文章目录(Table of Contents)
简介
本文会主要介绍 RLHF相关的内容,参考的内容都列在了下面。这篇文章也是参考了大量的内容,因为部分文章写的已经很好了,所以我这里就直接进行了抄录。抛砖引玉,欢迎讨论。
OpenAI 推出的 ChatGPT 对话模型掀起了新的 AI 热潮,它面对多种多样的问题对答如流,似乎已经打破了机器和人的边界。这一工作的背后是大型语言模型 (Large Language Model,LLM) 生成领域的新训练范式:RLHF (Reinforcement Learning from Human Feedback) ,即以强化学习方式依据人类反馈优化语言模型。
过去几年里各种 LLM 根据人类输入提示 (prompt) 生成多样化文本的能力令人印象深刻。然而,对生成结果的评估是主观和依赖上下文的,例如,我们希望模型生成一个有创意的故事、一段真实的信息性文本,或者是可执行的代码片段,这些结果难以用现有的基于规则的文本生成指标 (如 BLEU 和 ROUGE) 来衡量。除了评估指标,现有的模型通常以预测下一个单词的方式和简单的损失函数 (如交叉熵) 来建模,没有显式地引入人的偏好和主观意见。
于是 RLHF 用人工对生成文本的反馈作为衡量标准,进一步去优化模型。RLHF 的思想:使用强化学习的方式直接优化带有人类反馈的语言模型。RLHF 使得在一般文本数据语料库上训练的语言模型能和复杂的人类价值观对齐。
参考资料
- Training language models to follow instructions with human feedback,InstructGPT 原文,里面就只有两个公式,还是比较容易读懂的;
- Awesome RLHF (RL with Human Feedback),关于 RLHF 的相关的论文总结;
- Illustrating Reinforcement Learning from Human Feedback (RLHF),对 RLHF 技术的介绍;
- ChatGPT 背后的“功臣”——RLHF 技术详解,前面文章的中文版本,但是感觉这个中文的翻译一般,有些句子不是很通顺;
- 从零实现ChatGPT——RLHF技术笔记,这是另外一篇解读的文章,内容更加详细一些,加入了作者的思考;
- How ChatGPT is Trained,YT 上关于 ChatGPT 的视频讲解;
- 下面是一组关于 ChatGPT 的视频,分别从 GPT,强化学习,和 RLHF 来进行介绍;
- ChatGPT狂飙原理剖析:GPT系列详解!【ChatGPT】系列第01篇,介绍 GPT 系列;
- ChatGPT狂飙:强化学习RLHF与PPO!【ChatGPT】系列第02篇,介绍 PPO 相关知识点;
- ChatGPT狂飙:InstructGPT解析!【ChatGPT】原理第03篇,关于 ChatGPT 中用到的 RLHF 的详细解释;
- ChatGPT狂飙原理剖析,这个系列用到的 PPT 和相关的材料;
RLHF 技术分解
RLHF 是一项涉及多个模型和不同训练阶段的复杂概念,这里我们按三个步骤分解:
- 预训练一个语言模型 (LM) ,可以认为此时 LM 会完形填空;
- 聚合问答数据并训练一个奖励模型 (Reward Model,RM) ,这个 RM 后面可以自动对数据进行标注。同时我认为这个 RM 是可以对句子有一个理解,上面的 LM 相当于是记忆;
- 训练数据哪里来;
- 如何对数据进行打分;
- 使用什么样的模型作为打分的模型;
- 用强化学习 (RL) 方式微调 LM。
- 强化学习三要素;
- Reward 包含两个部分,RM 模型和微调模型与原始模型的差距;
- 在 InstructGPT 中,一个 episode 就是一轮对话,做一次 action 就结束了(bandit environment );
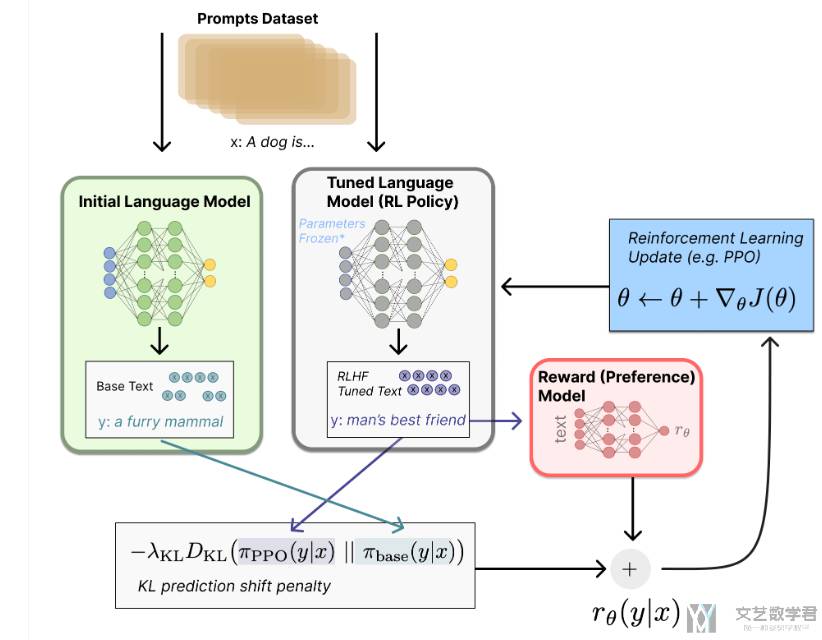
整体的流程图如下所示:
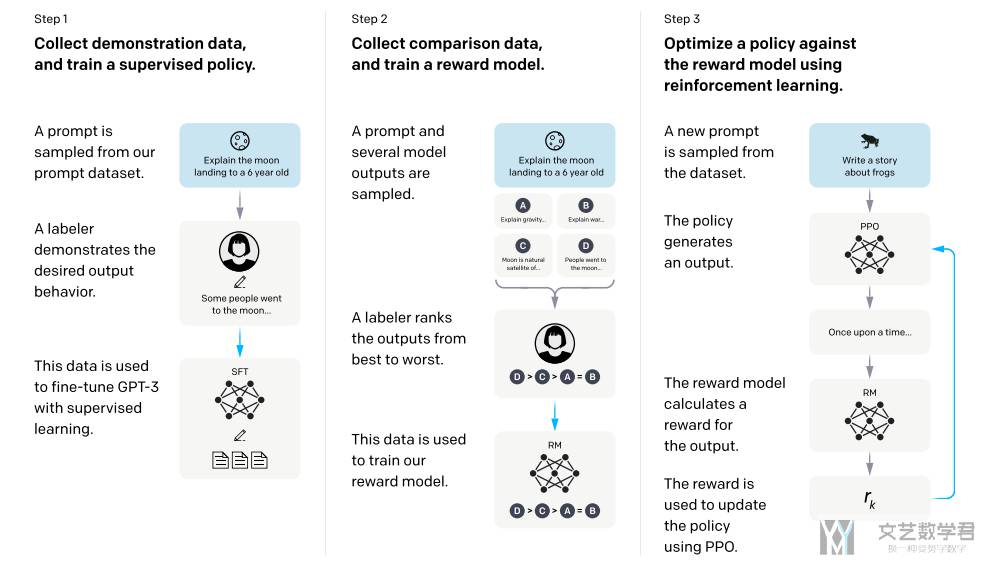
Step 1. 预训练语言模型(SFT)
首先可以对一个预训练模型(例如 GPT-3)进行微调。下面是一些常见的预训练模型:
这里对 GPT-3 多说两句,GPT-3 开启了 NLP 的新范式 prompt,实现了小样本学习。具体就是在输入的时候,会给出前面一句话,然后在后面一句话中进行 mask,然后对 mask 的内容进行预测(此时就有了上下文的语境)。这样可以比较好的迁移到不同的下游任务上面。
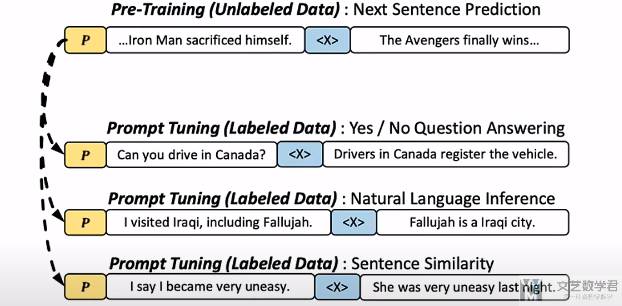
有了预训练的大模型之后,可以用额外的文本对这个 LM(Language Model) 进行微调(不过这个微调也不是必须的),例如 OpenAI 对 “更可取” (preferable) 的人工生成文本进行了微调(给了一些 prompt,然后人工进行回答),而 Anthropic 按 “有用、诚实和无害” 的标准在上下文线索上蒸馏了原始的 LM。在这一步可以多训练几个版本的模型,在后面可以用于对用一个 prompt 生成多个答案。微调后的模型我们成为 SFT(Supervised fine-tuning)。这里 SFT 具有最基本的文本生成能力。
接下来,我们会基于加入人工的反馈,来训练一个奖励模型,并在这一步引入人类的偏好信息。
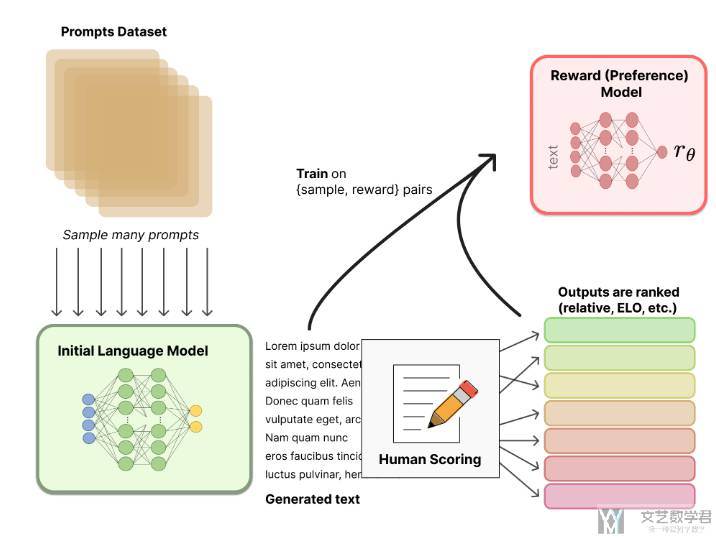
Step 2. 训练奖励模型
RM 的训练是 RLHF 区别于旧范式的开端。这一模型接收一系列文本并返回一个标量奖励,数值上对应人的偏好(这里写了模型的输入和输出)。我们可以用端到端的方式用 LM 建模,或者用模块化的系统建模 (比如对输出进行排名,再将排名转换为奖励) 。这一奖励数值将对后续无缝接入现有的 RL 算法至关重要。
关于模型选择方面,RM 可以是另一个经过微调的 LM,也可以是根据偏好数据从头开始训练的 LM。例如 Anthropic 提出了一种特殊的预训练方式,即用偏好模型预训练 (Preference Model Pretraining,PMP) 来替换一般预训练后的微调过程。因为前者被认为对样本数据的利用率更高。但对于哪种 RM 更好尚无定论。(RM 的模型可以利用 LM 进行接着训练)
关于训练文本方面,RM 的提示 - 生成对文本是从预定义数据集中采样生成的,并用初始的 LM 给这些提示生成文本。Anthropic 的数据主要是通过 Amazon Mechanical Turk 上的聊天工具生成的,并在 Hub 上 可用。我们也可以通过用多个预训练模型给出多个答案,然后人工给这些答案进行排序,从而训练一个奖励模型。例如下面是 hh-rlhf 的样例数据集,同样的问题,包含 chosen 和 rejected:

关于训练奖励数值方面,这里需要人工对 LM 生成的回答进行排名。起初我们可能会认为应该直接对文本标注分数来训练 RM,但是由于标注者的价值观不同导致这些分数未经过校准并且充满噪音。通过排名可以比较多个模型的输出并构建更好的规范数据集。
对具体的排名方式,一种成功的方式是对不同 LM 在相同提示下的输出进行比较,然后使用 Elo 系统建立一个完整的排名。这些不同的排名结果将被归一化为用于训练的标量奖励值(关于 Elo 系统,可以查看 ELO算法教程)。除了上面的方法外,我们还可以使用 Pairwise Ranking 的技术(这个也是在 InstructGPT 使用的方法,具体的 Loss 计算会在后面讲)。这里总体的思路是通过学习排序的结果,来理解人类的偏好。
接下来是最后一步:利用 RM 输出的奖励,用强化学习方式微调优化 LM。
Step 3. 利用强化学习微调
长期以来出于工程和算法原因,人们认为用强化学习训练 LM 是不可能的。而目前多个组织找到的可行方案是使用策略梯度强化学习 (Policy Gradient RL) 算法、近端策略优化 (Proximal Policy Optimization,PPO) 微调初始 LM 的部分或全部参数。因为微调整个 10B~100B+ 参数的成本过高,通常 LM 的参数在微调的时候会被固定 (相关工作参考低秩适应 LoRA 和 DeepMind 的 Sparrow LM) 。
关于强化学习的场景定义:
- 行动空间 (action space) 是 LM 的词表对应的所有词元 (一般在 50k 数量级) 。这里看具体的实现,可以是每一个词是一个 action,或者一句话输出作为一个 action,那此时动作空间大小就是 词表大小×序列长度。在 InstructGPT 里面,一个 action 就是输出全部的结果,而不是一个字一个字输出(原文里面写的是 The environment is a bandit environment which presents a random customer prompt and expects a response to the prompt)。
- 观察空间 (observation space) 是可能的输入词元序列,也比较大 (词汇量 ^ 序列长度) ;
- 奖励函数 是偏好模型和策略转变约束 (Policy shift constraint) 的结合(也就是奖励函数的输出,和新模型的输出和原始模型的输出不要相差太大);
对于使用的 PPO 算法,其中 RM 模型作为 Critic,SFT 模型作为 Actor。于是整个流程为:
- 让 SFT 模型去回答 prompt dataset 的问题(这里的 prompt 是要和前面两个阶段的 prompt 不一样),得到策略的输出,及生成的回答;
- 此时不再让人工去评估好坏,而是让 RM 模型去给 SFT 的结果进行打分排序;
- 使用 PPO 算法对 SFT 模型进行更新;
深度理解 RLHF 技术
关于训练 RM 模型的损失函数
比如现在对于每个 prompt 会有 K 个回复,分别是 <prompt,answer1>,<prompt,answer2>,<prompt,answerK>,我们对这 K 个回复进行排序。
接下来,我们准备利用这个排序结果数据来训练回报模型,采取的训练模式其实就是平常经常用到的 pair-wise learning to rank。对于 K 个排序结果,两两组合,也就是 C(K, 2) 种组合。ChatGPT 采取 pair-wise loss 来训练 Reward Model。RM 模型接受一个输入 <prompt,answer>,给出评价回答质量高低的回报分数 Score。对于一对训练数据 <answer1,answer2>,我们假设人工排序中 answer1 排在 answer2 前面,那么 Loss 函数则鼓励 RM 模型对 <prompt,answer1> 的打分要比 <prompt,answer2> 的打分要高(上面的一些文字性的解释,参考自 ChatGPT会取代搜索引擎吗)。
将上面的文字描述写成公式,就是如下所示(这是 InstructGPT 文章里面的第一个公式):
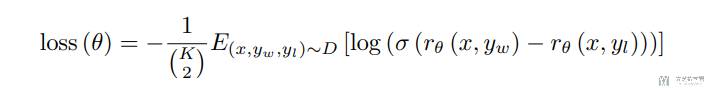
相当于计算了 C(K, 2) 个 Loss,对这些 Loss 计算平均值。对于每一个 Loss,r 表示的是 RM,x 表示 prompt,y 表示 answer。其中 y(w) 的排序要比 y(l) 要好,因此我们对这两个相减,y(w) 的奖励要比 y(l) 高,也就是两者相差越大越好,于是前面加了符号就是希望 Loss 越小越好。
PPO 算法优化策略模型
有了 RM 模型之后可以使用 PPO 对 SFT 的模型进行微调。整个 RL 环境是 state 是 prompt,action 是完整的回复(The environment is a bandit environment which presents a random customer prompt and expects a response to the prompt)。给了 state(prompt) 和 action(answer) 之后,RM 会给出一个 reward,同时结束这次 episode。
为了防止结果变化太大,还加入了 per-token KL penalty(下面式子中的第二项),也就是 PPO 调整之后的模型和 SFT 模型不要相差太大。最后一项是混合上在预训练数据集上的预测,防止模型预测性能的损失(现在模型称为 PPO-ptx)。Value function 从 RM 模型中进行初始化。最后优化目标是下面的式子,希望其最大:

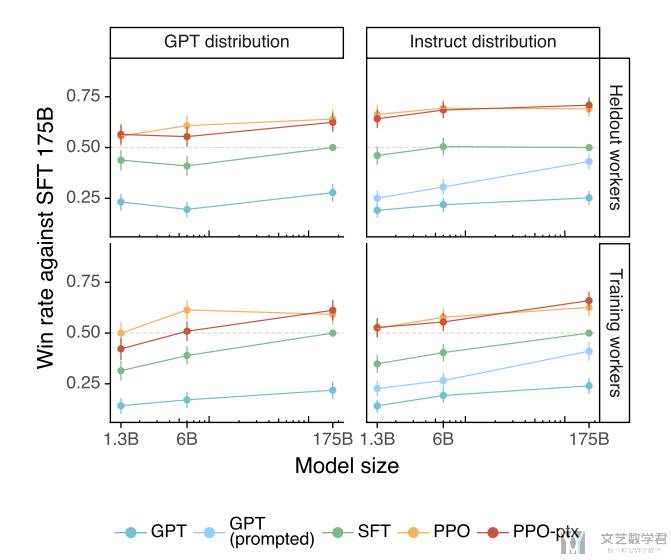
下面是不同模型的一些结果比较,可以看到加入 human feedback 之后的模型性能会有明显的提升。
一些想法
上面是 RLHF 的三个基本的步骤。下面是我的一些想法和疑问:
- 如果将 human feedback 的内容继续进行微调,会有什么样的效果;
- 如果直接将 RM 的模型结果作为监督信号,放在 loss 中来对模型进行优化,这样做和使用 RL 来做效果会有什么差距;
- 同一个任务中,可以加入不同的 RM 模型,比如一个 RM 评价是否包含丰富的信息量,第二个 RM 包含是否包含有害信息。这种模式要更清晰合理一些。因为单一类型的标准,更便于标注人员进行判断,而如果一个Reward Model融合多种判断标准,相互打架在所难免,判断起来就很复杂效率也低。
- 最后不使用 PPO 对模型进行更新,而是对于一个新的 prompt,产生 K 个回答,使用 RM 对这 K 个回答进行排序,然后选择得分高的构成新的数据集,接着使用这个数据集去微调原始模型。
- 关于最后 PPO 模型中 Actor 和 Critic 模型的结构,是否一定需要 Actor 是 SFT 模型,Critic 是 RM 模型,且如果 RM 作为 Critic,那么他是否也会被一起更新;
- 整个框架可以在线进行动态的更新,具体的技术细节可以查看论文 Iterated Online RLHF (see the original paper);
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论