文章目录(Table of Contents)
DataFrame基本概念
DataFrame 是一种跨语言的、通用的数据科学抽象。 DataFrame 通过使用现实世界中的数据集,涵盖了许多最基本的概念和操作。
那么 DataFrame 的出现是为了解决什么问题呢?我们知道在 Spark 里已有了最常用的 RDD ,而从宏观上讲,DataFrame 是为了帮助建立 Spark 生态系统。 DataFrame 是 RDD 基础核心的一种扩展。对于数据科学家们来说,DataFrame 能够较好地从 R 语言或者 Python 来进行转换。因此最好将其理解为一种结构化的 RDD ,它能够帮助你处理数据而让你不用花太多精力在数据的各种转换中。这也是为什么 DataFrame 能够与结构化数据(甚至是非结构化数据)建立紧密的联系。通过它,我们可以利用 Spark 引擎带来的类型和优化上的长处。
说到底,DataFrame 就是一个按照指定列来组织的分布式数据集合。我们可以通过 Parquet 、 Hive 、 MySQL 、 PostgreSQL 、 JSON 、 S3 和 HDFS 等多种数据源来构建它。 DataFrame 常用于 Spark SQL 当中。如果是在这样一个数据库系统中,你可以将其理解为其中的一个表。
例子演示
下面我们会使用一个一个飞机准点率的数据集进行演示;
启动Spark Shell
spark-shell --packages com.databricks:spark-csv_2.11:1.1.0
在这里启动的时候需要带上相关的包,之后需要用来读入csv文件
读取csv文件
首先我们读取csv文件,并尝试打印出前5行的内容;
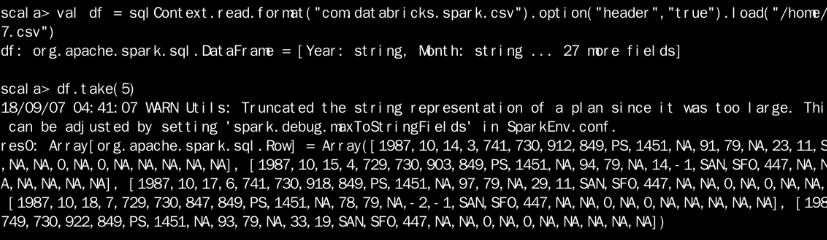
- val sqlContext = new org.apache.spark.sql.SQLContext(sc)
- val df = sqlContext.read.format("com.databricks.spark.csv").option("header", "true").load("/home/hadoop/1987.csv")
查看导入的格式
使用 df.printSchema() 进行查看:
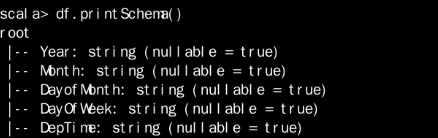
进行类型的转换
可以看到导入之后的类型都是string,为了方便之后的处理,我们进行类型的转换;
- def convertColumn(df: org.apache.spark.sql.DataFrame, name:String, newType:String) = {
- val df_1 = df.withColumnRenamed(name, "swap")
- df_1.withColumn(name, df_1.col("swap").cast(newType)).drop("swap")
- }
定义类型转换的函数,进行转换:

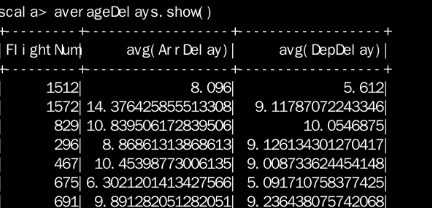
进行简单的统计
- val averageDelays = df_4.groupBy(df_4.col("FlightNum")).agg(avg(df_4.col("ArrDelay")), avg(df_4.col("DepDelay")))
- // 由于Spark是懒加载的,我们将计算结果缓存下来,加快之后的计算
- averageDelays.cache()
之后把统计的结果显示出来,如下图所示:
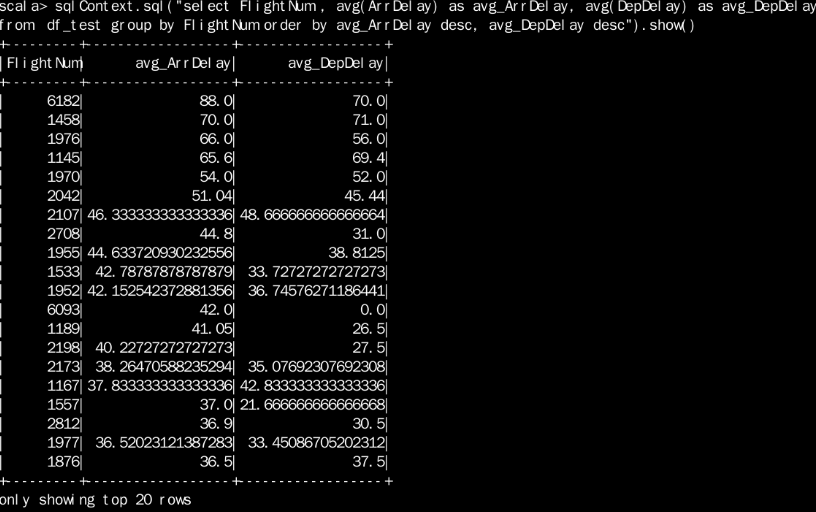
新建临时表进行统计
除了上面的方法,我们还可以通过新建临时表,从而通过sql语句进行查询:
- df_4.registerTempTable("df_test")
- sqlContext.sql("select FlightNum , avg(ArrDelay) as avg_ArrDelay, avg(DepDelay) as avg_DepDelay
- from df_test
- group by FlightNum
- order by avg_ArrDelay desc, avg_DepDelay desc").show()
以上就是关于DataFrame的一些学习的笔记。
参考资料
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论