文章目录(Table of Contents)
简介
本文介绍了一种从人类反馈中学习奖励函数的方法,也就是 Reward Predictor。这是 RLHF 之前的工作(关于 RLHF,可以参考 RLHF 技术笔记),和 RLHF 中的 Reward Model 的想法已经很接近了。
本文的主要动机如下(摘自,论文理解【IL - IRL】 —— Deep Reinforcement Learning from Human Preferences):
- 奖励函数设计是强化学习中的一个难题。从本质上讲,奖励函数是对任务目标的一种抽象,也是我们向 agent 传达任务目标的桥梁。当任务非常复杂时,很难将目标转化为奖励函数这种形式化、数字化的表征。试想一下,如何为煎鸡蛋这个任务设计奖励函数?
- 虽然将煎鸡蛋这个任务数字化抽象为奖励函数很困难,但是我们人类执行这个任务则没什么难度,也就是说,我们可以以相对低的成本获取很多完成这个任务的专家轨迹,这样我们就可以做模仿学习(IL),比如我们可以先用逆强化学习(IRL)方法从专家轨迹中恢复奖励函数,再用这个奖励函数做 RL。这种方法虽然有效,但是仍存在限制,假如任务太难了,以至于普通人很难完成呢?比如遥控玩具飞机做特技,或者控制一个虚拟机器人后空翻,这些特殊任务需要训练有素的专业人士提供专家轨迹,成本就又上去了。
- 注意到从提供奖励函数到提供任务轨迹,我们降低了对人能力的要求,从而降低成本。按这个思路继续下去,虽然我们不能给出复杂任务的完整轨迹,但是评估某条轨迹的效果还是比较容易的。比如后空翻任务,我们一眼就能看出某段轨迹是不是后空翻,并且能对完成质量给出大概的评估。显然,可以把这个评估作为这一段轨迹的 return,执行 MC 类的 RL 方法。
- 这看起来好像不错,但我们普通人不是专业裁判,且通常没有一个详尽的评价标准,难以给出稳定的定量评估分数。于是我们再次降低要求,只要人类定性地对比两条轨迹哪个比较好就行了。
总结来说,对于特定的任务,较难定义奖励函数,较难获得专家数据(或是专家数据难以覆盖到所有场景),我们可以加入 human feedback,通过对两个轨迹进行比较,从而学到一个 reward predictor。
于是本文的主要贡献如下:
- enables us to solve tasks for which we can only recognize the desired behavior, but not necessarily demonstrate it,
- allows agents to be taught by non-expert users (只需要比较,不需要演示或打分),
- scales to large problems, and
- is economical with user feedback (只需要对1% 的数据进行feedback).
参考资料
- Arxiv-Deep Reinforcement Learning from Human Preferences,原论文;
- Learning from human preferences,OpenAI 对这篇论文的解读,有一些视频展示;
- 【RL论文】 Deep Reinforcement Learning from Human Preferences,对本文使用的方法粗略进行了概括(可以通过这篇文章了解本文的主要方法);
- 论文理解【IL - IRL】 —— Deep Reinforcement Learning from Human Preferences,非常详细的论文解读,可以对照着论文来看;
DRL from HF 的方法
设定和目标
主要的目标是去习得一个由神经网络构成的奖励函数网络和一个策略网络,训练后的奖励函数能够给予人类偏好的轨迹以高分,对应的策略网络能够给予人类偏好的轨迹以高的生成概率。同时在训练过程中,尽可能减少人类的标记数据,即做到高数据利用率。
考虑在 t 时刻,agent 从环境得到一个观测 o_t,然后向环境发送一个动作 a_t,那么轨迹片段 σ 是观测和动作组成的序列:
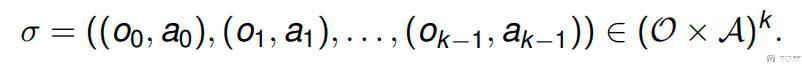
假设「轨迹-1」要比「轨迹-2」要好,那么「轨迹-1」的累计奖励要比「轨迹-2」的累计奖励大:
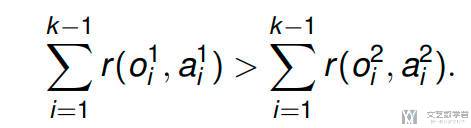
也就是说,如果人类的偏好是由 reward 函数给出的,那么对于人类偏好的片段,应该给出更高的累计奖励。
具体的方法
本方法会维护一个「策略」和一个「奖励函数」,这两者都是由深度神经网络参数化。具体的算法大致分为三个步骤。这三个步骤的过程是异步进行的,也就是不需要等待人类进行判断:
- 策略与环境进行交互,产生一系列的轨迹,接着使用传统的 RL 算法对策略进行优化(文章中 A2C 算法用于 Atari 游戏,TRPO 算法用于 Mujoco),目标在当前奖励函数
r(o,a)下,最大累计奖励。 - 从生成的轨迹集中选择 trajectory segments pair,交给人类进行判断。
- 奖励函数
r(o,a)通过人类的反馈来进行参数的更新,是的r(o,a)更加符合人类的判断。
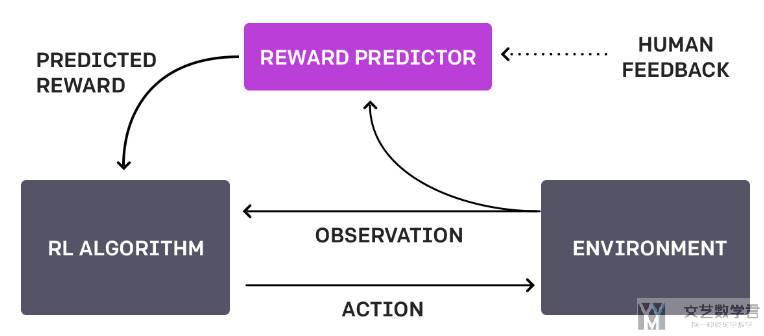
现在我们思考两个问题,(1)如何更新奖励函数;(2)如何选择合适的 trajectory segments pair。这两个问题会在后面给出回答。
偏好习得
标注员可以看到以短视频形式出现的 1-2s 的两端轨迹,标注员需要指出他们更加喜欢哪一段,或者同样喜欢,或者无法比较。

人类专家的判断会被记录在 (σ1, σ2, µ),其中 σ1 和 σ2 表示两段 trajectory segment,µ 表示 {1, 2} 上的分布,表示人类喜欢哪一个segment:
- 如果人类选择一个片段作为首选,那么
µ将所有权重放在该选择上; - 如果人类标记两个选择同样好,那么
µ是均匀分布的; - 如果人类选择不标记,那么这个片段会被抛弃;
拟合奖励函数
作者将训练奖励函数转换为一个分类问题,即有两个片段 σ1 比 σ2,标注员会给出标签,即哪个片段好。此时就是一个二分类问题,奖励函数根据观测和动作,给出动作是否好(类比 Critic 网络,因此在 ChatGPT 中,Critic 是基于 RM 微调的)。
作者将 σ1 比 σ2 好的概率定义为下面的式子(类比 softmax 的表达,本质还是分类问题):
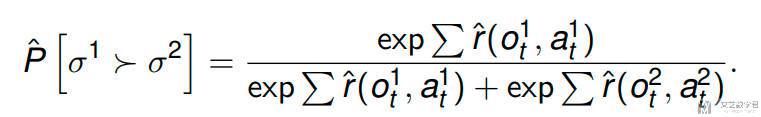
接着使用 cross-entropy 来计算损失函数,从而更新奖励函数:
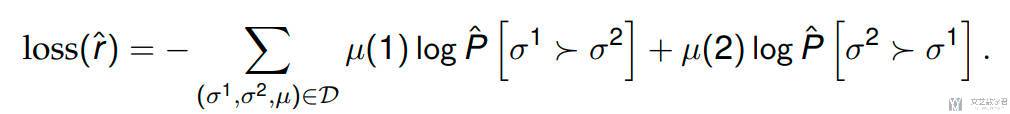
这里作者会同时训练多个奖励函数,都在数据集 D 上进行训练。最后使用的奖励是这些奖励函数的值的均值,同时后面会通过这些奖励函数的方差来挑选需要人工标注的数据。
Queries 的选择
在仿真过程中,会有很多序列片段,不能将所有的序列片段都给人类进行评价。于是作者这里根据奖励函数的不确定性来选择。
首先采样一些长度为 k 的trajectory segment pair,对每一个预测器集里的预测器,分别对每个 trajectory segment pair 做出预测,之后对每一个 trajectory segment pair,选择具有最高 variance 值的那一个呈送给人类专家。
DRL from HF 的实验结果
实验主要使用了两种方式:
- 不使用真实的 reward 数据:智能体仅仅依靠人类专家的反馈来习得 reward function,以此进行强化学习的反馈。
- 合成:在人类专家获取 query 阶段,不使用实际的标签数据,而通过真实的 reward 计算方法计算两段 trajectory segment 中实际获取的 reward 值,取最大的当作偏好轨迹反馈给奖励函数神经网络进行迭代。
MujoCo 的任务
MujoCo 的八个任务结果如下,RL Baseline 算法是 TPRO(在 Atari 上的结果也类似):
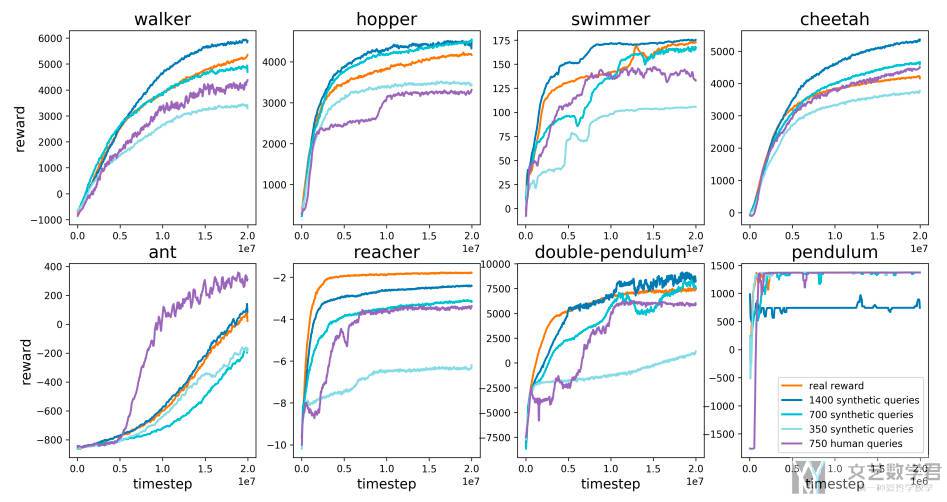
可以看到:
- 有了 700 个对比偏好,就几乎可以在所有这些任务上媲美强化学习(虽然不太稳定方差较高);
- 利用 1400 个标签,我们的算法的性能略好于给予手工奖励的情况,这可能是因为学习到的奖励函数的形式更好;
- 根据任务的不同,人工反馈的效率通常在真实反馈的一半到同等效率之间,少数任务中,由于进行了更有效的 reward shaping,人类反馈优于合成反馈;
新的动作
作者还发现通过这种方法(这部分视频可以点击 Learning from human preferences):
- 可以使得 Agent 学到一些复杂的动作。而针对这类复杂任务的奖励函数设计是十分复杂的;
- 可以允许 Agent 学到原始目标之外的任务。例如在 Enduro 中训练 Agent 与其他车辆平行;
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论