'],columns=['A','B','C','D'])
- df

我们新生成一列,其数值是前面四列进行求和. (这个是apply的一个简单的使用), 按照下面的写法, 其实执行的时候是一行一行执行的.
- df['E'] = df.apply(lambda x : x['A']+x['B']+x['C']+x['D'], axis=1)
- df
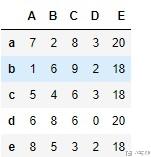
接着,我们对E这一列进行groupby,并计算一个group中D的不同的数字出现的个数。
- # 这里是对E进行groupby, 计算一个group种D出现的次数
- df['F'] = df.groupby('E')['D'].transform('nunique')
- df
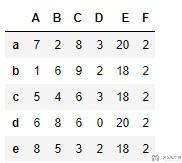
如上图中,使用groupby('E')会把b, c, e分为一类, 其中的D的取值为2, 3, 2, 有两种取值, 所以最后b, c, e中的F是2.
文件的读取和保存
文件的读取
- header=None : 不把第一行作为header
- index_col=0 : 把第一列作为index
- name=['ID'] : 给导入的表格的header起名字,默认是0,1,2,3...
- sep: 文件的分隔符
- pd.read_csv(proFile, header=None, index_col=0, names=['ID', 'prob'])
文件的保存
如果我们保存的时候不需要保存index和header,就全部设置为False
- file.to_csv('mysubmission.csv', header=False, index=False)
pandas与numpy互相转换
- dataframe转换为numpy: df=df.values
- numpy转换为dataframe: df = pd.DataFrame(df)
参考链接: Pandas中把dataframe和np.array的相互转换
一些关于数据预处理
关于如何将数据转换为one-hot数据, 等一些其他的数据预处理的操作, 可以查看下面的链接: Pandas One-Hot操作
时间数据处理
从str转换为datetime格式
有的时候, 在pandas中的内容都是string格式的, 为了要进行时间的相关操作, 我们需要转换为datetime格式的.
- df = pd.read_excel('上班时间.xlsx', encoding='utf-8')
- a = pd.to_datetime(df['上班时间'], format="%H:%M:%S")
- b = pd.to_datetime(df['下班时间'], format="%H:%M:%S")
这样的数据是Timedelta的数据, 我们可以将其转换为分钟或是小时为单位的数据.
- df['minute'] = [times/pd.Timedelta('1 minute') for times in (b-a)]
- df['hour'] = [times/pd.Timedelta('1 hour') for times in (b-a)]
时间序列的基本操作
我们这里创建一个简单的时间序列,在演示一下基本的用法:
from datetime import datetime
dates = [datetime(2018, 1, 1), datetime(2018, 1, 2), datetime(2018, 1, 3), datetime(2018, 1,4)]
ts = Series(np.random.randn(4), index=dates)
>>
2018-01-01 -1.959113
2018-01-02 -1.637479
2018-01-03 0.833776
2018-01-04 0.546243
dtype: float64我们有多种方式可以选择元素,只要传入一个可以被pandas识别的日期字符串就可以了。
ts['2018/1/1']
>> -1.9591133192825554
ts['2018-1-1']
>> -1.9591133192825554上面我们生产日期的方式是需要一个一个输入的,当然除了这种方式,还可以使用pandas.data_range来完成,该函数主要有下面的几个参数:
- start: 指定了日期范围的起始时间;
- end: 指定了日期范围的结束时间;
- periods: 指定了间隔范围,如果只是指定了
start和end日期的其中一个,则需要改参数; - freq: 指定了日期频率,比如
D代表每天,H代表每小时,M代表月,这些频率字符前也可以指定一个整数,代表具体多少天,多少小时,比如5D代表5天。还有一些其他的频率字符串,比如MS代表每月第一天,BM代表每月最后一个工作日,或者是频率组合字符串,比如1h30min代表1 小时 30 分钟
pd.date_range('2018','2019',freq='M')
>>
DatetimeIndex(['2018-01-31', '2018-02-28', '2018-03-31', '2018-04-30',
'2018-05-31', '2018-06-30', '2018-07-31', '2018-08-31',
'2018-09-30', '2018-10-31', '2018-11-30', '2018-12-31'],
dtype='datetime64[ns]', freq='M')当然,我们有时候还需要进行采样,比如原始数据是每分钟进行采样,我们想要变成每天进行采样,于是就可以使用resample方法。
dates = pd.date_range('2018-1-1', '2018-1-2 23:00:00', freq='H')
ts = Series(np.arange(len(dates)), index=dates)
ts.size
>> 48我们先使用resample('D')方法指定了按天统计,接着使用sum方法指定了最终数据是按天的所有数据的和进行统计。
ts.resample('D').sum()
>>
2018-01-01 276
2018-01-02 852
Freq: D, dtype: int64当然我们也可以按天的所有数据的平均数进行统计:
ts.resample('D').mean()
>>
2018-01-01 11.5
2018-01-02 35.5
Freq: D, dtype: float64当然,resample('D')除了可以把高频转为低频,还可以把低频转为高频,默认情况下 Pandas 会引入NaN值,因为没办法从低频率的数据计算出高频率的数据,但可以通过fill_method参数指定插值方式:
ts.resample('D').mean().resample('H').ffill()
>>
2018-01-01 00:00:00 11.5
2018-01-01 01:00:00 11.5
....
2018-01-01 20:00:00 11.5
2018-01-01 21:00:00 11.5
2018-01-01 22:00:00 11.5
2018-01-01 23:00:00 11.5
2018-01-02 00:00:00 35.5
Freq: H, dtype: float64注意上面的ffill表示用前面的值代替NaN
Pandas 绘图
关于 pandas 的绘图,可以参考其官方的页面,pandas.DataFrame.plot
基础绘图
我们只需要对于基础的 DataFrame 格式的数据,在后面加上 plot 即可进行绘制。
- x = np.arange(-3, 3, 0.05)
- y1 = x
- y2 = x ** 2
- y3 = np.sin(x)
- data = pd.DataFrame(np.array([y1, y2, y3]).T, columns=['x', 'x^2', 'sin(x)'], index=x)
- data.plot()
- plt.show()
这里 data 的数据样式为:
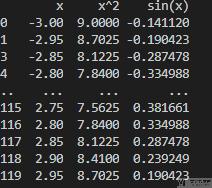
最终绘制的结果如下所示:
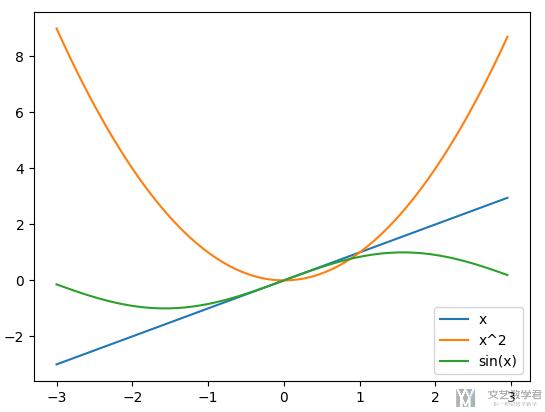
设置标题,label等
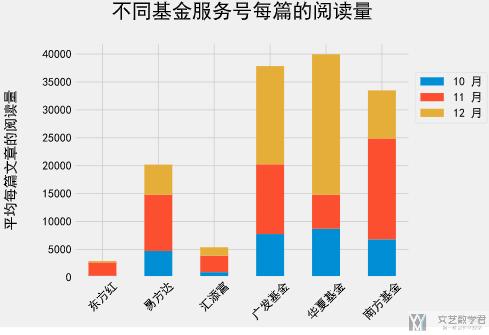
我们可以通过下面的方式设置图像的标题和label,也可以设置图例。
- matplotlib.style.use('fivethirtyeight') # bmh
- ax = readcount_per.T.plot.bar(rot=45, stacked=True)
- ax.set_ylabel("平均每篇文章的阅读量", labelpad=30)
- ax.legend(bbox_to_anchor=(1.0, 0.9)) # 设置图例的位置
- ax.set_title(u'不同基金服务号每篇的阅读量', fontsize=24, pad=30) # 设置标题
最终的效果如下所示:
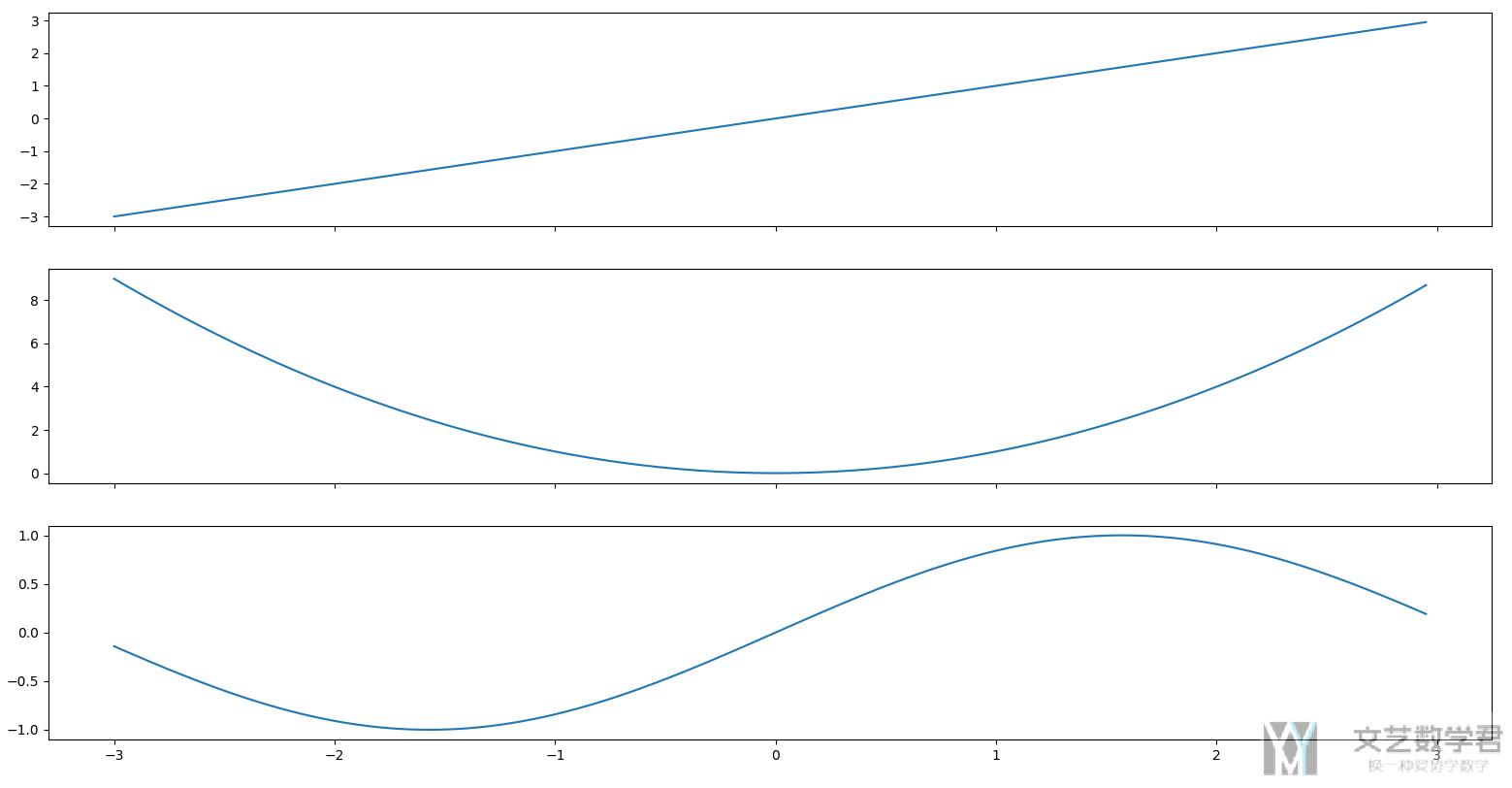
绘制子图
还是对于上面的数据,我们将三条折线图绘制在三个子图里面。我们只需要在 plot 的后面指定 ax 即可。
- fig, axs = plt.subplots(3, 1, figsize=(10, 12), facecolor='w', edgecolor='k', sharex=True)
- data.iloc[:,0].plot(kind='line', ax=axs[0])
- data.iloc[:,1].plot(kind='line', ax=axs[1])
- data.iloc[:,2].plot(kind='line', ax=axs[2])
- plt.show()
最终的效果如下所示,这里的子图是共享横坐标的:
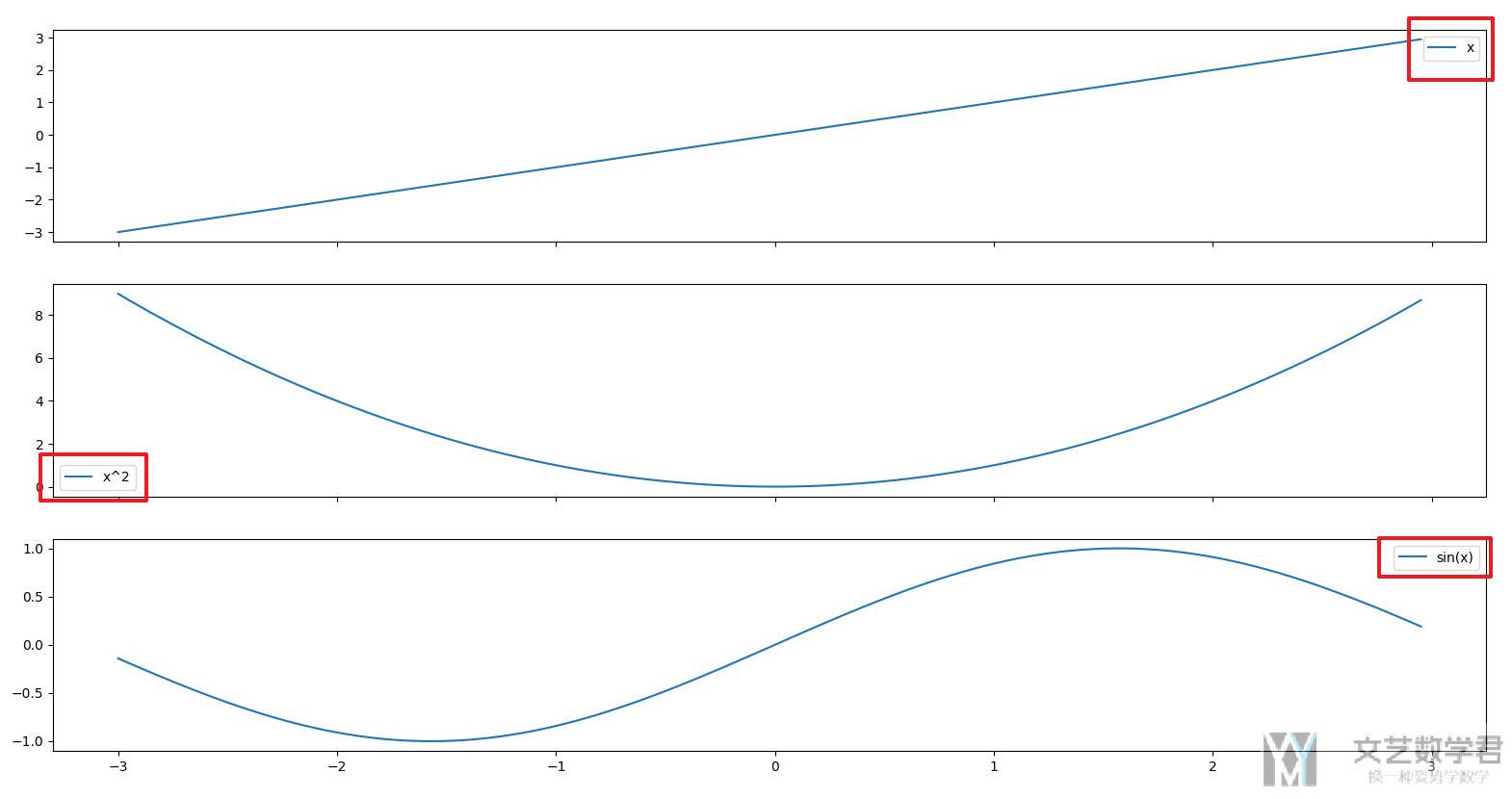
设置 legend
我们可以通过直接添加legend=True 来增加 legend。还是使用上面的例子。
- fig, axs = plt.subplots(3, 1, figsize=(10, 12), facecolor='w', edgecolor='k', sharex=True)
- data.iloc[:,0].plot(kind='line', ax=axs[0], legend=True)
- data.iloc[:,1].plot(kind='line', ax=axs[1], legend=True)
- data.iloc[:,2].plot(kind='line', ax=axs[2], legend=True)
- plt.show()
可以看到最终的效果图是有 legend 的。
调整 xticks 的大小和角度
有的时候 xticks 会比较长,我们希望他们有一些旋转可以放得下结果。这个时候可以使用 rot 参数。同时可以通过 fontsize 来调整字体的大小。
- data.iloc[:,0].plot(kind='line', ax=axs[0], legend=True, rot=60, fontsize=23)
- data.iloc[:,1].plot(kind='line', ax=axs[1], legend=True, rot=60, fontsize=23)
- data.iloc[:,2].plot(kind='line', ax=axs[2], legend=True, rot=60, fontsize=23)
可以看到下图中的 xticks 和 yticks 的字体大小变大了,同时 xticks 也出现的倾斜。
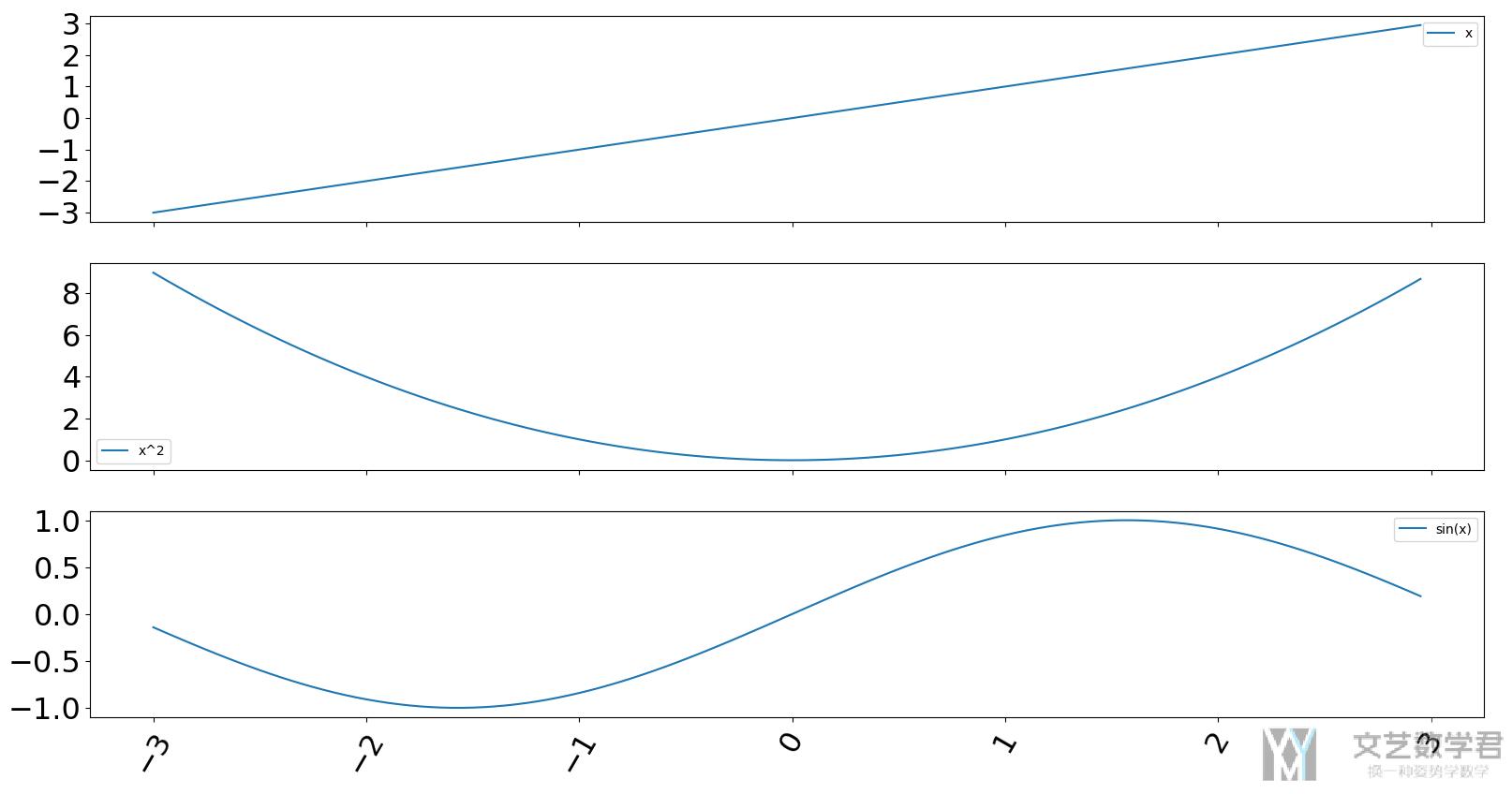
调整 xticks 的内容
除了上面调整 xticks 的样式之外,我们还可以直接调整 xticks 中的内容。可以直接传入 list 即可。
- fig, axs = plt.subplots(3, 1, figsize=(10, 12), facecolor='w', edgecolor='k', sharex=True)
- data.iloc[:,0].plot(kind='line', ax=axs[0], legend=True, rot=60, fontsize=23, yticks=[1,2], xticks=[-2.5, -1.5, 0, 1.5, 2.5])
- data.iloc[:,1].plot(kind='line', ax=axs[1], legend=True, rot=60, fontsize=23)
- data.iloc[:,2].plot(kind='line', ax=axs[2], legend=True, rot=60, fontsize=23)
- plt.show()
这时候绘制出来的结果可以看到 xticks 就已经发生改变了。
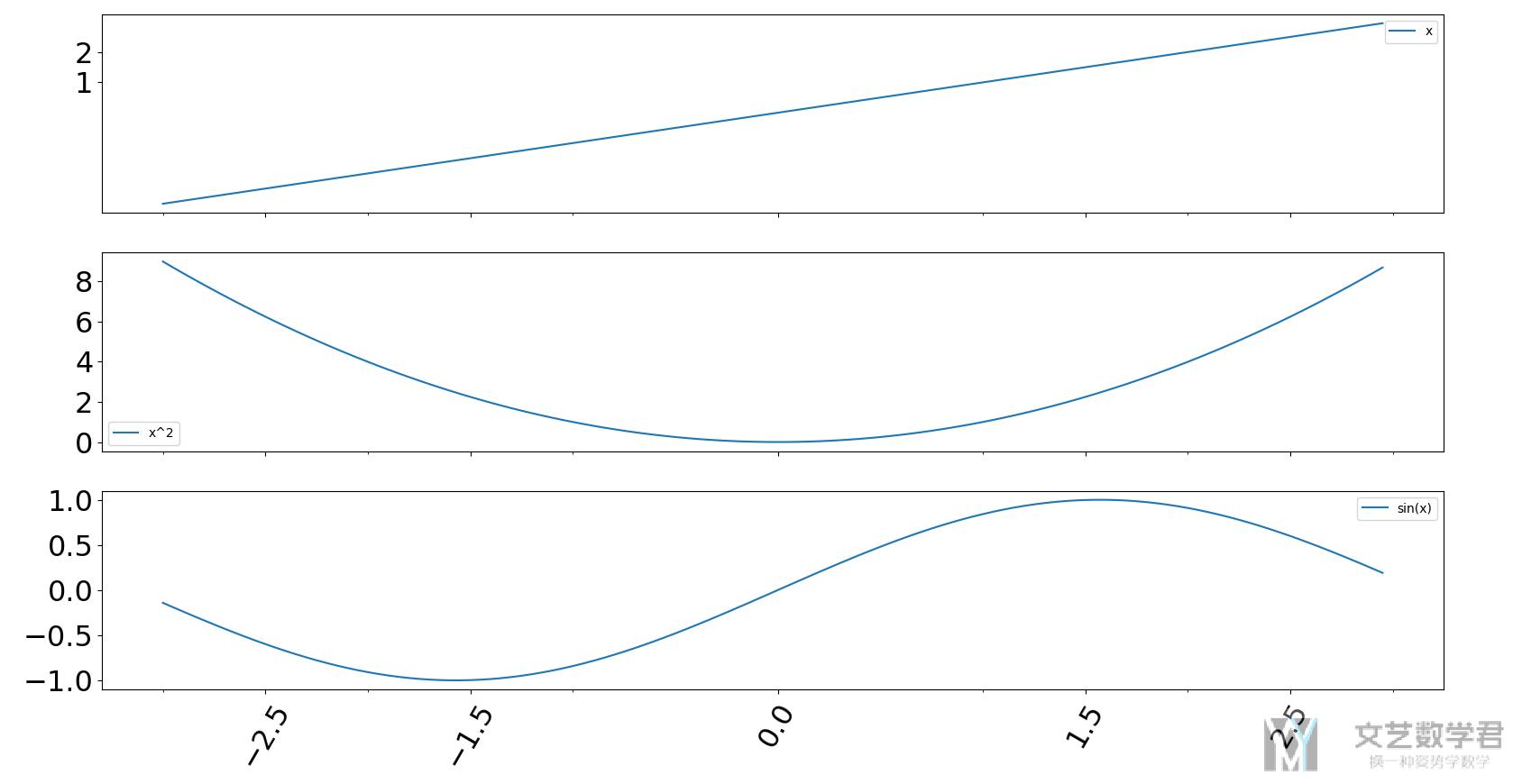
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-










评论