文章目录(Table of Contents)
简介
这一篇简单介绍一下Spark SQL的基本概念,并且简单利用SQL Context进行统计分析。这一篇会直接使用一个例子进行分析;
例子分析
对于Spark SQL来说,程序的入口便是SQL Context类(或是该类的子类)。创建一个SQLContext对象,需要使用SparkContext;

要分析的文件我们已经准备好并且放在 /home/hadoop/SPY_2016.csv中;
文件中的字段如下所示:
- Date:交易日期
- Open:开盘价
- High:交易日最高价
- Low:交易日最低价
- Close:收盘价
- Volume:成交量
- Adj Close:调整后的收盘价
定义Case Class
首先我们定义一个Case Class来映射csv中每个字段;
- case class Stock(date: String, openPrice: Double, highPrice: Double, lowPrice: Double, closePrice: Double, volume: Double, adjClosePrice: Double)

定义解析csv的函数
接着我们定义一个用于解析csv的函数,原理即是使用逗号将csv的每一行进行分割,然后转换为Stock数据类型;
- def parseDataset(str: String): Stock = {
- val line = str.split(",")
- Stock(line(0), line(1).toDouble, line(2).toDouble, line(3).toDouble, line(4).toDouble, line(5).toDouble, line(6).toDouble)
- }

定义转换为RDD的函数
这里继续定义一个函数,将paraseData函数的返回值转换为RDD,并缓存下来;
- // map函数会将 parseData 函数作用于文件中的每一行
- def parseRDD(rdd: RDD[String]): RDD[Stock] = {
- rdd.map(parseDataset).cache()
- }

将文件导入DataFrame
- val spyDF = parseRDD(sc.textFile("/home/hadoop/SPY_2016.csv")).toDF.cache()
查看一下是否导入成功,使用spyDF.show()进行展示;
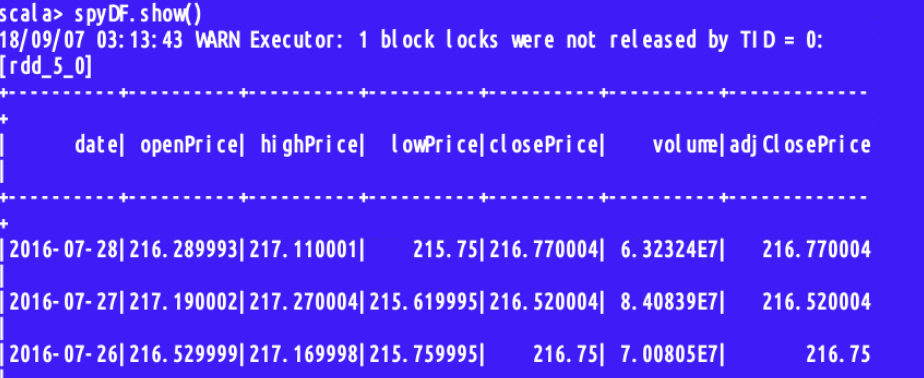
下面进行简单的统计操作;
查找部分与分类汇总
- val spyQueryResult = spyDF.select(year($"date").alias("year"), $"adjClosePrice")
首先是查询的代码,在这里$表示用于标记列名,alias为查询结果的字段起一个别名;
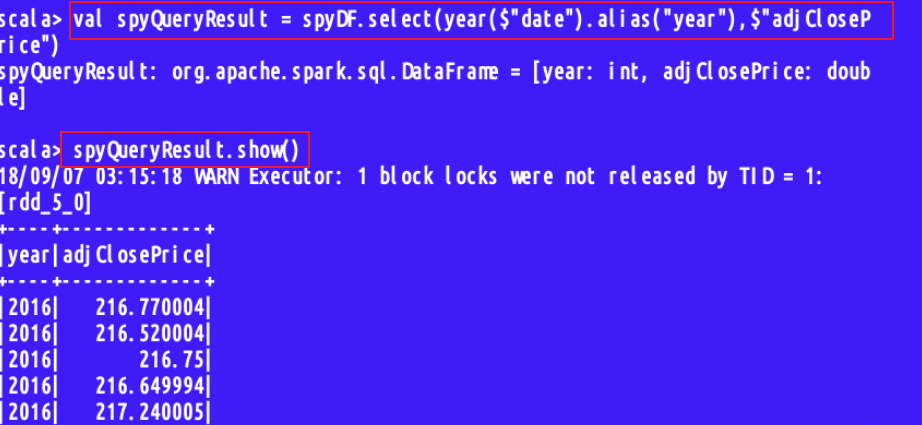
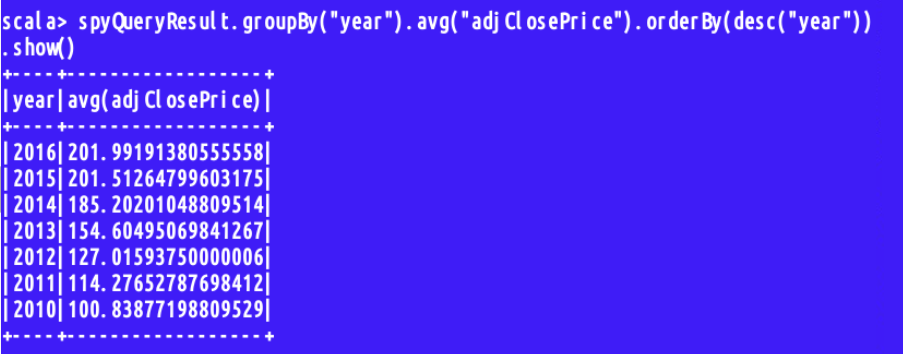
接下来我们使用groupby进行分类汇总,最后进行排序(desc为降序,asc为升序)
- spyQueryResult.groupBy("year").avg("adjClosePrice").orderBy(desc("year")).show()
注册临时表
在上面的操作中,我们对DataFrame使用了各种SQL的API,但是这样做在大量查询时需要编写很多的代码;
我们可以将DataFrame注册成一个临时表(使用registerTempTable进行临时表的注册),然后使用完整的SQL语句进行分析;
- spyDF.registerTempTable("spy")
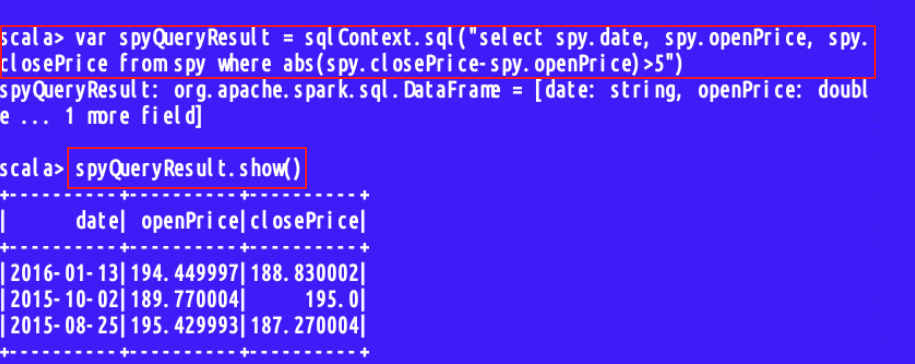
接下来我们就可以通过SQL语句进行查看了;
- var spyQueryResult = sqlContext.sql("SELECT spy.date, spy.openPrice, spy.closePrice
- FROM spy
- WHERE abs(spy.closePrice - spy.openPrice) > 5 ")
结果的储存
对于上面查询的结果,我们可以永久储存在硬盘上:
常见的保存格式有csv, json, parquet(这个是可以通过Apache Parquet进行管理)等;
- spyQueryResult.write.format("parquet").save("/home/hadoop/test.parquet")
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论