文章目录(Table of Contents)
Hadoop简介
我就挑一些重点来讲:
Hadoop的框架最核心的设计就是:HDFS和MapReduce。 HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
- Hadoop 通用模块(Hadoop Common): 为其他 Hadoop 模块提供支持的公共实用程序。
- Hadoop 分布式文件系统(HDFS, Hadoop Distributed File System):提供对应用程序数据的高吞吐量访问的分布式文件系统(承载框架的数据存储需求)。
- Hadoop YARN: 任务调度和集群资源管理框架。
- Hadoop MapReduce: 基于 YARN 的大规模数据集并行计算框架(满足框架计算需求)。
- HBase:一个可伸缩的、支持大表的结构化数据存储的分布式数据库。
- Hive:提供数据汇总和临时查询的数据仓库基础框架。
- Pig:用于并行计算的高级数据流语言和执行框架。
- ZooKeeper:适用于分布式应用的高性能协调服务。
- Spark:一个快速通用的 Hadoop 数据计算引擎,具有简单和富有表达力的编程模型,支持数据 ETL(提取、转换和加载)、机器学习、流处理和图形计算等方面的应用。
Hadoop的部署
关于在win上部署Hadoop,可以参考下面这一篇文章:
我下面简单叙述一下:
安装依赖环境
首先我们需要安装Java环境,并配好Java的环境变量:
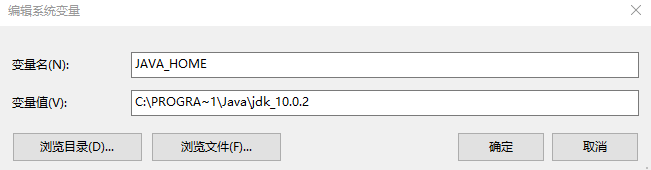
注意这里环境变量路径的设置,由于不能出现空格,故写成下面的样子:
环境变量可以用特殊的字符PROGRA~1代替从而达到替换空格方便使用的目的
Hadoop文件下载与解压
我们在官网下载Hadoop并进行解压;
同时我们需要下载一个winutils,之后会有用到,下载地址:winutils下载:
下载完是下面这个样子的,我们在下载Hadoop的时候也注意下,下载的版本最好在winutils中也有;
修改配置文件
接下来要修改 ./etc/hadoop下的一些配置文件
首先是core-site.xml:
- <configuration>
- <property>
- <name>fs.default.name</name>
- <value>hdfs://localhost:9000</value>
- </property>
- </configuration>
接着是修改hdfs-site.xml:
- <configuration>
- <!-- 这个参数设置为1,因为是单机版hadoop -->
- <property>
- <name>dfs.replication</name>
- <value>1</value>
- </property>
- <property>
- <name>dfs.permissions</name>
- <value>false</value>
- </property>
- <property>
- <name>dfs.webhdfs.enabled</name>
- <value>true</value>
- </property>
- <property>
- <name>dfs.namenode.name.dir</name>
- <value>/D:/hadoop/data/namenode</value>
- </property>
- <property>
- <name>fs.checkpoint.dir</name>
- <value>/D:/hadoop/data/snn</value>
- </property>
- <property>
- <name>fs.checkpoint.edits.dir</name>
- <value>/D:/hadoop/data/snn</value>
- </property>
- <property>
- <name>dfs.datanode.data.dir</name>
- <value>/D:/hadoop/data/datanode</value>
- </property>
- </configuration>
接着修改yarn-site.xml:
- <configuration>
- <!-- Site specific YARN configuration properties -->
- <property>
- <name>yarn.nodemanager.aux-services</name>
- <value>mapreduce_shuffle</value>
- </property>
- <property>
- <name>yarn.log-aggregation-enable</name>
- <value>true</value>
- </property>
- <!--日志保留时间,单位秒-->
- <property>
- <name>yarn.log-aggregation.retain-seconds</name>
- <value>86400</value>
- </property>
- </configuration>
接着修改mapred-site.xml:
在这里初始情况下文件名为mapred-site.xml.template,这时是不会启动 YARN的;
这是因为YARN 主要是为集群提供更好的资源管理与任务调度,然而这在单机上体现不出价值,反而会使程序跑得稍慢些。
- <configuration>
- <property>
- <name>mapreduce.framework.name</name>
- <value>yarn</value>
- </property>
- </configuration>
最后修改hadoop-env.sh:
加上下面这个:
- export JAVA_HOME=${JAVA_HOME}
Hadoop的启动
初始化HDFS
首先我们要对HDFS进行初始化,输出一下的命令:
hdfs namenode -format
启动Hadoop
我们需要进入hadoop/sbin目录,在终端执行下面两个文件:
- start-dfs.cmd
- start-yarn.cmd
此时Hadoop就算是启动完成了;
我们可以在浏览器中输入以下网址进行查看:http://localhost:50070
Note(注意!!):2.x的版本中文件管理的端口是50070,在3.0.0中替换为了9870端口;
Hadoop测试
在启动之后,我们就可以进行一些HDFS的基本操作了,我就演示一个(就是只截图一个,其余的把命令列在下面,方便查找和参考)
导入文件
hadoop fs -put D:/a.txt /hadoop_learn
- 也可以两个文件一起上传
hadoop fs -put D:/a.txt D:/b.txt /hadoop_learn/
删除文件(夹)
hadoop fs -rm -r /hadoop_learn
文件与文件夹操作
文件操作
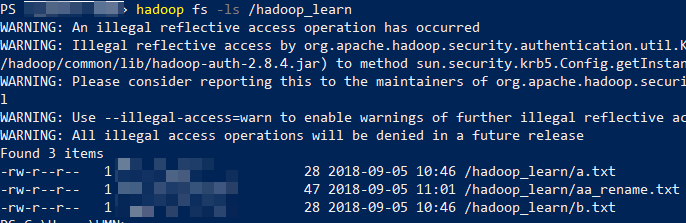
- 使用 -ls 列出指定目录中的文件
hadoop fs -ls /hadoop_learn
- 使用 -cat 查看某个文件的内容
hadoop fs -cat /hadoop_learn/a.txt
同时使用 file://开头可以访问本地的文件(不要忘记再加一个/),否则任何写到此的路径都会被识别为HDFS上的路径;
hadoop fs -cat file:///D:/b.txt
- 可以同时查看多个文件
hadoop fs -cat /hadoop_learn/a.txt file:///D:/b.txt
- 使用 -cp 进行文件的复制
hadoop fs -cp /hadoop_learn/a.txt /aa.txt
- 使用 -mv 进行文件的移动
hadoop fs -mv /aa.txt /hadoop_learn/
- 使用 -appendToFile 进行文件的追加
hadoop fs -appendToFile D:/c.txt /hadoop_learn/aa.txt
- 使用 -tail 查看文件末尾,查看是否添加成功
hadoop fs -tail /hadoop_learn/aa.txt
- 使用 -rm -r 删除文件(文件夹)
hadoop fs -rm /hadoop_learn/aa.txt
目录操作
- 使用 -mkdir 进行目录的创建
hadoop fs -mkdir /hadoop_learn
- 使用 -mkdir -p 时, 若父目录不存在,会被自动创建;
hadoop fs -mkdir -p /hadoop_learn/test/test
- 使用 -du 查看每个目录占用多少空间
hadoop fs -du /hadoop_learn/
导出文件
- 使用 -get 参数将其导出到Linux本地目录
hadoop fs -get /hadoop_learn/aa.txt D:/
参考资料
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论