文章目录(Table of Contents)
简介
这一篇整理一下关于Phishing detction相关的论文. 简述一下其中使用的数据集, 使用的检测方法和相关的创新点.
An Assessment of Features Related to Phishing Websites using an Automated Technique
- Mohammad, Rami M., Fadi Thabtah, and Lee McCluskey. "An assessment of features related to phishing websites using an automated technique." In 2012 International Conference for Internet Technology and Secured Transactions, pp. 492-497. IEEE, 2012.
这篇文章主要介绍了对于Phishing websites来进行自动化的特征提取. 会详细介绍每一个特征是什么. 同时, 我们会结合数据集UCL-Phishing Websites Data Set, 结合该数据集中的特征, 一起进行说明.
对于这个处理好的数据集, 使用Decision Tree来进行分类, Detecting phishing websites using a decision tree
Phishing特征的详细说明
在这一篇文章中, 会提取4种类型的Phishing Websites的特征. 同时, 后面作者还补充了一些特征, 最后合起来一共有30个特征, 我们在这里一并进行介绍.
Address Bar Based Features
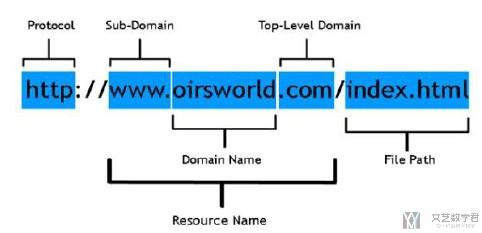
首先在介绍详细的特征之前, 先介绍几个概念:
- url: http://www.baidu.com/s?wd=12&rsv_spt=1&rsv_iqid=0xfd234c8700018f0e&issp=1&f=8&rsv_bp=0&rsv_idx=2&ie=utf-8&rqlang=&tn=baiduhome_pg&ch=
- hostname: baidu.com
- domain: 包括上面hostname的详细信息, 例如注册时间, 过期时间, 更新时间等.
下面是特征的介绍.
1). Using the IP Address: url是否只是IP地址而没有域名, 例如"http://125.98.3.123/fake.html", 或是被转换为十六进制的编码"http://0x58.0xCC.0xCA.0x62/2/paypal.ca/index.html".
2). Long URL to Hide the Suspicious Part: 比较长的url, 这些url因为长度过长, 可以在address bar中隐藏可疑的部分. 作者计算他收集的url的长度, 平均值长度是54, 于是有按照下面的分类, 其中75是来自另外一篇文章.

3). Using URL Shortening Service "TinyURL": 是否是短链接. 短链接的原理, this is accomplished by means of an "HTTP Redirec" on a domain name that is short, which links to the webpage that has a long URL. 例如URL "http://portal.hud.ac.uk/" can be shortened to "bit.ly/19DXSk4".
4). URL's having @ Symbol: URL中是否包含符号@, 浏览器会忽略@前面的内容, 真正的地址在@后面. 所以若url中包含@则返回True, 否则返回False.
5). Redirecting using '//': 是否会使用'//'来进行重定向. 例如可以是一下的url, 'http://www.legitimate.com//http://www.phishing.com', 我们可以通过判断最后一个'//'出现的位置, 正常应该是6或者7.
6). Adding Prefix or Suffix Separated by -(dash) to Domain: URL中是否包含短横线(dash), 在legitimate的url里面, 很少会使用dash, 但是在恶意网站中容易出现使用dash. 例如下面这个url, http://www.Confirme-paypal.com/
7). Sub Domain and Multi Sub Domain: 例如url为hud.ac.uk, 其中ac.uk就是second-level domain. 这里是包含两个dots, 是正常的网站, 但是包含更多的dots, 则有可能是异常的.
8). HTTPS and SSL: 不仅考虑网站是否使用https, 还考虑证书的提供者(包括GeoTrust, GoDaddy, Network Solutions, Thawte, Comodo, Doster and VeriSign)和证书的年龄.
9). Domain Registration Length: 过期时间-当前时间. 一般正常的域名会提前进行续费.
10). Favicon: 网站的icon, 我们判断他是否load从同一个domain下面, 或是从另外一个domain.
11). Using Non-Standard Port: Sever端的一些端口, 例如Port 21建议关闭, Port 80建议打开.
12). The Existence of 'HTTPS' Token in the Domain Part of the URL: 恶意网站制作者可能将https加在主域名上面, 例如下面的例子, 'http://https-www-paypal-it-webapps-mpp-home.soft-hair.com/'
Abnormal Based Features
13). Request URL: 通常, 一个网站和其页面内的资源应该属于同一个域名. 例如打开mathpretty.com, 图片的加载是从img.mathpretty.com中来的. 于是这里作者定义了相同率(加载的元素是从原域名中来的), 例如是<img src='' />.

14). URL of Anchor: 比较页面的超链接的元素(a tag), 是否与本域名相同. 相同的百分比.
15). Links in <Meta>, <Script>, <Link>: 大部分正常网站<Meta>, <Script>, 和<Link>标签下的链接与主域名是相同的.
16). Sever Form Handler (SFH): 页面中提交表单后返回的内容, 如果是空,等操作则大部分是异常的. 因为提交完需要其他的操作. 同时如果提交完跳转到其他域名, 也可能是异常的, 因为大部分提交之后的操作还是同一个域名下进行处理的.
17). Submitting Information to Email: 是否会将用户信息通过邮件进行发送. A phisher might redirect the user's information to his personal email. To that end, a server-side script language might be used such as "mail()" function in PHP. One more client-side function that might be used for this purpose is the "mailto:" function.
18). Abnormal URL: The host name in URL does not match its claimed identity. (通过WHOIS进行查询)
HTML and JS based Features
19). Website Forwarding: 页面跳转(重定向次数).
20). Using onMouseOver to Hide the Link: Phishers may use JavaScript to display a fake URL in the status bar to the users.
21). Disabling Right Click: Phishers use JavaScript to disable the right click function, so that users cannot view and save the source code. (网站禁止右键的功能). For this feature, we will search for event "event.button==2" in the webpage source code and check if the right click is disabled.
22). Using PopUp Window: It's unusual to find a legitimate website asking users to submit their credentials through a popup window. (是否有通过弹窗来让用户输入信息)
23). IFrame Redirection: 恶意网站会使用IFrame标签, 同时通过消除边框, 使其呈现视觉轮廓.
Domain Based Features
24). Age of Domain: 这个特征还是从WHOIS中获得, 域名的时间越长(过期时间-创建时间), 是虚假网站的可能性越低.
25). DNS Record: This feature can be extracted from WHOIS database. For phishing sites, either the claimed identity in not recognized by WHOIS database or the record of the hostname is not founded.
26). Website Traffic: 网站的流量统计, 从Alexa database中获取数据.
27). PageRank: PageRank is a value ranging from "0" to "1". PageRank aims to measure how important a webpage is on the Internet. The greater the PageRank value the more important the webpage.
28). Google Index: 谷歌是否索引了这个网站. 也就是是否能在谷歌搜索结果中出现.
29). Number of Links Pointing to Page: 外部链接的数量. 别的网站, 或是同一个网站链接到自己的链接数量.
30). Statistical-Reports Based Feature: 一些公开的恶意的IP地址或是公开的域名. (类似于黑名单)
Malicious Web Content Detection Using Machine Learning
- Desai, Anand, Janvi Jatakia, Rohit Naik, and Nataasha Raul. "Malicious web content detection using machine leaning." In 2017 2nd IEEE International Conference on Recent Trends in Electronics, Information & Communication Technology (RTEICT), pp. 1432-1436. IEEE, 2017.
本文对应的github仓库地址(可以参考其中的url特征提取的代码): Malicious Web Content Detection using Machine Learning
问题描述
- Nowadays, it is becoming very difficult to detect such vulnerabilities due to the continuous development of new techniques for carrying out such attacks. (随着技术的发展, 变得难以检测)
- In addition, not all the users are aware of the different type of exploits which attackers can take advantage of. (并非所有用户都对攻击是了解的)
- In addition, if the URL itself has signs of being a phishing URL, then the user will be protected from that website. (但是如果一个url被标记了, 那么用户就可以有所防范)
主要创新点
- Hence we use the Machine Learning approach, where the URL can be tested against a trained classifier.
- A Google Chrome extension is a very good way of ensuring easy access to the tool for the user. Since Google Chrome is the most widely used web browser throughout the world and with its popularity only increasing month-by-month, it is the best option for implementing this tool to ensure the maximum outreach. (制作了一个chrome的插件, 用来对url进行判断, 也就是说这里除了测试集以外, 还会对实际的url进行判断)
解决方法
数据集介绍: 使用了Phishing Websites Data Set, 这个数据集中包括11055条记录, 每一个记录有30维的特征.
特征的提取: 原始的数据集中有30维的特征, 但是有一些的特征提取需要从标准数据库比对, 或是从网站的服务器中获取, 这在实际检测中是不可行的. (This is because many features used some standard databases which are not accessible to us. Also, extracting some of the features seemed not possible as they demanded the extraction of data from the server of the website, which is not possible.) 所以, 在本文中, 我们选取了22个特征用来对url进行检测.
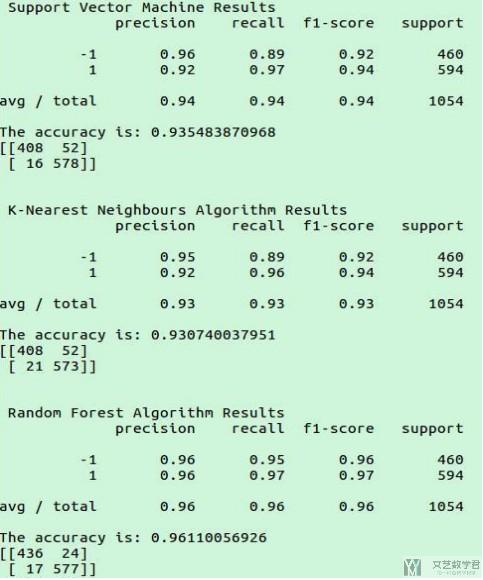
检测算法: 这里使用3种检测算法, 分别是KNN, SVM和Random Forest. 于是用22个特征结合这3种算法, 分别得到了一下的检测率, RF获得了最高的96%的检测率:
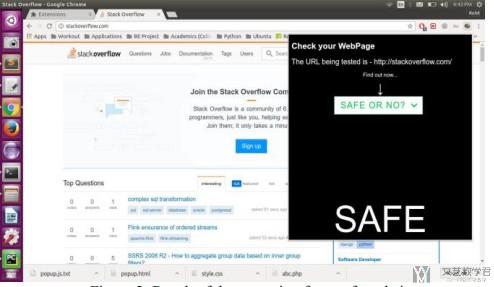
制作Google Chrome Extension: 这个插件可以获得你输入的url, 并传给python来进行判断. 最后的显示如下所示:
Detecting Phishing Websites through Deep Reinforcement Learning
- Chatterjee, Moitrayee, and Akbar-Siami Namin. "Detecting phishing websites through deep reinforcement learning." In 2019 IEEE 43rd Annual Computer Software and Applications Conference (COMPSAC), vol. 2, pp. 227-232. IEEE, 2019.
We have used our model on a balanced and labeled dataset of legitimate and malicious URLs in which 14 lexical features were extracted from the given URLs to train the model. The performance is measured using precision, recall, accuracy and F-measure. (这一篇作者在balanced的, 有标签的数据集上进行测试, 共从url中提取14个特征来训练模型) 这文章写得很一般, 但是是我找到的第一篇使用RL来解决Phishing Website的文章, 所以做一下记录.
主要创新点(这篇文章主要做的)
- Model the identification of phishing websites through Reinforcement Learning (RL), where an agent learns the value function from the given input URL in order to perform the classification task.
- Map the sequential decision making process for classification using a deep neural network-based implementation of Reinforcement Learning.
- Evaluate the performance of the deep reinforcement learning-based phishing URL classifier and compare its performance with the existing phishing URL classifiers.
主要实验记录
简单记录一下实验步骤. (这一篇文章里面有很多部分都写错了.) 不想记了, 就是用的Deep Q-Learning, 换成了phishing websites的分类问题.
其中的reward函数如下所示, 就是分类正确就是+1, 分类错误就是-1. 这里的a就是采取的action, 也就是对应做出的分类, l就是实际的label.
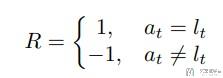
关于数据集, 作者使用了这个下面的, https://github.com/ebubekirbbr/pdd/tree/master/input. (这个仓库也是没人维护)
Smote implementation on phishing data to enhance cybersecurity
- Ahsan, Mostofa, Rahul Gomes, and Anne Denton. "Smote implementation on phishing data to enhance cybersecurity." In 2018 IEEE International Conference on Electro/Information Technology (EIT), pp. 0531-0536. IEEE, 2018.
这一篇文章是解决数据不平衡的问题. However, since most of the data packets are legitimate, the model tends to produce a bias towards positive results in this imbalanced dataset.
In this study, we investigate how prediction accuracy varies in a balanced dataset against an imbalanced one. SMOTE is applied to balance the dataset. XGBoost, Random Forest and Support Vector Machines have been applied on the phishing dataset. Results show much higher accuracy rates with SMOTE application. The highest jump in accuracy has been recorded in XGBoost from 89.87% to 97.17% showing that SMOTE is an effective tool in phishing data monitoring. (本文使用SMOTE进行数据平衡, 同时使用XGBoost, Random Forest and Support Vector Machines这三种算法来验证最终的结果)
目前存在的主要问题
However, researchers are facing an issue which is the scarcity (缺乏) of actual phishing website data compared to benign website data in training datasets. This problem leads to imbalanced and biased learning of classification which is one of the major causes of degrading the accuracy of machine learning model predictions
本文主要的贡献点
- In this paper we propose a solution to this issue by applying Synthetic Minority Over-sampling Technique (SMOTE) on the website phishing dataset to deal with the class imbalance. (使用SMOTE来解决phishing dataset的数据不平衡问题, 这篇文章会有SMOTE的介绍, 之后写background可以借鉴)
- Three machine learning techniques such as XGBoost (XGB), SVM, RF has been evaluated. (使用三种机器学习算法来进行验证)
- Results have been compared with SMOTE and without SMOTE application on them. (比较使用SMOTE前后的结果)
本文的实验
本文使用的数据集是来自UCI Machine Learning Repository. 这里是一个三分类, 分别是Legitimate, Suspicious and Phishy. 这三类分别对应的label是1, 0, -1.
The original dataset contained 702, 103 and 548 counts corresponding to -1, 0 and 1 class labels respectively. (这三类样本的数量分别是702, 103, 548)
同时, 需要注意的是, SMOTE只会用在训练集上面, 我们需要保持测试集是一样的. (SMOTE was applied on training dataset only. This ensured that the testing dataset had original values.)
实验结果
作者使用XGBoost来进行比较, 使用SMOTE和不使用, 分别可以得到下面的结论.
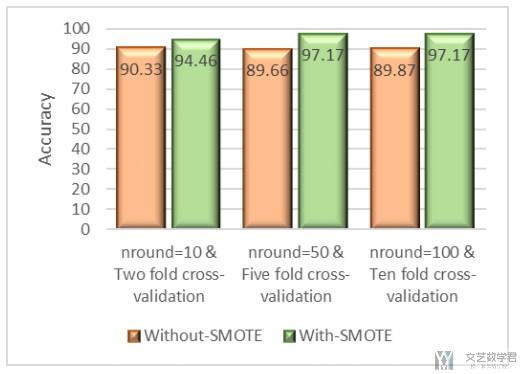
Accuracy without SMOTE was 89.87%. After SMOTE application the accuracy surged to 97.17% showing that XGBoost is highly impacted by SMOTE.
之后, 同样的实验作者也是使用了SVM和Random Forest来完成, 得到的结果都是使用SMOTE做数据平衡之后, 会明显改善分类的效果.
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论