文章目录(Table of Contents)
简介
因为最近自己要使用Colaboratory(Colaboratory使用介绍)来跑一些实验, 但是在实际操作的时候会发现, 如果是直接将大量的图片存储在Google driver上面, 那么反复的读取所花费的时间会比较大. 所以, 这里我想到的方法是, 将图片和label都在本地处理好, 存储为npy的格式, 接着将npy文件上传到Google driver进行操作即可.
这里简单说明以下如何将图片转换为npy格式, 以及最后使用npy的简单的训练过程.
关于更加详细的内容, 可以参考github的链接, 在Colaboratory训练注意事项, Npy文件生成测试
本地数据集保存为npy格式
准备工作
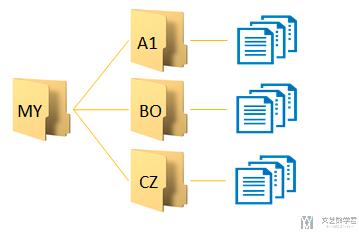
首先我们要在本地完成将数据集保存为npy的格式, 首先看一下我现在的目录结构, 目录结构如下所示. 外面是一个总的文件夹, 里面每一个label的内容都单独存储在一个文件夹内.
开始转换, 图片转换为npy格式
有了上面的数据之后, 下面我们开始进行转换. 我们希望最后可以生成4个npy文件, 分别是:
- t10k-labels-idx1, 测试集标签
- t10k-images-idx3, 测试集数据
- train-labels-idx1, 训练集标签
- train-images-idx3, 训练集数据
在实现的时候, 我们的想法是这样的:
- 首先遍历根目录下所有子目录和其中的文件
- 将内容与label一起保存在numpy中
- 打乱顺序
- 输出四个文件.
于是可以写成下面两个函数. 首先是一个辅助的函数, 用来返回label的. 例如文件夹内容为dog, cat, 最后可以范围对应关系, {'dog':0, 'cat':1}.
- def image_label(imageLabel, label2idx, i):
- """返回图片的label
- """
- if imageLabel not in label2idx:
- label2idx[imageLabel]=i
- i = i + 1
- # 返回的是字典类型
- return label2idx, i
接下来就是主函数, 用来将文件夹内所有的文件进行转换.
- def image2npy(dir_path='./dogs_cats/', testScale = 0.1):
- """生成npy文件
- """
- i = 0
- label2idx = {}
- data = []
- for (root, dirs, files) in os.walk(dir_path):
- for Ufile in tqdm(files):
- # Ufile是文件名
- img_path = os.path.join(root, Ufile) # 文件的所在路径
- File = root.split('/')[-1] # 文件所在文件夹的名字, 也就是label
- # 读取image和label数据
- img_data = cv2.imread(img_path)
- label2idx, i = image_label(File, label2idx, i)
- label = label2idx[File]
- # 存储image和label数据
- data.append([np.array(img_data), label])
- random.shuffle(data) # 随机打乱,直接打乱data
- # 训练集和测试集的划分
- testNum = int(len(data)*testScale)
- train_data = data[:-1*testNum] # 训练集
- test_data = data[-1*testNum:] # 测试集
- # 测试集的输入输出和训练集的输入输出
- X_train = np.array([i[0] for i in train_data]) # 训练集特征
- y_train = np.array([i[1] for i in train_data]) # 训练集标签
- X_test = np.array([i[0] for i in test_data]) # 测试集特征
- y_test = np.array([i[1] for i in test_data]) # 测试集标签
- print(len(X_train), len(y_train), len(X_test), len(y_test))
- # 保存文件
- np.save('train-images-idx3.npy', X_train)
- np.save('train-labels-idx1.npy', y_train)
- np.save('t10k-images-idx3.npy', X_test)
- np.save('t10k-labels-idx1.npy', y_test)
- return label2idx
当然, 我们也可以在上面对文件夹内的文件进行一些操作, 例如图像的放缩, 灰度化等. 可以直接在上面图像读取和保存那两个步骤中间插入, 下面看一个简单的例子.
- img_data = cv2.imread(img_path, cv2.IMREAD_GRAYSCALE) # 使用 opencv读取图像
- img_data = cv2.resize(img_data, (64, 64)) # 图片处理成统一大小
结果检查
完成上面的步骤之后, 我们可以检查以下输出的结果. 看一下图像是否有变形, 看一下label与图像是否可以对应起来. 因为我是用猫狗数据集进行测试的, 所以结果看起来还是比较方便的.
- # 随机检查label与图片是否可以对应上
- # - 从train中抽取9个image和9个label
- image_no = np.random.randint(0,3602, size=9) # 随机挑选9个数字
- train_images = np.load('./dogs_cats/train-images-idx3.npy')
- train_labels = np.load('./dogs_cats/train-labels-idx1.npy')
- fig, axes = plt.subplots(nrows=3, ncols=3,figsize=(7,7))
- for i in range(3):
- for j in range(3):
- axes[i][j].imshow(train_images[image_no[i*3+j]])
- axes[i][j].set_title(train_labels[image_no[i*3+j]])
- plt.tight_layout()
最终的输出结果如下所示, 这里的0表示cat, 1表示dog, 可以看到是可以对应起来的:

这里的图像显示有点问题, 将opencv图像使用matplotlib进行展示的时候, 需要调整颜色通道. 但是整体不影响, 我就不在这里修改了. 具体的可以参考文章, 图像处理-matplotlib显示opencv图像
使用npy结合Colaboratory进行训练
接下来, 我们将npy上传至Google driver, 并配合Colaboratory来进行模型的训练. 这里我们主要看一下创建dataloader的过程, 其他的过程可以查看github的链接, 在Colaboratory训练注意事项, Npy文件生成测试
- # 定义DataLoader
- # ---------
- # 转换为tensor
- # ---------
- X_train = torch.from_numpy(train_images.reshape(-1, 3, 64, 64)).float() # 输入 x 张量
- X_test = torch.from_numpy(test_images.reshape(-1, 3, 64, 64)).float()
- Y_train = torch.from_numpy(train_labels).long() # 输入 y 张量
- Y_test = torch.from_numpy(test_labels).long()
- print(X_train.shape, Y_train.shape)
- # ---------------
- # 创建dataloader
- # ---------------
- MINIBATCH_SIZE = 200
- trainDataset = torch.utils.data.TensorDataset(X_train, Y_train) # 合并训练数据和目标数据
- trainDataloader = torch.utils.data.DataLoader(
- dataset=trainDataset,
- batch_size=MINIBATCH_SIZE,
- shuffle=True,
- num_workers=1 # set multi-work num read data
- )
- testDataset = torch.utils.data.TensorDataset(X_test, Y_test) # 数据路径
- testDataloader = torch.utils.data.DataLoader(
- dataset=testDataset,
- batch_size=MINIBATCH_SIZE, # 批量大小
- shuffle=True, # 乱序
- num_workers=1 # 多进程
- )
最终的准确率的变化趋势:
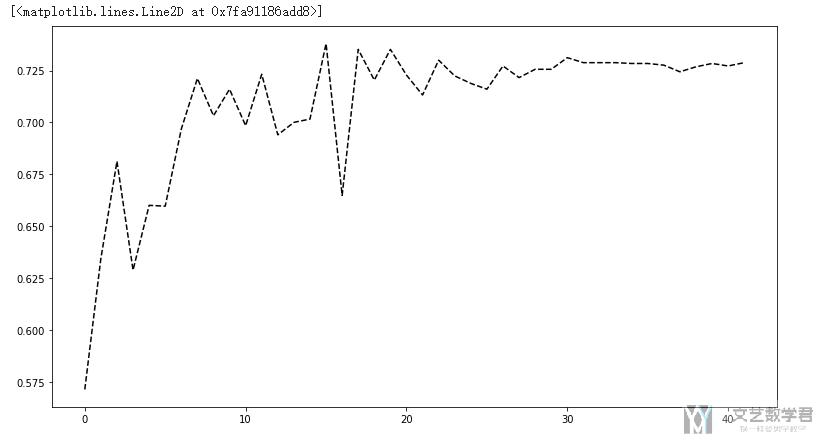
在测试集上准确率大概到72, 可以看到不是很高. 但是看训练集上准确率已经快到100了, 会有一些过拟合了, 所以还是需要自己调一下的.
- Time 2020-04-05 22:20:18.217865, Epoch [41/42], Step [29/113], loss:0.0001
- Training Accuracy: 100.0, Training Rate: 0.00022876792454961005
- Time 2020-04-05 22:20:28.220307, Epoch [41/42], Step [59/113], loss:0.0002
- Training Accuracy: 100.0, Training Rate: 0.00022876792454961005
- Time 2020-04-05 22:20:38.219144, Epoch [41/42], Step [89/113], loss:0.0001
- Training Accuracy: 100.0, Training Rate: 0.00022876792454961005
- Test Accuracy of the model on the 10000 test images: 72.88 %
因为这里只是测试npy文件的生成和训练一个整个流程, 所以就不调整了. 其余训练的完整过程查看github的地址, 在Colaboratory训练注意事项, Npy文件生成测试
参考资料
Why you should start using .npy file more often…
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论