文章目录(Table of Contents)
简介
本文是阅读论文 Reinforcement Learning with Augmented Data 的一些记录。
从 visual observations 中直接学习是 RL 一直的一个挑战。尽管目前结合 CNN 网络已经可以获得较好的效果,但是目前还是存在两个问题:
- data-efficiency of learning;
- generalization to new environments;
因此在本文中,作者提出了 Reinforcement Learning with Augmented Data (RAD),可以提升大部分强化学习算法的性能。本文会有以下的内容:
- 介绍了两种新的数据增强方式,且在 pixel-based 和 state-based 两种输入中都做了测试:We perform the first extensive study of general data augmentations for RL on both pixel-based and state-based inputs, and introduce two new data augmentations - random translate and random amplitude scale.
- 本文测试的数据增强方法,可以让强化学习算法在 benchmarks 上获得较好的效果:Augmentations can enable simple RL algorithms to outperform complex state-of-the-art methods across common benchmarks.
- RAD 方法的范化性也是比传统的方法有所提升的:We further demonstrate that RAD significantly improves test-time generalization over existing methods on several OpenAI ProcGen benchmarks
参考资料
- 论文原文,Reinforcement Learning with Augmented Data;
- 论文代码仓库,Reinforcement Learning with Augmented Data (RAD);
- 知乎上的一篇解读,论文笔记 ,Reinforcement Learning with Augmented Data;
RAD 介绍
受到图像领域的灵感,于是将数据增强用在强化学习中。Inspired by the impact of data augmentation in computer vision, we present RAD: Reinforcement Learning with Augmented Data, a technique to incorporate data augmentations on input observations for reinforcement learning pipelines.
RAD 主要的贡献
- 获得了较好的性能:We show that RAD outperforms prior state-of-the-art baselines on both the widely used pixel-based DeepMind control benchmark as well as state-based OpenAI Gym benchmark. On both benchmark, RAD sets a new state-of-the-art in terms data-efficiency and asymptotic performance on the majority of environments tested.
- 有更好的范化性:We show that RAD significantly improves test-time generalization on several environments in the OpenAI ProcGen benchmark suite widely used for generalization in RL.
- 额外提出了两种数据增强的方式:We introduce two new data augmentations: random translation for image-based input and random amplitude scaling for proprioceptive input that are utilized to achieve state-of-the-art results. To the best of our knowledge, these augmentations were not used in prior work.
且与 CURL 算法相比,RAD 没有引入额外的 loss 函数,所以可以结合任何的强化学习算法来进行使用。在本文中 off-policy 的算法使用了 SAC,on-policy 的算法使用了 PPO。
强化学习中的数据增强介绍
下面来具体介绍一下文中提到的数据增强的方法。需要注意的是,在一个 batch 中使用不同的数据增强方式,但是同一个时刻使用相同的数据增强方式,也就是某个时刻会堆叠多个 frame,这些 frame 使用的数据增强是一样的。Crucially, augmentations are applied randomly across the batch but consistently across the frame stack. This enables the augmentation to retain temporal information present across the frame stack.
Image-based Input Data Augmentations
首先是关于 image-based input 的数据增强方式,如下图所示:
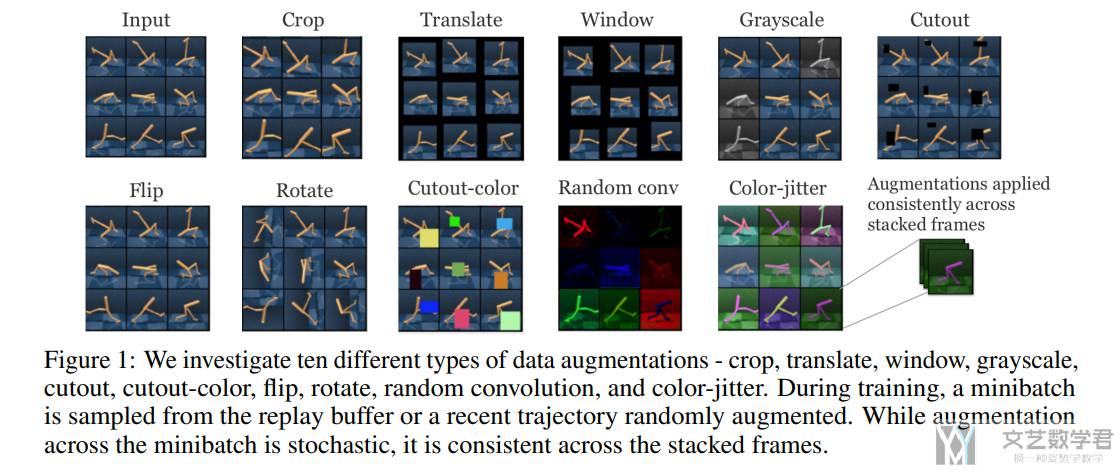
Stated-based Input Data Augmentations
文中提出了两种对于 state-based input 的数据增强方式:
- Random amplitude scaling,
s' = s * z,z为服从均匀分布的参数,这里z作者的取值是在0.6 - 1.4之间的; - Gaussian noise,
s' = s + z,z为服从高斯分布的噪声;
下图是对上面两种方式的总结:

Ok,接下来就是实验了,这篇论文就像我之前说的,“very simple”,没有公式推导,没有新的loss,任何一个现在 RL 算法都可以即插即用,接着我们来看看是不是“very very work”。
实验结果
文章的实验主要有三个部分组成,分别是在(1)DMControl 环境下介绍数据利用效率,也就是不同 time steps 下的效果;(2)ProcGen 环境下介绍模型的范化能力,也就是在没见过的场景下的表现;(3)OpenAI Gym 环境下测试 state-based input 在数据增强下的结果。
Improving data-efficiency on DeepMind Control Suite
在不同环境下的得分如下所示,可以看到不管是 500K steps 还是 100K steps,RAD 都可以获得最好的效果:
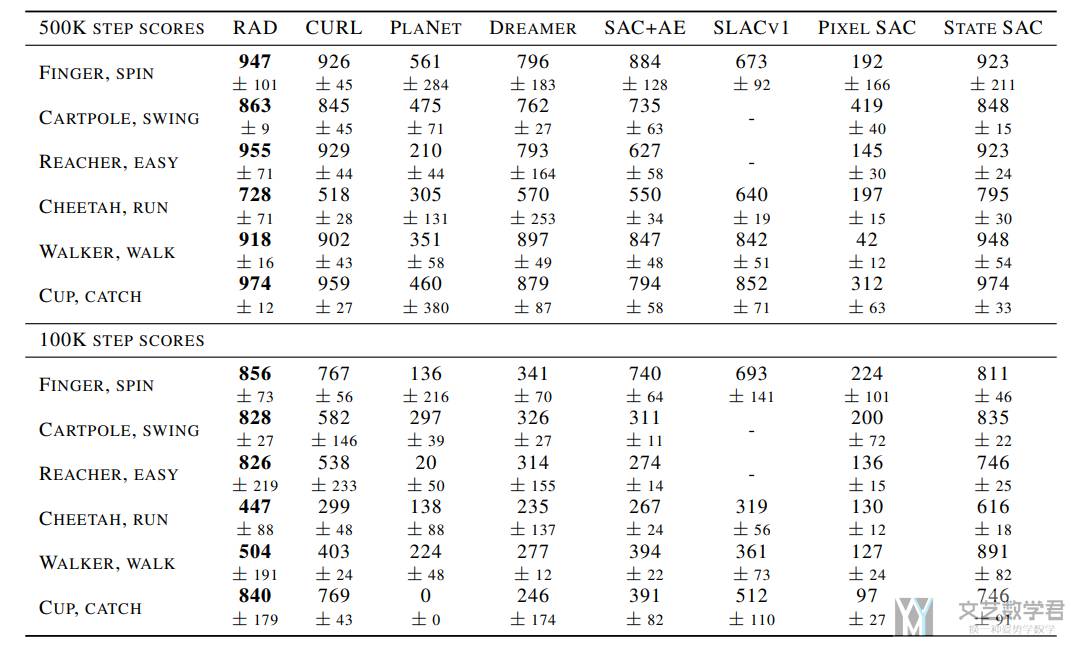
下面是作者总结的一些结论:
- RAD is the state-of-the-art algorithm on all (6 out of 6) environments on both DMControl100k and DMControl500k benchmarks.
- RAD improves the performance of pixel SAC by 4x on both DMControl100k and DMControl500k solely through data augmentation without learning a forward model or any other auxiliary task.
- RAD matchesthe performance of state-based SAC on the majority of (11 out of 15) DMControl environments tested as shown in Figure 7.(可以让 pixel-based 的结果与 state-based 相提并论)
- Random translation or random crop, stand-alone, have the highest impact on final performance relative to all other augmentations.(在所有的数据增强方法里面,
crop是最有效的)
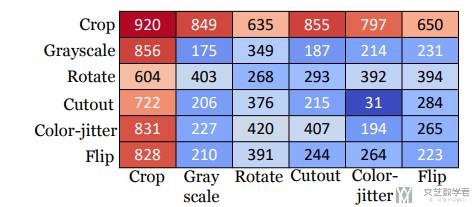
为了比较哪一种数据增强的方式是最有效的,作者在 Walker 环境下,将不同的两种数据增强的方式进行组合来进行测试,结果如下图所示,图中数字表示获得的分数,如果不使用数据增强,只能获得 200 左右的分数,可以看到 crop 的得分是最高的:
Improving generalization on OpenAI ProcGen
下表表示 RAD 在 ProcGen 环境下的结果。可以看到使用 crop 可以有效的改善模型结果。
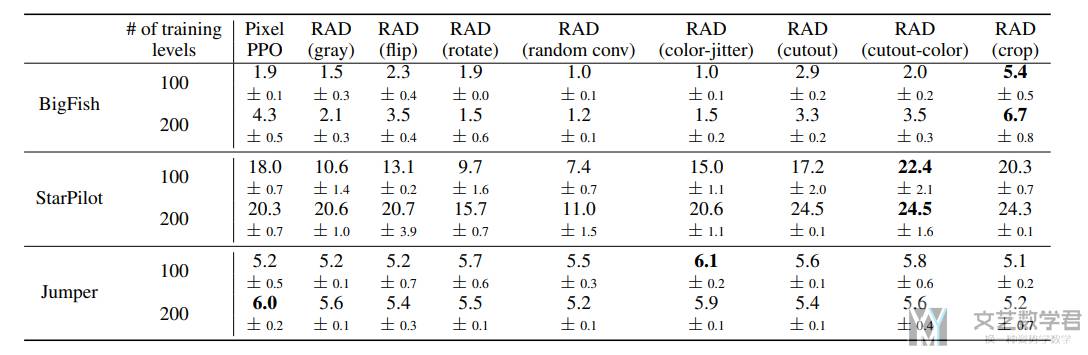
下面是作者总结的一些结论:
- In particular, RAD with random crop achieves 55.8% relative gain over pixel-based PPO on the BigFish environment.
- RAD trained with 100 training levels outperforms the pixel-based PPO trained with 200 training levels on both BigFish and StarPilot environments. This shows that data augmentation can be more effective in learning generalizable representations compared to simply increasing the number of training environments.
- In the case of Jumper (a navigation task), the gain from data augmentation is not as significant because the task involves structural generalization to different map layouts and is likely to require recurrent policies.
Improving state-based RL on OpenAI Gym
最后作者在 state-based input 的环境下进行了实验,查看数据增强是否有效。实验结果如下所示:
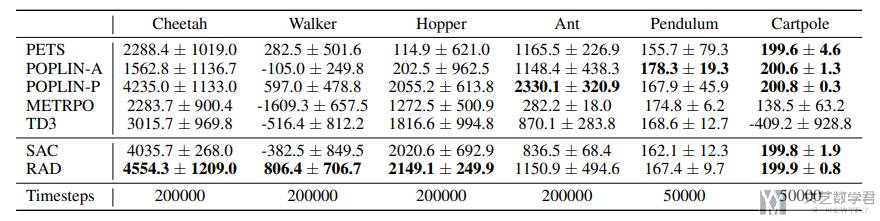
最终作者得到了如下的结论:
- Similar to data augmentation in the visual setting, RAD is the state-of-the-art algorithm on the majority (4 out of 6) of benchmarked environments.
- We hypothesize that random amplitude scaling is effective because it forces the agent to be robust to input noise while maintaining the intrinsic information of the state, such as sign of inputs and relative differences between them.(对数据乘一个数这种方法是比较好的)
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论