文章目录(Table of Contents)
简介
这一篇文章主要介绍数据不平衡之后的处理方法, 会放几篇论文的方法, 和他们写作的时候的要点, 可以做一下参考. 这里主要会分为两个部分, 分别是:
- 通常情况下数据不平衡的处理
- 针对加密流量问题, 数据不平衡的处理
关于数据不平衡, 可以有以下的关键词:
- sample distribution imbalance
- imbalanced classification
关于数据不平衡的实际操作, 可以参考文章:
数据样本不平衡时处理方法(Resampling strategies for imbalanced datasets)
普遍数据不平衡的处理
Deep reinforcement learning for imbalanced classification
问题描述
- Data in real-world application often exhibit skewed class distribution which poses an intense challenge for machine learning. (现实中存在很多数据不平衡的问题)
- Conventional classification algorithms are not effective in case of imbalanced data distribution, and may fail when the data distribution is highly imbalanced. (一些分类算法在面对数据不平衡的时候可能会失效)
本文创新点
To address this issue, we propose a general imbalanced classification model based on deep reinforcement learning, in which we formulate the classification problem as a sequential decision-making process and solve it by a deep Q-learning network. (本文的主要方法是基于Deep Q-Learning来实现的)
下面是本文三个创新点的描述:
- 1) To formulate the classification problem as a sequential decision-making process and propose a deep reinforcement learning framework for imbalanced classification. (将分类问题转换为顺序决策问题, 并提出一个deep q-learning的框架来解决数据不平衡的问题)
- 2) To design and implement the DQN based imbalanced classification model (DQNimb), which mainly includes building the simulation environment, defining the interaction rules between agent and environment, and designing the specific reward function. (设计了一个基于DQN的不平衡的分类问题, 包括环境仿真, 定义主体和环境之间的相关规则, 设计奖励函数)
- 3) To study the performance of our model through experiments and compare it with other methods of imbalanced data learning. (通过实验比较实验的结果, 与其他的处理数据不平衡的方法进行比较)
关于这个方法为什么会对处理数据不平衡的问题的时候是有效的:
Our DQNimb model has the smallest decrease because our algorithm possesses both the advantages of the data level models and the algorithmic level models.
- In the data level, our model DQNimb has an experience replay memory of storing interactive data during the learning process. When the model misclassifies a positive sample, the current episode will be terminated, which can alleviate the skewed distribution of the samples in the experience replay memory. (当对少数样本分类错误的时候, episode会停止, 这样迫使其将更多的属于少数样本分类正确)
- In the algorithmic level, the DQNimb model gives a higher reward or penalty for positive samples, which raises the attention to the samples in the minority class and increases the probabilities of positive samples being correctly identified. (对属于少数样本的类别给出一个更高的reward)
解决数据不平衡的方法
在这里, 使用一个框架, Imbalanced Classification Markov Decision Process (ICMDP) framework 来解决数据不平衡的分类问题. 关于其中的一些值:
- State S: state在这里就是指样本x, 例如进行图像分类, 这里就是图片.
- Action A: action这里是模型的label, 做出预测就是做出action. 在原文中, 0 represents the minority class and 1 represents the majority class.
- Reward R: the absolute reward value of sample in the minority class is higher than that in the majority class. (在少数类的reward是要比多数类的reward要多的)
- Episode: An episode ends when all samples in training data set are classified or when the agent misclassifies a sample from the minority class. (关于一个episode的结束, 是在所有数据都能成功分类之后, 或者错误分类一个少数的样本, 这个是希望可以尽量多的将minority class分类正确, 这里结束的条件要注意)
下面详细说明一下reward function, 对于minority class和major class的不同设定.
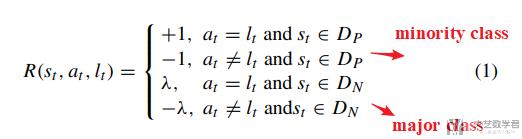
其中λ的取值是在[0,1]之间, 也就是会小于等于1, 也就是major class的reward会小. (Assume the reward value be 1 or −1 when the agent correctly or incorrectly classifies a minority class sample, be λ or −λ when the agent correctly or incorrectly classifies a majority class sample.)
关于λ的取值, 在本论文中取值为Num(D_p)/Num(D_n), 也就是少数类样本的个数/多数类样本的个数.
关于λ的取值, 为什么是Num(D_p)/Num(D_n), 可以有下面的一些解释. 首先整个模型的loss function如下所示:
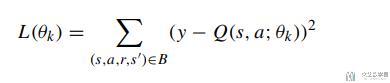
其中y是他的实际值, 也就是一步预测的值.
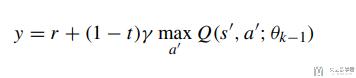
接着我们对上面的loss function进行求导, 结果如下:
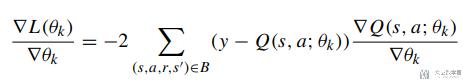
在这里因为是二分类问题, 所以y由两个部分组成, 分别是majority class和minority class, 他们获得的reward是不一样的, 所以上面的y可以拆分为下面两个式子: 其中11是minority class, 12是majority class (式子12中会乘λ).
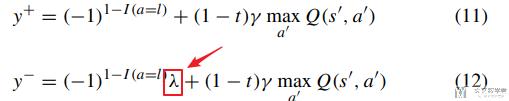
将式子11和式子12代入上面求导的式子中, 得到下面的式子13, 这个有三个部分组成: 第一部分是两类在一起的, 2和3部分分别对应majority class和minority class. 第三部分含有λ.
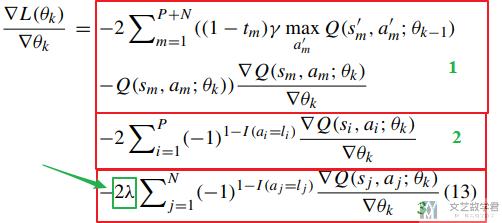
第2和第3部分的差异在于, 求和的数量不同, 如果从majority中进行取值, N的值会大于P的值, 所以需要乘λ=P/N来使得第2部分和第3部分的值相似, 来解决数据不平衡的问题.
于是, 整个算法的流程如下所示:

其中上面返回reward和terminal的算法如下所示:

本文的实验
这里作者主要进行了三大类的实验:
- 验证方法的有效性, 分类结果会比其他的处理数据不平衡的方法要好;
- 验证随着数据不平衡性的提高, 模型的准确率下降较低;
- 验证关于reward function中λ的取值;
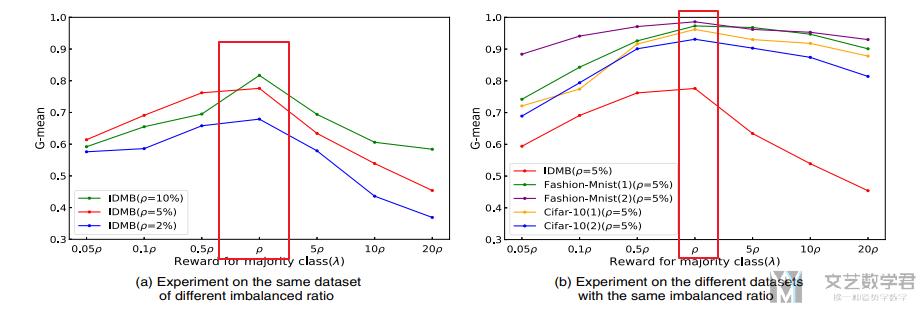
为了验证本文方法的有效性, 作者将这一种方法与其他7种处理数据不平衡的方法进行比较, 同时在6个数据集上进行测试. 部分实验结果如下图所示:
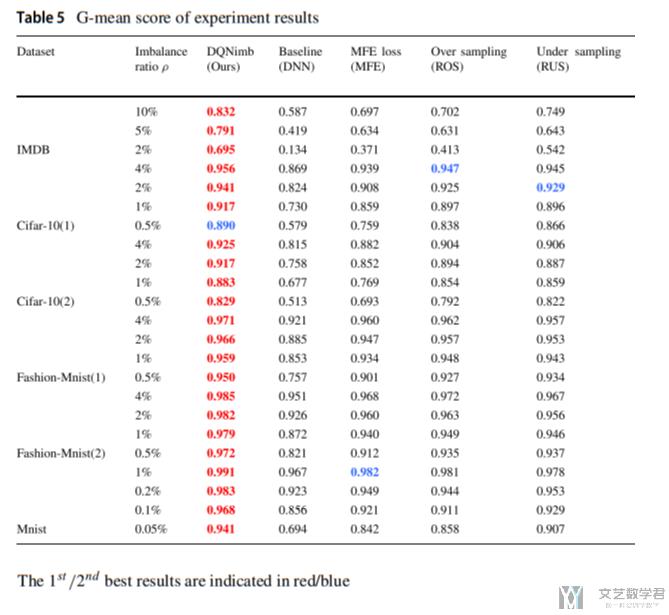
作者首先比较了数据平衡时, 模型也是有效的. 接着在数据不平衡的时候再次进行实验, 强调提出的方法的有用. (The results of data sampling methods, costsensitive learning methods, threshold adjustment method and deep imbalanced learning methods are much better than DNN model in imbalanced classification problems, however, our model DQNimb achieves an outstanding performance with an overwhelming superiority. In the IMDB text dataset, the G-mean scores of our method DQNimb are normally 5% higher than the second-ranked method CRL and significantly better than that of other methods.)
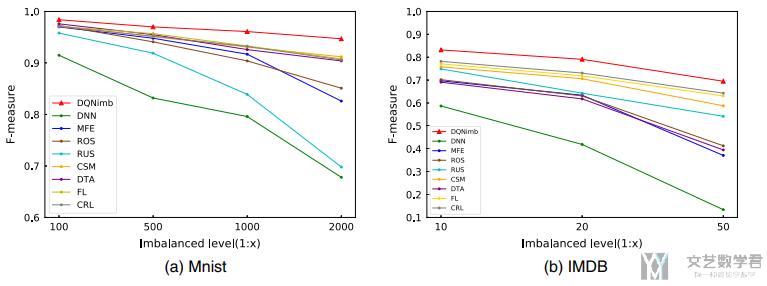
接着作者进行了另外一个实验, 增加数据的imbalance level, 来查看准确率的变化. 可以看到其他的方法都有较大程度的下降, 自己的方法准确率下降较低.
最后作者比较了λ取值不同时, 对最后结果的影响, 最后表示λ=ρ=Num(minority class)/Num(majority class)的时候, :
SMOTETomek-Based Resampling for Personality Recognition
本文主要创新点
问题来源: 因为数据不平衡造成的低准确率, (low accuracy resulting from small sample size and severe sample distribution imbalance) 更具体一点是, we analyzed the reasons for the low accuracy of user personality recognition. There are three main reasons: limited sample data, unbalanced data distribution, and serious positive and negative sample overlap.
本文在做什么: automatically classifying human personality traits through analyzing a user's text data is a challenging task considering the little existing research and low accuracy of current methods
文章主要贡献 (主要做了什么): In view of the above main problems, this paper proposes a user personality recognition method based on the SMOTETomek resampling technique. The goal of this research is to build an automatic personality recognition model based on the status of user-unbalanced text data. Hence, we propose a PSO-SMOTETomek method for personality recognition based on text so that the prediction model can be improved. The result shows that with the data balanced and features optimized, the model can classify personality traits with a relatively high accuracy. (本文的目的是提出一个基于XX人格分类的方法, 这个方法可以对于不平衡的数据自动进行分类.)
解决数据不平衡的方法
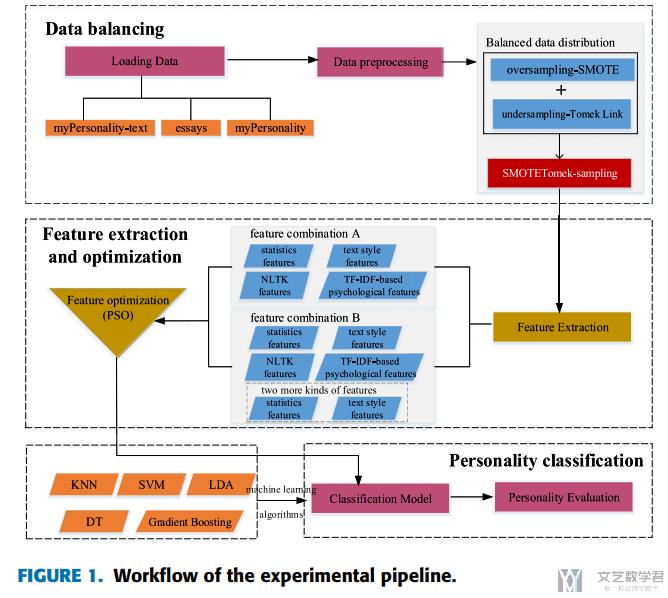
本文的主要框架如下所示, 包含三个部分:
- data balancing: it includes data loading and data preconditioning. To balance the data distribution, we adopted the SMOTETomek algorithm, which combines the oversampling method SMOTE and undersampling method Tomek Link. (这里包含解决数据不平衡的方法)
- feature extraction and optimization: In this paper, two sets of features (combination A and combination B) are extracted, and PSO optimization is performed on each. (提取了两组特征用来进行测试)
- personality classification: in order to better verify the method proposed in this paper, we used five traditional machine learning algorithms and 10-fold validation evaluation for user personality recognition (使用了5种模型来进行分析)
下面特别说明一下如何来处理数据不平衡问题. 本文使用SMOTETomek resampling来解决imbalance的问题. 分为两步来进行操作:
- Step 1: For a dataset D with an unbalanced data distribution, it uses the SMOTE method to obtain an extended dataset D' by generating many new minority samples.
- Step2: Tomek Link pairs in dataset D' are removed using the Tomek Link method.
实验结果
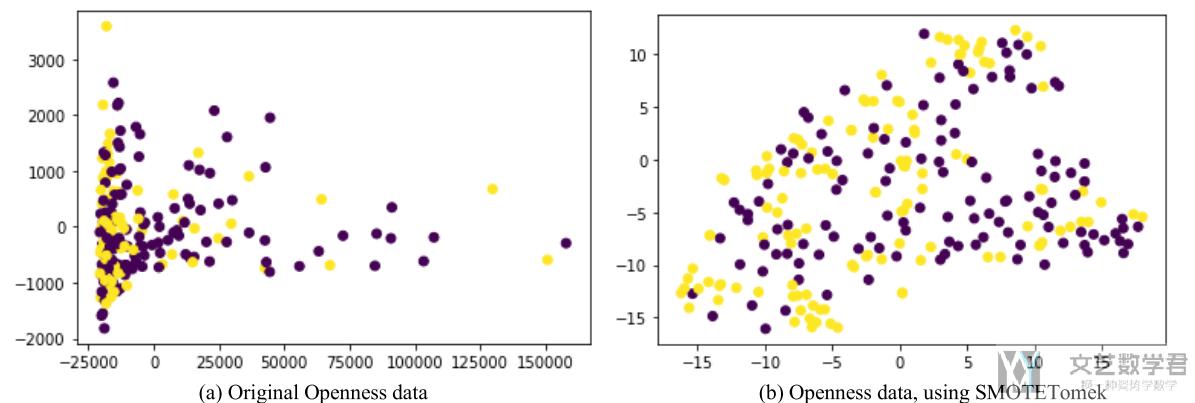
首先看一下数据分布, 我们使用t-SNE将原始数据进行降维可视化, 在使用SMOTETomek之前, overlap会比较严重, 使用之后, 数据集变得更加balanced, 同时overlap得到减少.
接着是本文做的实验种类, 本文有8种实验的场景, 分别是对应两种不同的数据集:
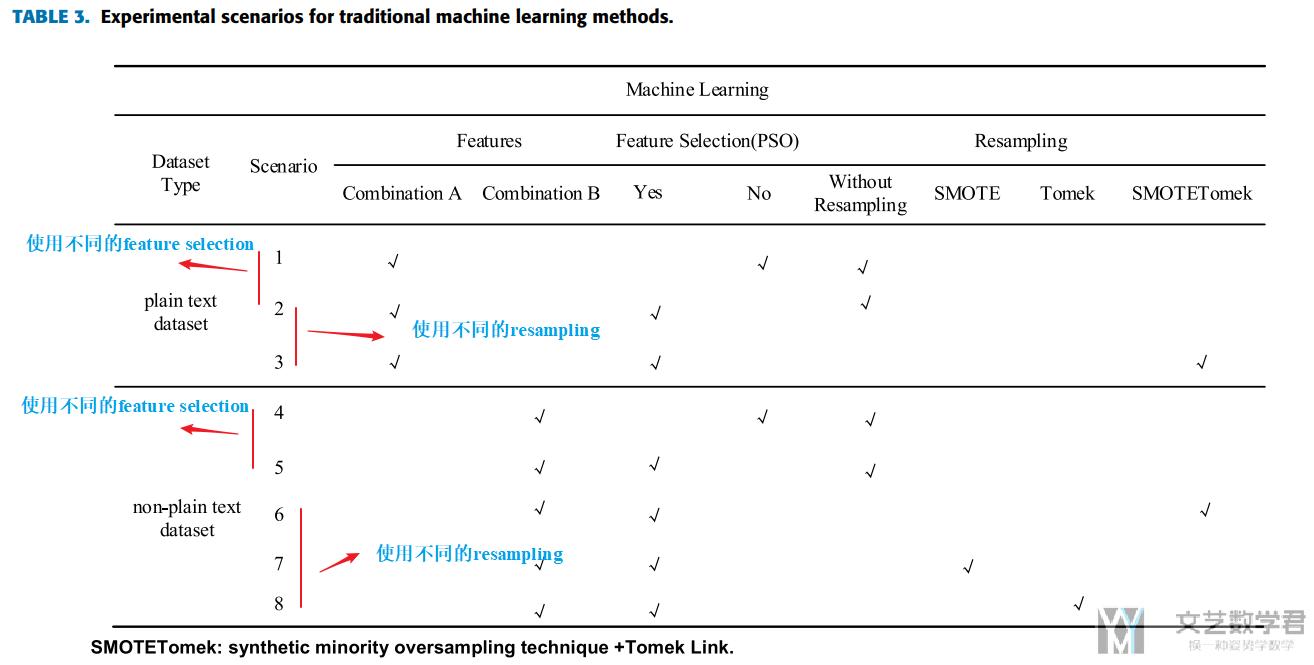
我们就看第二种数据集, 一共会有5种场景, 测试不同的可能, 同时每一种场景会使用不同的机器学习算法, 这里使用了 the decision tree (DT), support vector machine (SVM), k-nearest neighbor (KNN), gradient boosting, and linear discriminant analysis (LDA).
之后就会有对上面不同场景, 使用不同算法进行实验, 接着得到了实验结果如下表所示 (这里放的表不全, 原文包含场景4,5,6,7,8):
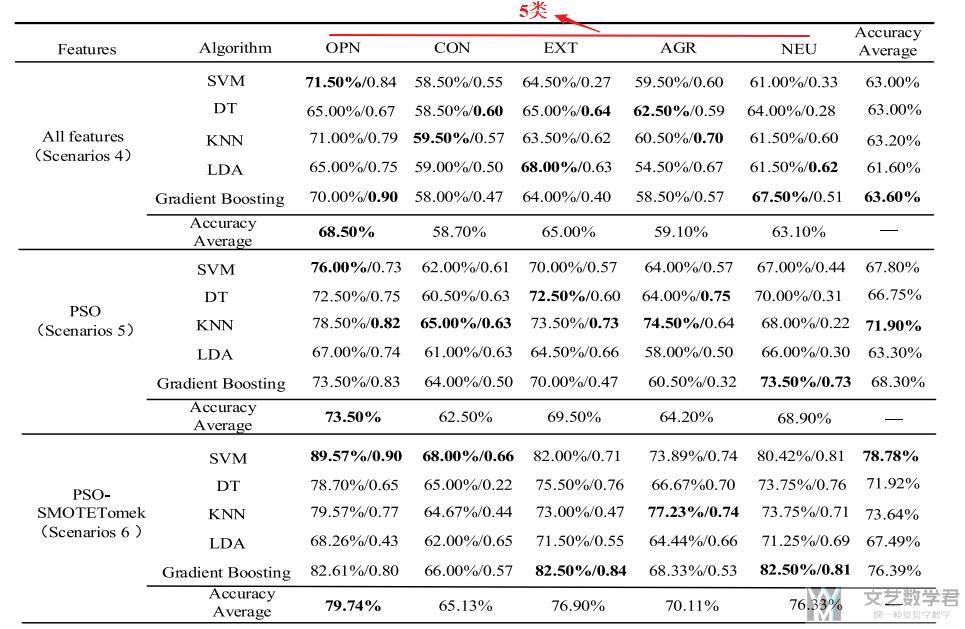
下面一段是原文对上表的描述, Table 4 shows the result obtained on the my Personality dataset. The highest accuracy and F1-score are in scenario number 6. The highest accuracy and F1-score are 89.57% and 0.90, respectively, obtained from SVM algorithm. The highest average accuracy is 78.78%, obtained by the SVM algorithm. The highest average accuracy for all of the traits is 79.74%, obtained from Openness (OPN). Compared with the methods of PSO-SMOTE and PSO-Tomek, the experimental results show that the PSO-SMOTETomek method achieves the highest accuracy and F1-score.
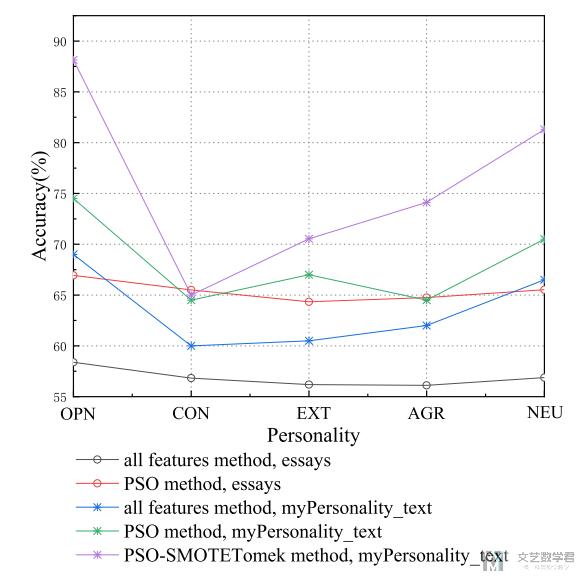
不同的方法, 最终的结果可以画图进行比较, 这样比表格更加清楚, 更加容易进行比较 (可以在这里与其他方法进行比较):
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论