文章目录(Table of Contents)
简介
在 RLHF 技术笔记 我们介绍了在语言模型中训练 RM 模型来判断模型生成的结果如何。本文,ImageReward,作者主要对 text-to-image 领域提出了一个 reward model,从而可以对根据 text 生成的 Image 来进行打分,从而来帮助评价和优化「text-to-image」的结果。
具体来说,主要的贡献如下(感觉主要是公开数据集,和训练 RM,没有微调):
- 公开了一个 text-image score dataset,和标准的 pipeline;
- 发布了一个 ImageReward 的模型,对 prompt 和生成的图像进行打分(作者没有利用这个 RM 去进一步优化模型,而是使用这个模型从生成的结果中选择符合人类偏好的结果);
- ImageReward 可以作为一个自动的 text-to-image 的评价指标,从而可以在众多生成结果中挑选出与人类偏好排名一致的结果(同时有了这个 RM 之后,可以自动对结果进行标注);
参考资料
- ImageReward: Learning and Evaluating Human Preferences for Text-to-Image Generation
- Github Code: official
- ImageRewardDB,本文所使用的数据集;
- 《论文阅读》ImageReward: Learning and Evaluating Human Preferences for Text-to-Image Generation,对于这篇论文的解读【知乎】
ImageReward Introduction
尽管现在文生图飞速发展,但是存在一个问题,模型生成的结果与人类偏好的对齐(aligning models with human preference)较为困难。例如下面的几个问题:
- 文本图像对齐,无法准确描绘文本提示中描述的对象的所有数字、属性、性质和关系;
- 身体问题,呈现人体或动物身体部位(如四肢)畸形、不完整、重复或异常;
- 人类美学,偏离人类对美学风格的平均或主流偏好;
- 有害和偏见,展示有害、暴力、性、歧视、非法或引起心理不适的内容;
上面这些普遍存在的挑战难以仅通过改进模型架构和预训练数据来解决。于是作者引入 human feedback 来训练一个 Reward Model,评价文生图的结果好坏(比如我们根据一个 prompt 生成了多组结果,希望从中找出最好的结果,之前可以通过 CLIP Score 的方法来比较)。本文主要的文本标注和 RM 训练如下:
- Preparation for annotation, which samples and filters prompts and generated images for diversity and representativity.
- Annotation, which consists of two steps: a) Rating that scores on a seven-point Likert scale from three dimensions and b) Ranking that compares images from an overall perspective.
- Preference learning and inference, which trains ImageReward on annotated comparisons to align to human preferences.
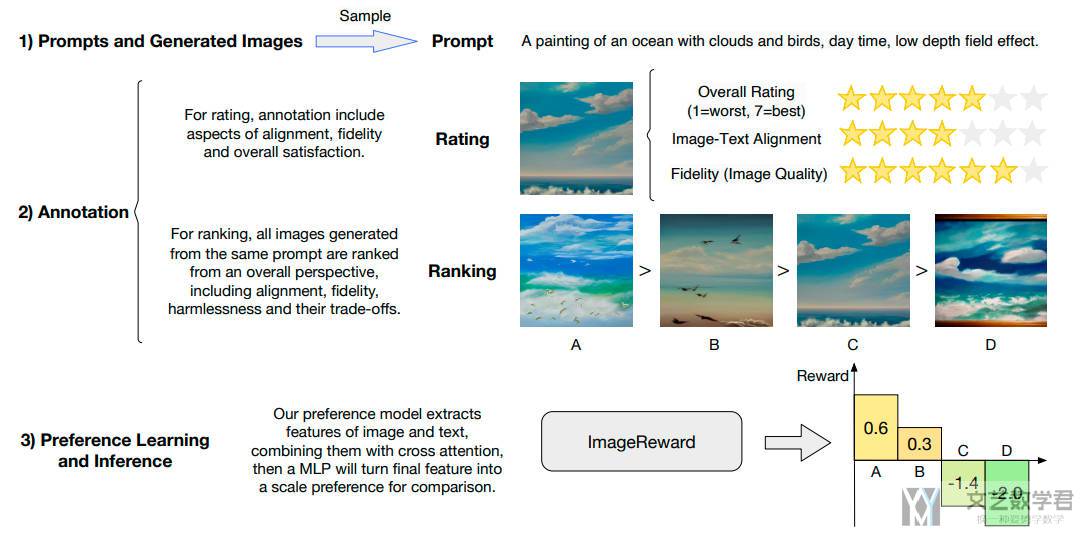
ImageReward 主要细节
下面详细对本文的方法进行介绍,主要是两个部分(1)Data Collection 和 (2)RM Training。
数据集收集(Data Collection)
作者在这个部分详细介绍了(1)prompt 和 image 是如何收集的;(2)人工如何对其进行标注;(3)对人工标注结果的分析。我们这里进行简单的介绍,详细内容可以参考原文。
下图展示了如何进行标注,分为两个部分:
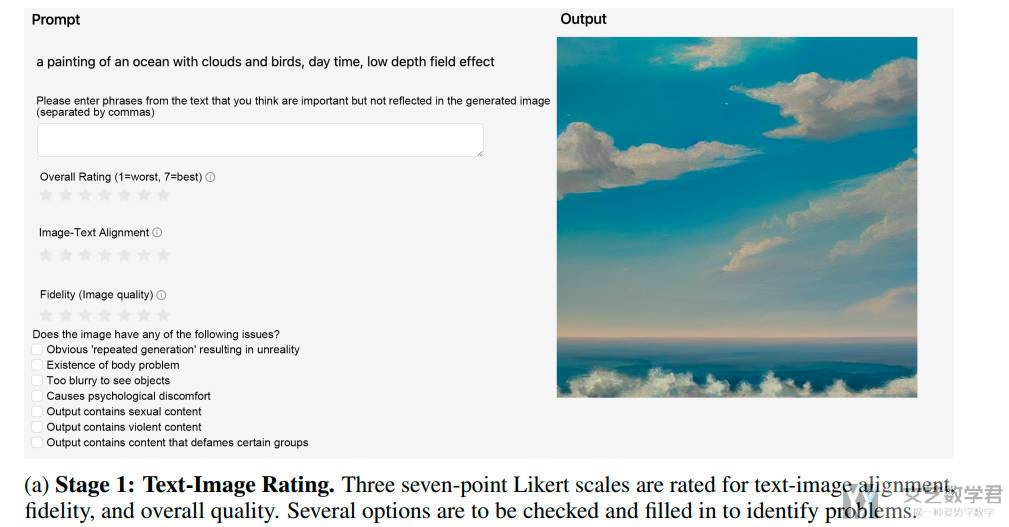
(1)对图片进行打分(从文本-图像对齐度、保真度和整体质量三个维度),框选生成质量不好的原因,例如主题模糊、包含暴力元素等。这个部分不会用于 RM 的训练,作者对这里的结果进行了分析;
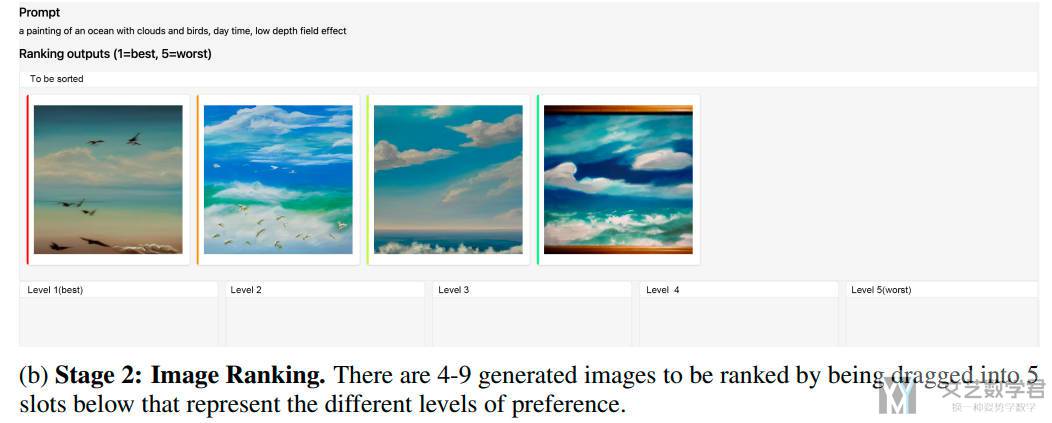
(2)对结果进行排序(通常一个 prompt,会有 4-9 个实验结果),标注人员只需要将图像按顺序排列即可(只有这个结果用于 RM 的训练,这里与 InstructGPT 使用的方法是一样的,计算两两之间的 loss,后面 RM Training 的时候也会涉及到)。
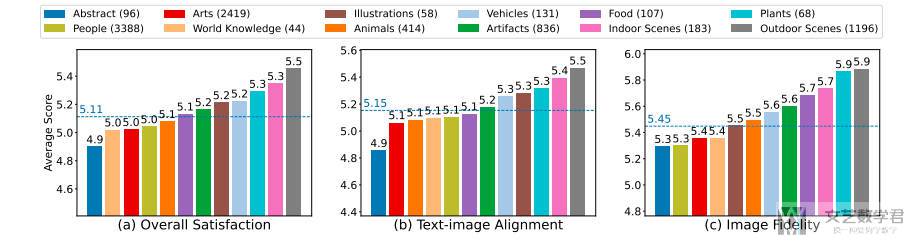
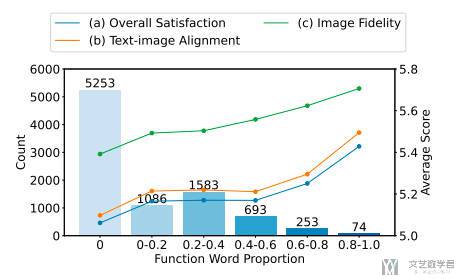
上面是两个数据标注的过程,接着作者对标注的结果进行了分析。例如对不同场景打分的值:
同时,作者发现一些功能词(8k、highly detailed 等)确实可以提升图像生成的质量。
RM 模型如何训练(RM Training)
在有了 ranking data 的数据之后,就可以训练 RM 模型。这部分与 RLHF 技术笔记 中的 「关于训练 RM 模型的损失函数」的介绍是一样的,希望好的结果 x(i) 的得分要大于坏的结果 x(j),f 就是 reward model,根据 prompt 和生成的图像给出一个 scalar:
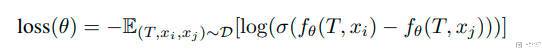
ImageReward 的实验结果
在有了 ImageReward 之后,我们就可以从生成的众多结果中来挑选最符合人类偏好的。之前我们可能会通过 CLIP SCORE 来对生成的结果进行打分,即 corresponds to the cosine similarity between visual CLIP embedding E_i for an image i and textual CLIP embedding E_C for an caption C:
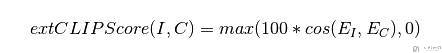
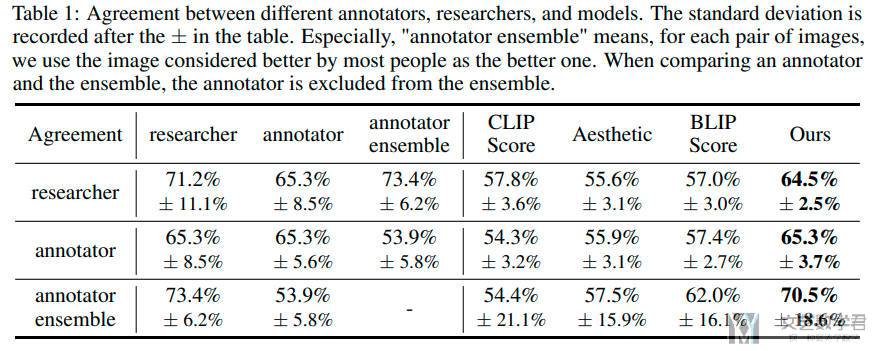
作者比较了 agreement,也就是不同方法选出的最优的结果有多少是相同的。最后可以看到本文的方法选出的结果会和人类选出的 best image 比较接近,比 CLIP Score 等的结果要好。
作者对同一个 prompt 生成 64 个图片,并根据不同的方法选出前 3 的图片,结果如下。可以看到使用 ImageReward 选出的图片质量较好:

一些想法
- 作者这里收集数据时的 Stage 1 其实模型训练时候没有用到,只在数据分析和最后结果分析的时候用到了。可以对于不同的标准(例如 Alignment、Fidelity 和 Harmlessness)训练不同的 reward model,这样更加方便标注人员进行标注。同时也可以更好的对结果进行选择;
- 对于其他的领域,例如自动驾驶的轨迹生成领域,我们可以对同一个情况生成的不同轨迹进行打分,打分也是可以分为多个角度,轨迹是否符合人类,安全性;
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论