文章目录(Table of Contents)
简介
这一部分介绍关于网络加密流量的一些实验的论文. 这一部分主要是针对直接使用原始流量来进行实验的文章. 大部分文章使用了CNN的方法来实现分类, 也会包含其他的一些方法.
下面就是对每一篇文章依次进行介绍, 说明分类任务(是区别使用了何种traffic, 还是对应用进行区分), 数据处理方式, 使用的模型和最后的结果.
对于网络加密流量实验的一个概括性介绍(可以先读一下这一篇文章对这个方向, 和相关数据集有所了解): 网络加密流量的相关研究
基于CNN的实验
Malware Traffic Classification Using CNN for Representation Learning
- Wang, Wei, Ming Zhu, Xuewen Zeng, Xiaozhou Ye, and Yiqiang Sheng. "Malware traffic classification using convolutional neural network for representation learning." In 2017 International Conference on Information Networking (ICOIN), pp. 712-717. IEEE, 2017.
这一篇文章主要是来描述对数据集的处理方式的, 和加密流量检测的关系不是很大. 这一篇文章是对下面一篇文章使用方法的详细说明, 所以在这里提前说明一下.
关于raw traffic, flow和session
- raw traffic: 每一个packet包含(5元组, packet的大小, 开始时间), 其中5元组包含(source host, destination host, source port, destination port, transport protocol)
- flow: 这个是单向的流量, 这个是将原始的packet中有相同的5元组的数据合并在一起.
- session: 这个是双向的流量, 将原始packet中有相同的目的和源IP的流量放在一起.
不同的flow(session)有不同的大小, 这里使用了前784bytes的信息.
Packet Layeer
这里作者提取数据时候分为两种方式进行提取:
- 第一种是只提取应用层的信息(L7)
- 第二种是提取所有的信息(All)
同时作者对IP和MAC进行了处理, 去掉了这两个的信息.
数据预处理
作者在这里给出了一个整体的数据处理的流程:
- Traffic Split: 将原始的pcap处理为Session+All(或是Flow+L7等)的数据.
- Traffic Clear:
- 去除IP和MAC地址
- 同时去除没有应用层数据为0的流量
- 去除重复的文件
- Image Generation: 这一个步骤是可选的, 我们可以直接转换为IDX格式的, 做这一步是为了可视化.
- 将所有的文件裁剪为一样的长度, 都裁剪为784bytes, 不够的填补0x00
- 最后0x00为黑色, 0xff为白色.
- IDX conversion: 最后将images转换为IDX文件.
下面是一个整体的流程图.

End-to-end Encrypted Traffic Classification with One-dimensional CNN
- Wang, Wei, et al. "End-to-end encrypted traffic classification with one-dimensional convolution neural networks." 2017 IEEE International Conference on Intelligence and Security Informatics (ISI). IEEE, 2017.
这一篇文章网上介绍的还是比较多的, 在这里放一下我搜到的一些介绍性的文章.
- 流量分类方法设计(一)——参考论文整理(这一篇有作者自己的理解, 可以看一下)
- 一维卷积神经网络的端到端加密流量分类(这一篇只是一个翻译)
这篇文章的一些优势: 将特征提取, 特征选择, 和分类融合到了一个end-to-end的框架中.
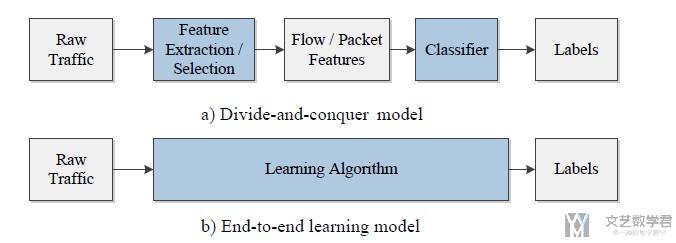
下图是一个整体的框架. a表示传统的方法, 需要进行特征的提取. b为新的这篇文章提出的end-to-end的方式, 可以直接从原始流量到最终的分类结果.
使用的数据集和分类任务
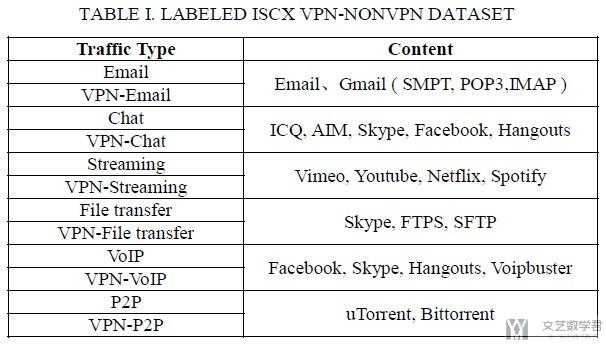
- 使用了ISCX VPN-non VPN traffic dataset.
- 这篇文章重点在于研究encrypted traffic characterization(将加密流量与特点的应用场景相关联, 比如哪些是聊天的流量, 哪些是视频的流量)
原始数据集中共有14种classes, 但是由于一些文件中无法具体区分出是browser还是streaming(例如, facebook_video, 里面既有browser, 也有streaming), 所以不使用这些数据, 所以最终只有12类(没了browser这个分类), 具体的traffic types如下表所示.
数据处理方式和使用的模型
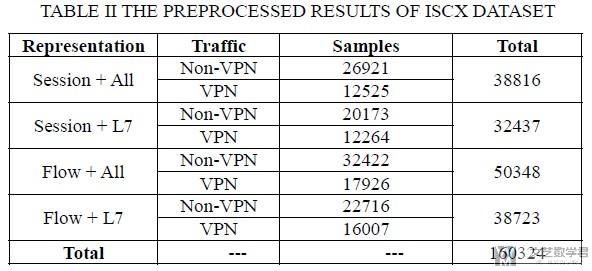
对于原始数据的处理, 作者考虑到了不同对原始流量不同的展示形式, 分别有flow(单向)和session(双向). 同时, 对于其中内容的提取, 作者也考虑到了两种形式, 分别是只提取应用层的内容和提取所有的内容.
于是, 最终有以下四种形式的数据来进行实验.
另外还有一点, 因为每条流流的长度不一致, 而CNN模型的输入要求必须大小一致, 因此需要对数据长度做统一化, 文章使用了每条数据流的前784个byte. (对于数据的截断比较)
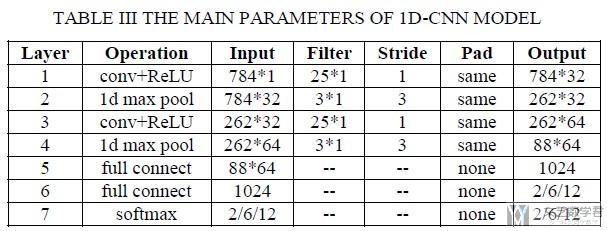
文章使用了CNN模型来进行分类, 比较了1D-CNN和2D-CNN模型对分类效果的差异. 下图是1D-CNN模型的主要结构(最后2/6/12就是看最后想要分为几类).
实验内容和最终结果
作者做了以下的四种类型的实验, 分别是
- 是否使用VPN
- 在不使用VPN的情况下, 对6类traffic进行分类
- 在使用VPN的情况下, 对6类traffic进行分类
- 直接对12类(VPN+VPN-non)进行分类
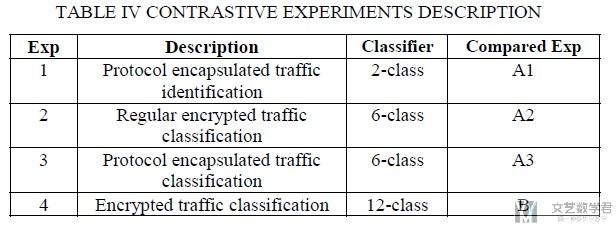
于是作者将这个四个任务分别使用四个数据集(上面提到的session+All, session+L7等)来进行测试. 得到了下面的结果.
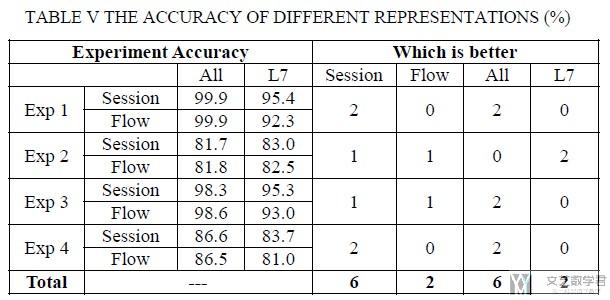
- 可以看到将流量使用session来表示, 结果会更好.
- 使用All layers的结果要比使用L7的结果要好.
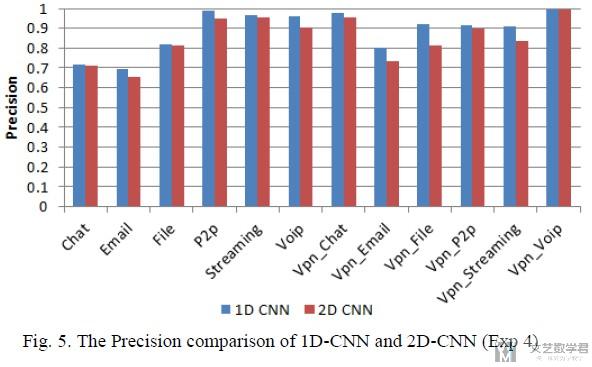
接着作者比较了1D-CNN和2D-CNN两者在准确率上的表现. 可以看到1D-CNN有着更好的表现.
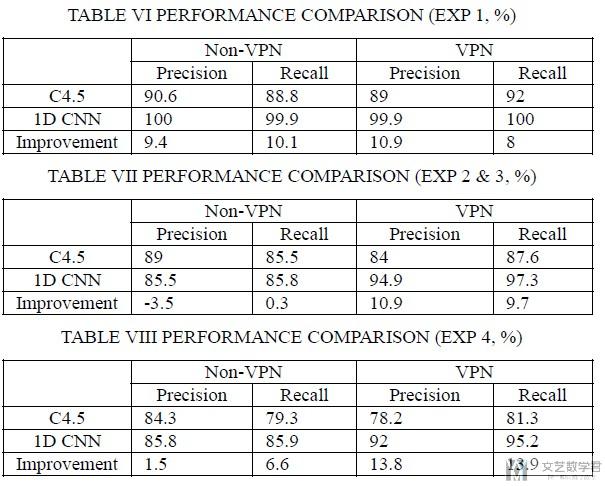
最后, 作者将他的实验结果和提出数据集的原始论文进行比较, 结果也是有所提升.
基于 ResNet 的方法
- Lim H K, Kim J B, Heo J S, et al. Packet-based network traffic classification using deep learning[C]//2019 International Conference on Artificial Intelligence in Information and Communication (ICAIIC). IEEE, 2019: 046-051.
这篇文章是尝试使用 ResNet 来对加密流量进行分类。下面是本文的创新点:
- 提出了一种流量数据处理的方式,只使用 packet payloads,不使用 header 的原因是希望模型可以更加鲁棒,对于没有见到的流量也可以根据 payloads 进行判断;
- 使用了 5 种模型进行训练和测试,包括普通的卷积网络和残差网络(ResNet)
数据集的使用
作者使用了 UPC's Broadband Communication Research Group 提供的 pcap 数据,从中选出 8 种应用,并提取出他们的 application layer payload。
接着是如何将 payload 转换为图片的格式。将原始数据按照 8 bits 来组成一个 pixel,这样一个 pixel 的数字大小范围是 0(=0000,0000)到 255(=1111,1111),这个与图像 RGB 值范围是一样的。原文还生成了不同大小的图像,包括64(=88)、256(=1616)下图是转换之后可视化的结果。

本文使用的模型-CNN and ResNet
本文会使用 CNN 和 ResNet 这两个模型。下面一段话可以放在 CNN 的 background 里面,The selected deep learning models in this study are CNN and ResNet. These models are commonly used for information extraction, sentence classification, face recognition, and image classification. CNN extracts characteristics of data and grasps patterns of features. Therefore, both CNN and ResNet are used for classification based on image packet-based data generated through preprocessing.
首先是使用的 CNN 模型,模型的整体框架如下所示(原文有一段介绍这个结构的话,可以学习一下,在介绍自己框架的时候可以使用):
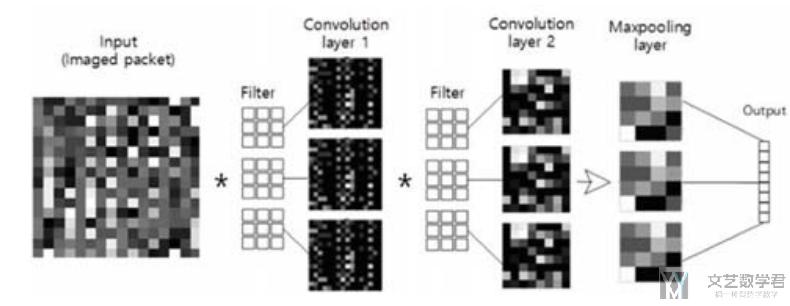
接着作者使用了 ResNet 的框架(同样作者很详细的介绍了 ResNet 的结构,对每一部分的功能进行了说明,写作的时候可以进行参考)。
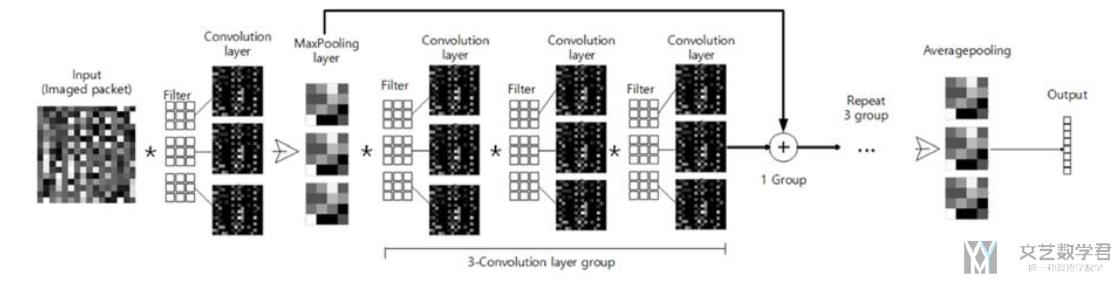
本文的实验和实验结果
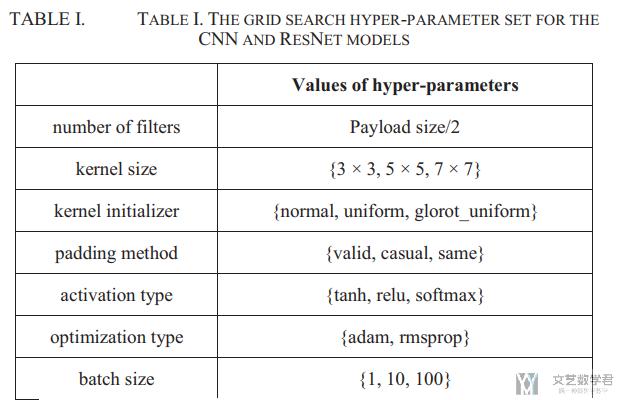
本文是了 grid search 来进行超参数的搜索。对以下的 7 个超参数进行了搜索:
- number of filters,相当于 output channel 的大小
- kernel size,卷积核的大小
- kernel initializer,卷积核初始化的策略
- padding method,不同的 padding 的方式是用来控制 output size 的
- activation type,不同的激活函数
- optimization type,不同的优化器
- batch size,不同的 batch size 的大小
作者一个搜索了下面的这些种可能性:
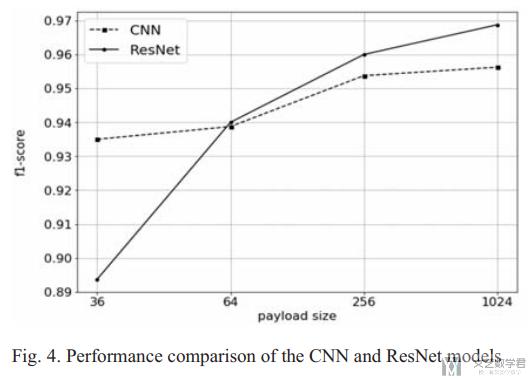
关于最后的实验结果,第一个实验是比较 CNN 和 ResNet 在不同的 payload 的情况下的 f1 值,结果如下所示,在 payload size 比较小的时候,CNN 的结果会比较好;但是当 payload size 比较大的时候,ResNet 的结果就是会比较好的。(这文章就只有一个实验,感觉像是没写完)
基于 Capsule Neural Network 的方法
- Cui S, Jiang B, Cai Z, et al. A Session-Packets-Based encrypted traffic classification using capsule neural networks[C]//2019 IEEE 21st International Conference on High Performance Computing and Communications; IEEE 17th International Conference on Smart City; IEEE 5th International Conference on Data Science and Systems (HPCC/SmartCity/DSS). IEEE, 2019: 429-436.
这篇文章的框架图还是很好看的,可以参考一下,同时也可以参考一下本文对于实验结果的叙述。创新点的话,可以理解为换了一种网络,优点都是这种网络所带来的。
本文的创新点
- 之前的方法的一些局限性(基于深度学习方法的局限性)
- Ignore the relative position inside the packets like the position of fixed strings
- The pooling of CNN changes the useful features behind the traffic
- 本文的主要贡献
- 本文提出了一种基于 CapsNet 的模型
- 这种模型使用 vector 而不是 scalar,从而可以包含更多的信息,例如一些字符的相对位置。
- 同时这种模型不再使用 pooling 的操作
- 本文提出了一种 twice-segmentation mechanism 的机制,可以增加有效流量的权重(这是一种数据处理的方法,将较大的 session 可以分为多个 session,去掉短的 session,这个想法非常好)。
- 本文提出了一种基于 CapsNet 的模型
本文提出的框架
本文提出的框架如下图所示,共分为三个部分:
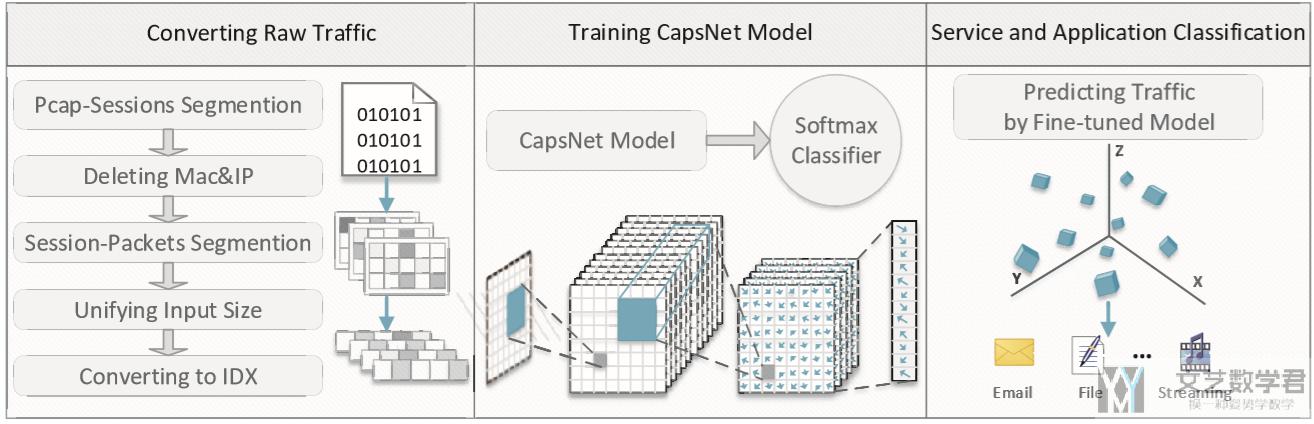
- Converting Raw Traffic
- raw traffic segment by session (将原始流量划分为 session)
- delete Mac and IP (删除数据中的 mac 和 ip 地址,这些会导致模型过拟合)
- Session-packets Segmentation (这里会将大的 session 每次减少一个 packet 来形成新的数据,同时删除较小的 session,具体的可以看下原文)
- Unifying Input Size (将流量转换为固定的大小,原文转换为 784 bytes)
- Converting to IDX (将 784 bytes 的数据转换为 28*28 大小的文件,并保存)
- Training CapsNet Model
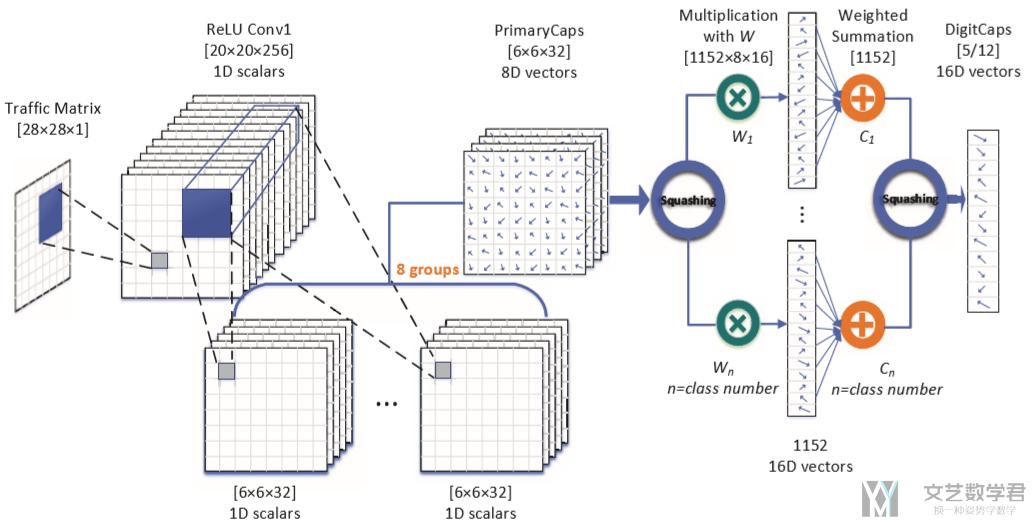
- 利用 CapsNet 构建模型,用于对加密流量进行识别(后面也介绍了模型的参数)
- Service and Application Classification
- 利用上面的模型完成加密流量应用的分类
CapsNet 的实验结果
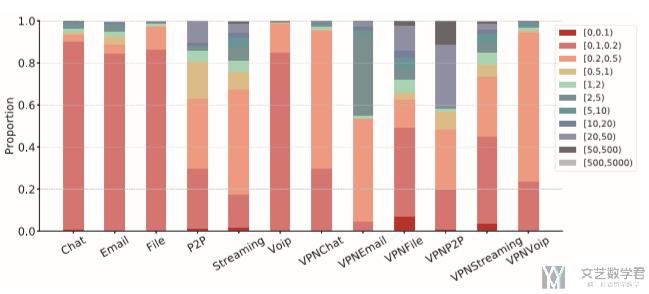
数据集:本论文也是使用 ISCX VPN-nonVPN 数据集完成的。作者查看了不同类型流量的文件大小,如下图所示,可以看到 Chat、Email 等应用的流量大小较小,同时分布不均匀。
Baseline Model:作者使用了 1dCNN、CNN+LSTM、SAE 三个模型作为 baseline。
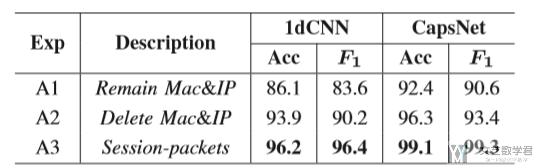
Comparison on Preprocessing:作者比较了不同数据预处理的方式对结果的影响。结果如下表所示。结果显示同样是 1dCNN 的方法,使用本文提出的 A3 的方法进行预处理准确率提升了 7.8%。同样是 CapsNet 方法,识别准确率也是有所上升的。
Comparison on Encrypted Traffic Service Classification:作者在这里比较了不同应用的识别准确率,结果如下表所示:
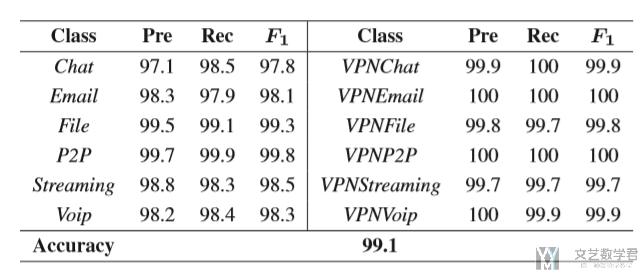
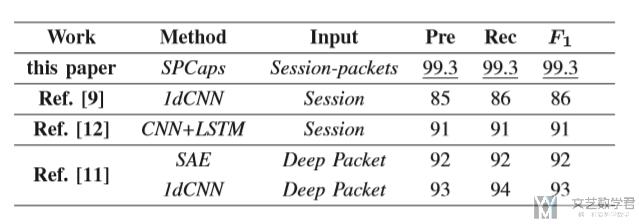
同时作者还将结果与其他论文的实验结果想比较,结果如下图所示,与其他实验相比,本文的模型在各项指标中都有了较好的进步:
基于卷积神经网络的加密流量识别方法
- 陈雪娇, 王攀, and 俞家辉. "基于卷积神经网络的加密流量识别方法." 南京邮电大学学报 (自然科学版) 38, no. 06 (2018): 40-45.
使用CNN来进行加密流量的识别的一些好处, 识别准确率高, 不需要人工选择特征.
使用的数据集和分类任务
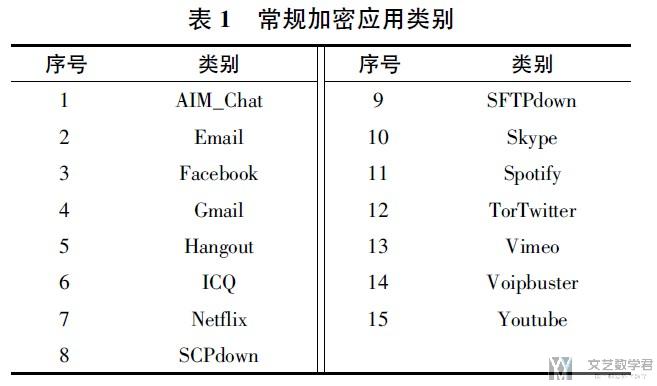
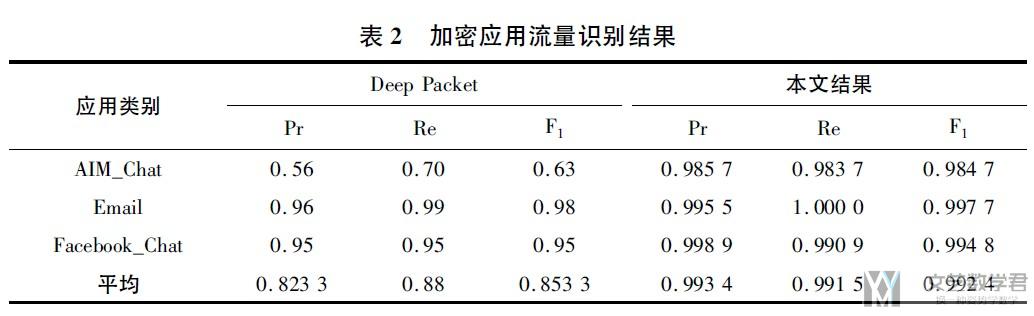
本文使用UNB ISCX VPN-non VPN traffic dataset数据集. 对加密流量中的应用进行分类. 下图是数据集中15种常规加密应用类别. 这里作者选用了三种应用, AIM_Chat, Email, Facebook_Chat进行实验.
数据处理方式与使用的模型
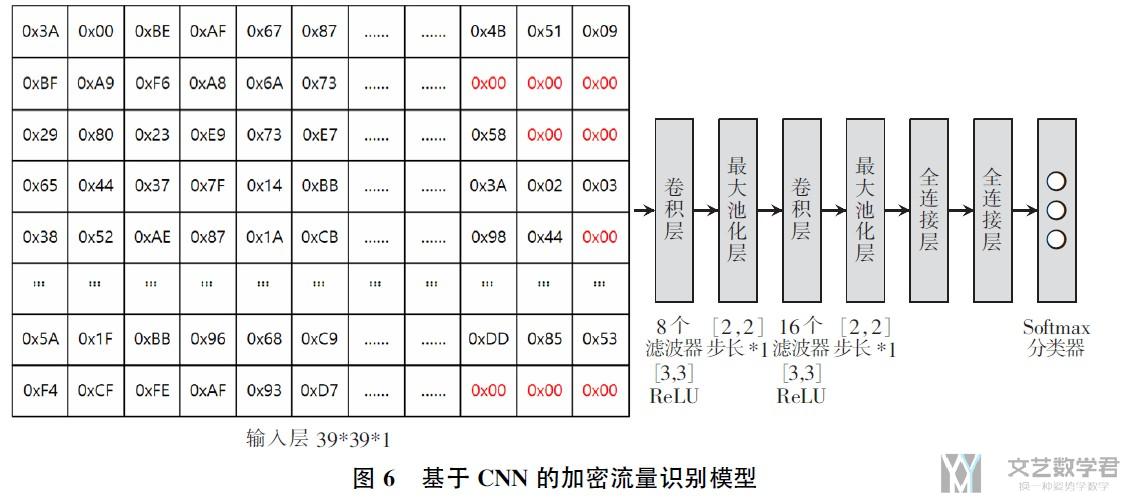
这里数据预处理也是使用将数据转换为固定长度+归一化的操作. 将每一个数据包都转换为1500长度, 然后转换为39*39(=1521)的形状(最后多余的位置填0即可), 最后输入模型中.
因为这里使用的模型比较简答(CNN), 就把这里作者使用的整个模型框架放在这里进行叙述.
实验内容和最终结果
作者最后和Deep Packet这篇文章进行了对比(两者使用的测试集不一样, 结果只可以作为一个参考, 这一篇文章是随机选择了20%作为测试集)
基于深度卷积神经网络的网络流量分类方法
- 王勇, 周慧怡, 俸皓, 叶苗, and 柯文龙. "基于深度卷积神经网络的网络流量分类方法." 通信学报 39, no. 1 (2018): 14-23.
感觉这一篇内容写的比较一般, 数据集也不是很新. 就是用了CNN来处理
使用的数据集和分类任务
这里采用了Moore数据集(这是2005年的数据集, 来自下面的这篇文章)和自己收集的数据集. 其中Moore数据集是有249维的特征.
- Moore, Andrew, Denis Zuev, and Michael Crogan. Discriminators for use in flow-based classification. 2013.
这篇文章的分类任务是, 对网络服务进行分类(例如, 网页浏览类, 通信类, 下载类, 视频类)
数据处理方式与使用的模型
截取流量的784个字节, 由于每一个字节由8bit组成, 可以将1byte转为0-255之间的数值. 接着对数据进行归一化的操作.
使用CNN进行实验. 就是最简单的CNN, 没有变化.
实验内容和最终结果
对于上面两个数据集, 使用:
- 不同的CNN的结构来进行测试
- 使用不同的池化方式, 最大池化, 平均池化
可以学习下面的画图方式.
Auto-Encoders
Deep packet: A novel approach for encrypted traffic classification using deep learning
这一篇文章同时使用了CNN和SAE两种方式, 文章整体的书写还是不错的, 值得借鉴.
- Lotfollahi, Mohammad, Mahdi Jafari Siavoshani, Ramin Shirali Hossein Zade, and Mohammdsadegh Saberian. "Deep packet: A novel approach for encrypted traffic classification using deep learning." Soft Computing 24, no. 3 (2020): 1999-2012.
下面是文章的创新点:
- In this study, we propose a deep learning-based approach which integrates both feature extraction and classification phases into one system. (可以将特征提取和分类两个步骤结合)
- Contrary to most of the current methods, Deep Packet can identify encrypted traffic and also distinguishes between VPN and non-VPN network traffic. (可以处理加密流量)
- To the best of our knowledge, Deep Packet outperforms all of the proposed classification methods on UNB ISCX VPN-nonVPN dataset. (实验结果很好)
使用的数据集
这里使用ISCX VPN-nonVPN数据集. 这一篇文章是同时进行了traffic和application的分类. 也就是不仅会有区分是email还是chat, 还要区分具体的chat的应用, 是Facebook还是AIM Chat.
数据预处理
The "ISCX VPN-nonVPN" dataset is captured at the data-link layer. Thus, it includes the Ethernet header. (这个数据集是包含MAC地址等信息的)
在预处理的阶段, 我们进行了如下的操作:
- 去除Ethernet header
- 对UDP的头部(8 bytes)进行填充, 使其于TCP的头部(20 bytes)长度是一样的.
- 接着, 从bits转换为bytes, 方便NN的输入. (The packets are then transformed from bits to bytes which helps to reduce the input size of the NNs.)
- 去除TCP握手的时候的数据包, TCP segment是SYN, ACK或是FIN.
接着我们查看了packet的长度, 如下所示:
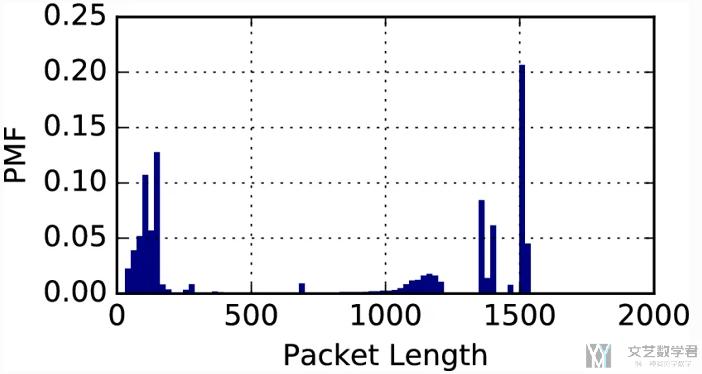
- 有96%的数据payload的长度都是小于1480bytes, 于是这里取payload的长度是1480 bytes, 同时由于header是20 bytes, 这样我们将一个packet转换为一个1500 bytes的向量.
- 为了获得一个更好的结果, 我们将bytes除255 (To obtain a better performance, all the packet bytes are divided by 255, the maximum value for a byte, so that all the input values are in the range [0, 1].)
- 会对IP Address和IP Header进行处理, 去除这两个. ( we decided to prevent this over-fitting by masking the IP addresses in the IP header.)
同时, 由于数据的不平衡的问题, 作者在这里使用under sampling的方法进行处理. Sampling is a simple yet powerful technique to overcome this problem (Longadge and Dongre 2013). Hence, to train the proposed NNs, using the under-sampling method, we randomly remove the major classes' samples (classes having more samples) until the classes are relatively balanced.
文章使用的方法
在这一篇文章中, 作者使用两种深度学习的方法, 分别是CNN和AE来分别进行分类. (注意这里两种方法没有合并, 而是分别进行测试, 分别查看分类的准确率). 下图是一个总的网络的结构图:
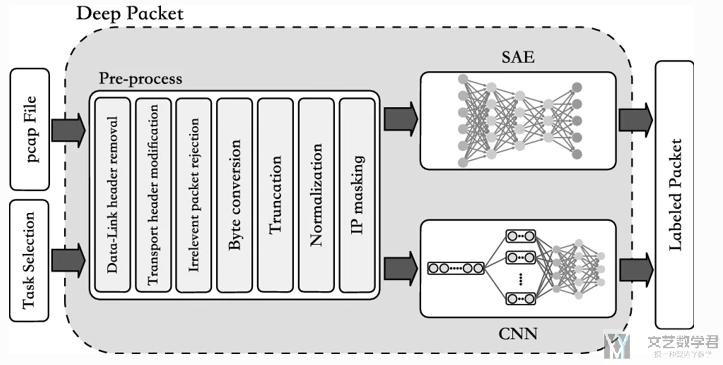
在上面已经对数据预处理进行了说明, 下面详细说明SAE和CNN的结构.
SAE的结构说明:
- SAE这里有5层, 400, 300, 200, 100, 50.
- 同时为了过拟合, 加入了dropout. (To prevent the over-fitting problem, after each layer the dropout technique with 0.05 dropout rate is employed. In this technique, during the training phase, some of the neurons are set to zero randomly. Hence, at each iteration, there is a random set of active neurons.)
- 在最后一层, 我们使用softmax进行分类, 因为这里有两个任务, 所以分别神经元个数为12和17. (For the application identification and traffic characterization tasks, at the final layer of the proposed SAE, a softmax classifier with 17 and 12 neurons is added, respectively.)
CNN的结构说明, 这里是1D CNN, 整体结构如下图所示:
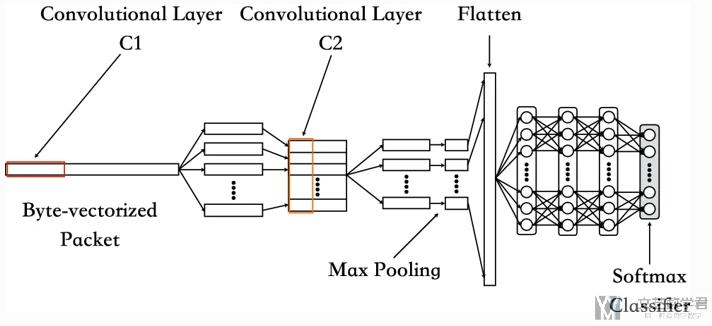
- 两个卷积层后接一个池化层.
- 最后再将向量变为一维, 放入全连接层, 有三层.
- 最后使用softmax来实现分类任务.
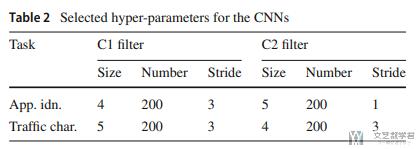
关于网络的参数, 作者使用了grid search来寻找最优参数, 最终使用的参数如下所示, 因为是1D的, 所以kernel size也是1维的, number是channels:
实验结果
首先作者对一个总体的实验环境进行介绍, 包括搭建网络使用的软件, 如何划分训练和测试集, 使用的优化器和激活函数等.
- 作者在这里使用Keras进行实验. (To implement our proposed NNs, we have used Keras library (Chollet et al 2017), with Tensorflow (Abadi et al. 2015) as its backend.)
- 接着作者讲了他是如何划分训练集和测试集的. (We randomly split the dataset into three separate sets. The first one which includes 64% of samples is used for training and adjusting weights and biases. The second part containing 16% of samples is used for validation during the training phase, and finally the third set made up of 20% of data points is used for testing the model. )
- 作者使用Batch Normalization和early stop的技术.
- 作者在这里使用Adam的优化器和ReLU的激活函数.
接着, 作者介绍了使用的评价指标:
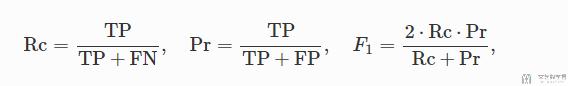
接着, 作者进行了实验结果, 也就是分类的结果进行介绍.
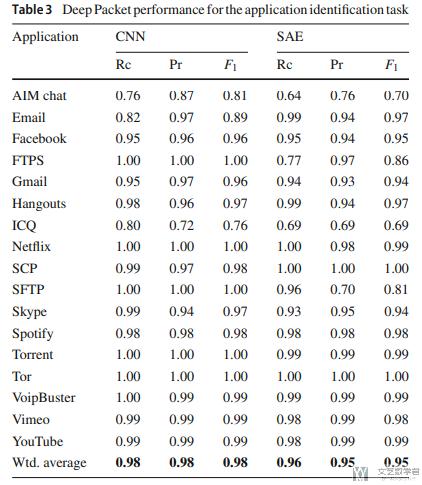
首先是两个模型对于Application分类结果的描述, shows that our networks have entirely extracted and learned the discriminating features from the training set and can successfully distinguish each application. shows that our networks have entirely extracted and learned the discriminating features from the training set and can successfully distinguish each application.
接着是对于traffic characterization任务的结果, F值分别是0.93和0.92.
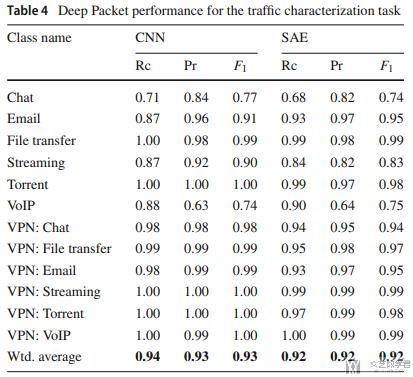
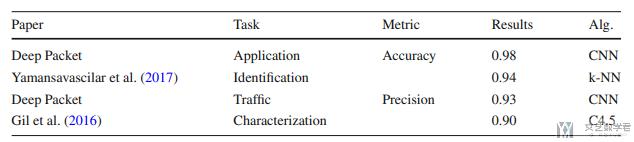
接着作者将自己的实验结果于其他的实验结果进行比较. (The results suggest that Deep Packet has outperformed other proposed approaches mentioned above, in both application identification and traffic characterization tasks.)
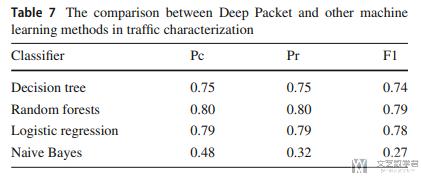
接着与传统的机器学习算法进行比较. 结果也是会比较好的.
一些更加深入的讨论
作者在这里首先绘制出混淆矩阵, 如下图所示:
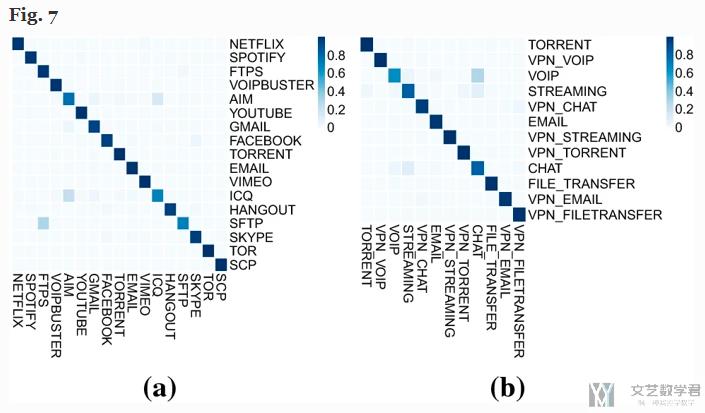
我们会认为, 如果是将A分类为B, 那么A和B这两类应该是相似的, 于是作者在这里使用了层次聚类, 上面矩阵的每一行就是一条数据, 对上面的矩阵里的数据进行聚类, 得到下面的结果:
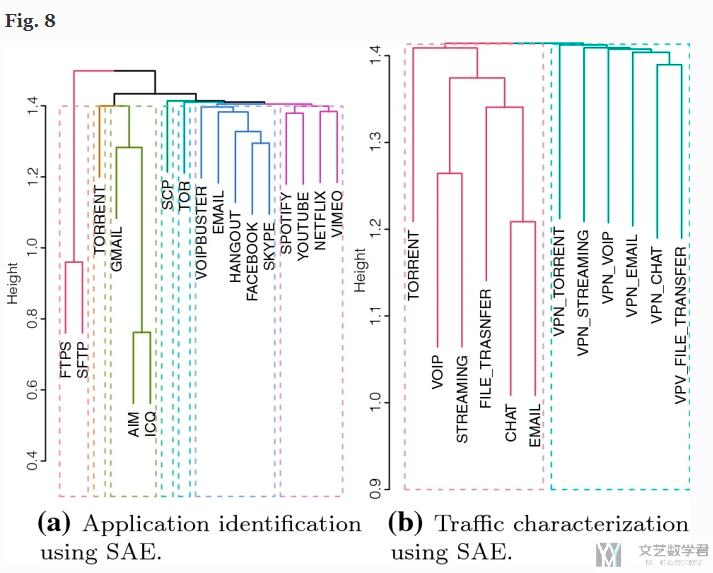
会看到相似的应用会被聚类在一起, Interestingly, groupings separate the traffic into VPN and non-VPN clusters. All the VPN traffics are bundled together in one cluster, while all of non-VPNs are grouped together.
讨论方法的可行性
作者还讨论了为什么这个方法是可行的, 作者认为不同的应用会使用不同的加密算法, 其中伪随机数的发生器不一样, 会导致产生的流量有一些pattern, 所以深度学习可以识别出来.
为了验证这个结果, 作者还做了一个实验, 使用同样的加密算法的不同应用, 就无法进行识别. 下图的识别准确率是很低的.
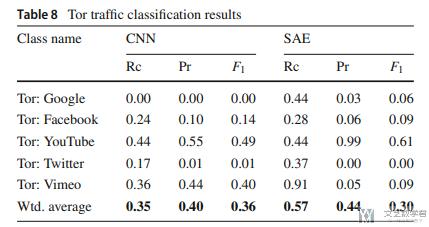
一些将来的工作
对于为什么深度学习可以解决加密流量的问题
- 模型的可解释性.
- 模型的鲁棒性.
- 可以处理unknown的数据, 例如一个新的App发来的流量, 可以知道是unknown的.
- 对于模型速度的问题, 是否可以实时处理.
文章总结
- To the best of our knowledge, Deep Packet is the first traffic classification system using deep learning algorithms, namely SAE and 1D-CNN that can handle both application identification and traffic characterization tasks.
- Our results showed that Deep Packet outperforms all of the similar works on the "ISCX VPN-nonVPN" traffic dataset, in both application identification and traffic characterization tasks, to the date. (说明分类准确率高)
- Finally, the automatic feature extraction procedure from network traffic can save the cost of employing experts to identify and extract handcrafted features from the traffic which eventually leads to more accurate traffic classification.
基于堆栈式自动编码器的加密流量识别方法
这一篇文章的作者和上面有一篇是同样的人, 所以论文的分类任务也是比较相似.
- 王攀, and 陈雪娇. "基于堆栈式自动编码器的加密流量识别方法." 计算机工程 11 (2018): 24.
使用数据集和分类任务
本文使用ISCX VPN-non VPN traffic dataset数据集, 选择常规加密流量(也就是没有使用VPN的加密流量)中的15种应用(这里是对15种应用来作为最终的分类任务)作为训练集和测试集. 每一种应用和每一类样本的占比如所示.
由于样本的不平衡, 作者在这里使用了下面两种处理方式.
- 样本数量过少的类别使用了SMOTE过抽样
- 对样本数量过多的类别这里使用了欠抽样的方式.
对于SMOTE过抽样方式的简单介绍: SMOTE算法是一种随机过抽样方法, 其主要思想是应用K-最近邻方法, 在少数类样本之间利用线性插值生成新的样本, 从而增加少数类样本的数量, 使数据集的类别数量相对平衡.
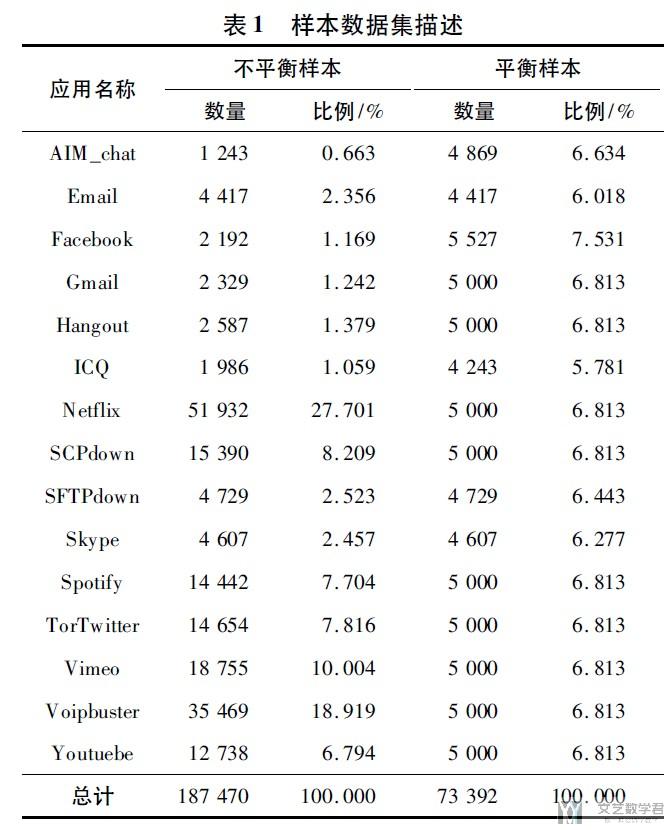
数据处理方式
由于网络数据包分组中的每一个字节都是8bit组成的, 其转为十进制构成的值的范围是0-255, 非常类似于黑白图片中的一个灰度像素. 但是在数据分组中, 每一个数据包中包含的字数长短不一, 因为需要对数据进行预处理.
下面是一个数据处理的整体的流程.
- 读取数据包, 对数据包进行过滤(去除ARP, DHCP等局域网信息)
- 循环读取数据包, 对数据包完成数据预处理(截断或是补零, 归一化), 得到PBV(分组字节向量)
- 因为分组大小最大为1500, 这里就是不够补零
- 将PBV拼起来, 组成PBM(分组字节矩阵)
对于分组大小的一些说明
每一种物理网络都会规定链路层数据帧的最大长度,称为链路层MTU(Maximum Transmission Unit).IP协议在传输数据包时,若IP数据报加上数据帧头部后长度大于MTU,则将数据报文分为若干分片进行传输,并在目标系统中进行重组。比如说,在以太网环境中可传输最大IP报文大小(MTU)为1500字节。如果要传输的数据帧大小超过1500字节,即IP数据报长度大于1472(1500-20-8=1472,普通数据报)字节,则需要分片之后进行传输。
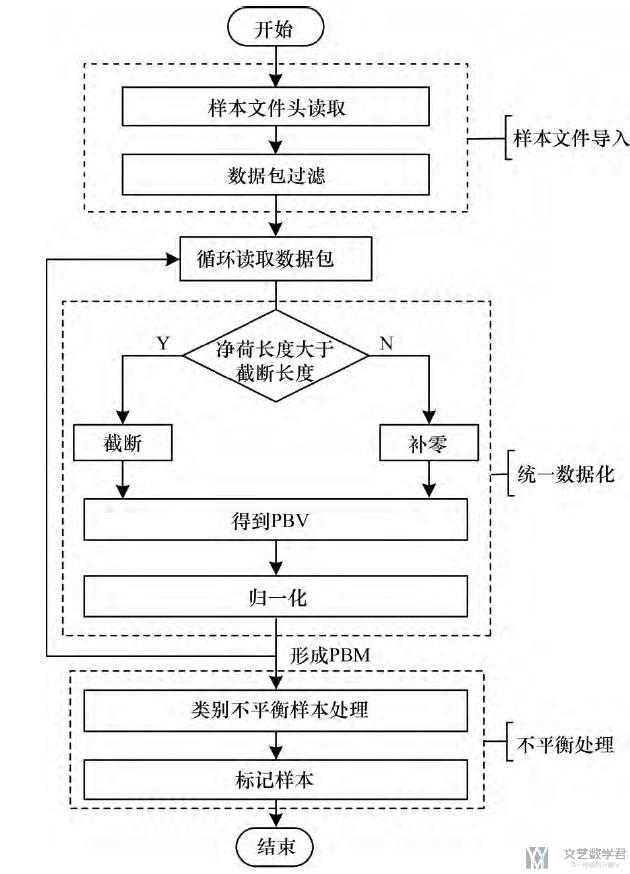
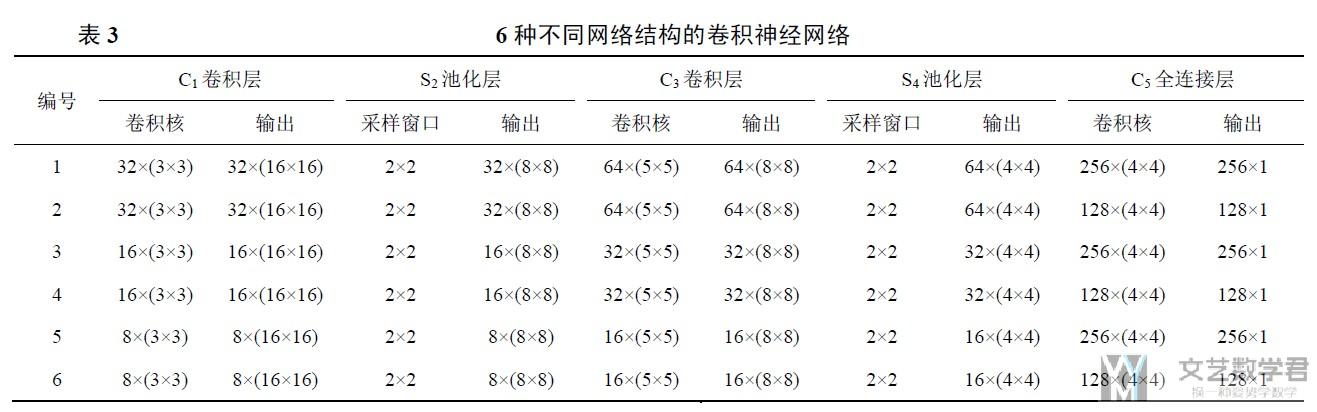
使用的模型
使用了stacked autoencoder(SAE)+MLP的方式来进行训练和实现最终的分类结果. 模型框架如下图所示.
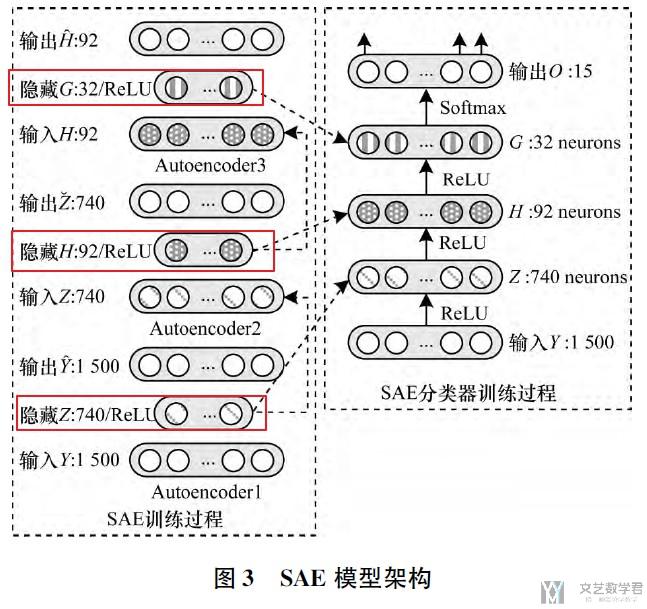
整个模型的训练分为两个阶段, 第一阶段是训练SAE, 第二阶段是分类器的训练过程.
- 第一阶段中, 训练SAE, 相当于训练了三个AE, 分别是: 1500-740-1500, 740-92-740, 92-32-92.
- 第二阶段, 训练分类器, 输入为1500维度, 中间三个隐藏层分别是740, 92, 32, 分别使用上面三个训练好的AE的中间层作为初始化系数, 输出是15(应用个数).
实验内容和最终的结果
为了比较SAE+MLP的效果, 作者训练了一个MLP与之进行比较. 同时将原始数据60%作为训练集, 40%作为测试集.
作者首先做了基于平衡数据与不平衡数据之间的实验, 发现平衡数据之后的准确率更好, 所以后面都基于平衡数据进行实验.
接着作者比较了简单MLP和SAE+MLP的分类性能, 发现后者的效果更加好. (可以通过混淆矩阵来进行举例说明)
作者将最后的结果以柱状图和表格的形式进行给出.
RNN 模型相关
FS-Net: A Flow Sequence Network For Encrypted Traffic Classification
- Liu C, He L, Xiong G, et al. Fs-net: A flow sequence network for encrypted traffic classification[C]//IEEE INFOCOM 2019-IEEE Conference on Computer Communications. IEEE, 2019: 1171-1179.
- 传统的解决方案:
- 结合机器学习的算法和人为手工设计的特征来解决加密流量的分类问题
- Combining machine learning algorithms and manual-design features has become the mainstream methods to solve this problems;
- 传统方法存在的问题:
- 这些手工特征的设计,需要依赖专家经验,需要大量的人工成本;
- 而且没有一个通用的特征设计,针对不同的分类问题需要设计不同的特征,这将加密流量分类问题又分为了许多的小的问题;
- 本文提出的解决方案
- 本文使用 RNN 来解决加密流量分类问题,提出了一个端到端的框架,FS-Net;
- FS-Net 框架可以从原始的流量中学出特征(learn representative feature from raw feature)
- 在框架中结合了 encoder-decoder 的结构,可以保证我们得到的特征可以较好的表示原有的流量信息(import the reconstruction mechanism whcih can enhance the effectiveness of feature)
- 详细解释一下使用 encoder-decoder 结构用来还原特征的好处,The reconstruction mechanism is used to boost the feature learning. By keeping reconstructed sequences and raw flow sequences as similar as possible, the generated features can conatin more discriminative information which improves the classification performance.
FS-Net 模型结构
首先 FS-Net 的总体结构如下图所示:
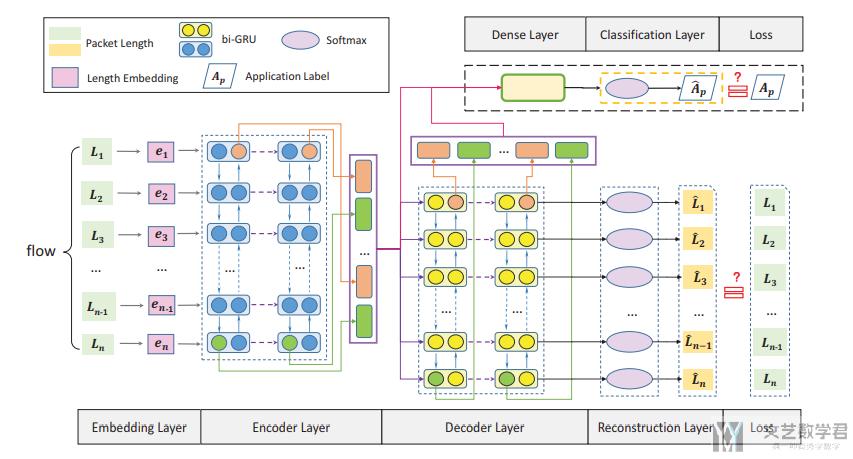
The FS-Net considers both feature learning and classification together. (该框架可以同时进行特征的表示和分类)
- The supervised signals from the application labels will guide the feature representation to be more differentiated.(首先是监督学习部分,因为有了分类,可以使得学习到的特征更加具有表示性)
- And the self-learning behind the reconstruction mechanism can also enhance the representation.(接着是非监督学习部分可以增加特征的表达能力)
FS-Net enjoys the advantages of both supervised and unsupervised learning。关于每一部分的详细介绍,可以参考原论文。
实验结果
文章使用的数据集来自文章,"Mampf: Encrypted traffic classiffication based on multi-attribute markov probability fingerprints" (好像没有公开数据集),并于其他论文的方法进行了比较。
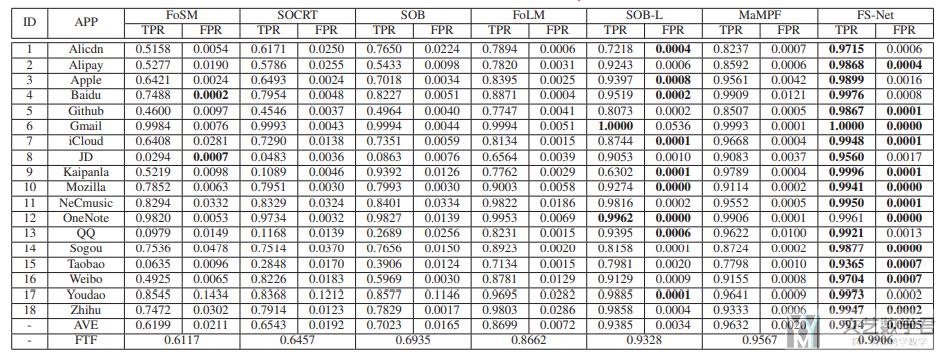
文章首先将自己的模型与其他的模型进行了比较,得到自己的模型综合评价是最好的;
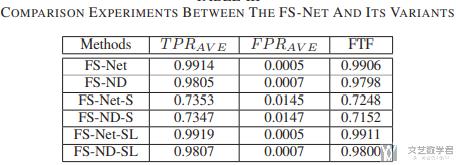
接下来作者将他的模型和自己模型的 5 种变体来进行了比较,得到了下面的结果。关于每一个变体的含义原文中有讲,可以亲自去看一下:
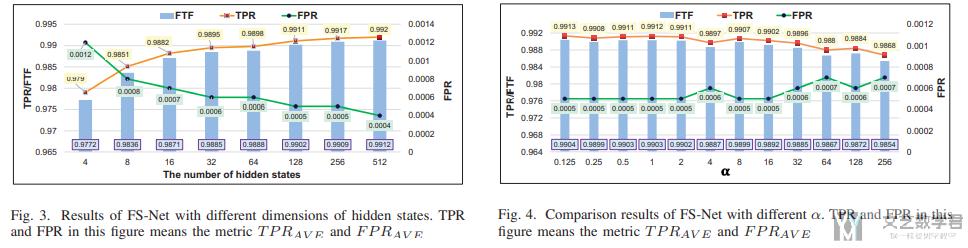
最后作者测试了不同的 hidden state 和 不同的 loss 的系数对最终结果造成的影响,最终的结果如下图所示:
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论