文章目录(Table of Contents)
简介
本文主要介绍如何使用 vision-language model 来作为强化学习的 reward 函数。整体的思想非常简单,对于一些任务来说,我们无法使用数学式子写出奖励函数,但是我们可以使用自然语言描述。同时现在 vision-language model 可以同时对文字和图像进行编码,我们认为相似文字对应的图像在隐空间内会是相似的,于是我们利用这个相似来作为奖励。
参考资料
- VLM-RMs,paper 的链接。
- Github for vlmrm,本文对应的代码。
- Vision-Language Models are Zero-Shot Reward Models for Reinforcement Learning,Blog for this paper,里面包含大量的实验效果图。
论文背景及主要贡献
问题背景
强化学习(RL)的训练需要手动指定奖励函数,这在许多情况下是不可行的,或者需要从大量的人类反馈中学习奖励模型,这往往会非常昂贵。为了使 RL 在实际应用中更有用,寻找更有效的、自然的方式来指定奖励函数至关重要。
本文的方法
传统的方法包括手动指定奖励函数或者从人类反馈中学习奖励模型。另一种自然的方法是使用预训练的视觉-语言模型(vision-language model,VLMs),如 CLIP 和 Flamingo,根据自然语言提供奖励信号。然而,之前使用 VLMs 提供奖励的尝试需要对 VLMs 进行大量的微调,或者使用复杂的特设程序从 VLMs 中提取奖励。
本文方法和主要贡献
本文提出了一个名为 VLM-RM 的方法,这是一种使用预训练的 VLMs 作为视觉基础 RL 任务的奖励模型的通用方法。具体来说,本文使用 CLIP 作为 VLM,将当前环境状态的 CLIP 嵌入和简单语言提示的 cos-相似度作为奖励函数。本文还可以通过提供描述环境中性状态的“基线提示”,并在计算奖励时将表示部分投影到基线提示和目标提示之间的方向上,对奖励模型进行正则化。
本文的主要贡献有四个方面。
- 首先,提出了VLM-RM方法,这是一种使用预训练的 VLMs 作为视觉基础 RL 任务的奖励模型的通用方法。
- 其次,我们在标准的 CartPole 和 MountainCar RL 基准测试中验证了本文的方法。
- 第三,训练了一个 MuJoCo 人形机器人来学习复杂的任务,如举起手臂,坐在莲花位,做劈叉,和跪下。
- 最后,研究了 VLM-RMs 的性能如何随 VLM 的大小而变化,发现 VLM 的规模与 VLM-RM 的质量强烈相关(VLM 模型大小越大越好)。
方法
使用 VLM 作为奖励
首先考虑一个没有奖励函数的 POMDP(部分可观察马尔科夫决策过程)。我们关注的是基于视觉的RL,其中观察值是图像(相当于 state 是图像)。我们希望代理执行一个基于自然语言描述的任务。例如,当控制一个人形机器人时,任务可能是机器人在地上跪下,而语言描述可能是"一个人形机器人跪下"(也就是目标是一个自然语言)。于是本文尝试使用 VLM 来给强化学习提供奖励。
在本文的实验中,我们选择了 CLIP 编码器作为 VLM。使用 CLIP 定义奖励函数的一个非常基本的方法是使用状态的图像表示和自然语言任务描述之间的余弦相似度:
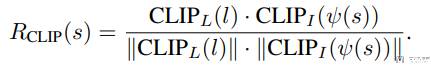
这里 l 表示我们对任务的自然语言描述,v(s) 表示状态的图像表示。CLIP_l 和 CLIP_L 分别是对图像 v(s) 和自然语言 l 的编码,我们希望他们的余弦相似度越接近越好。
使用 Goal Baseline 优化奖励
在上一个小结中,我们介绍了使用 CLIP 定义奖励函数。在这一节中,作者提出了目标-基线正则化作为一种通过投影出观察中无关信息来改善奖励质量的方法。
到目前为止,我们假设我们只有一个任务描述(也就是上面的自然语言 l)。为了应用目标-基线正则化,我们需要一个第二个“基线”描述。基线是对环境在其默认状态下的设置的自然语言描述,与目标无关,我们定义为 b 。
例如,我们的人形机器人的基线描述 b 就是“一个人形机器人”,而任务描述 l 是“一个人形机器人跪下”。我们通过将状态嵌入投影到基线和任务嵌入所跨越的线上,得到目标-基线正则化的 CLIP 奖励模型。新的奖励使用下面的式子来表示:

其中,α 是一个用来控制正则化强度的参数。特别地,对于 α=0,我们恢复到我们的初始 CLIP 奖励函数。另一方面,对于α=1,投影会移除所有与 g-b 垂直的 s 的组成部分。关于为什么 α=0 的时候,上面的式子可以转换为初始 CLIP 奖励函数,可以参考 余弦距离与欧式距离。核心就是当向量的模长是经过归一化的,此时欧氏距离与余弦距离有着单调的关系:
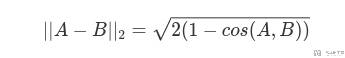
直观地说,从 b 到 g 的方向捕获了从环境的基线到目标状态的变化。通过将奖励投影到这个方向上,我们方向性地移除了 CLIP 表示的无关部分。然而,我们不能确定这个方向真的捕获了所有相关的信息。因此,我们将 α 视为一个超参数。但是,我们发现该方法对 α 的变化相对稳健,大多数中间值都比 0 或 1 好。
实验结果
这里作者首先在 CartPole 和 MountainCar 上进行了实验,并绘制出奖励函数。可以看到在 CartPole 环境中,奖励函数是在中间是最大的,这与实际是符合的。对于 MountainCar 环境来说,可以看到原始的环境图像对于 VLM 的效果不好,我们认为是这个图像过于抽象了,但是加上纹理之后,得到的奖励函数就会是正确的:
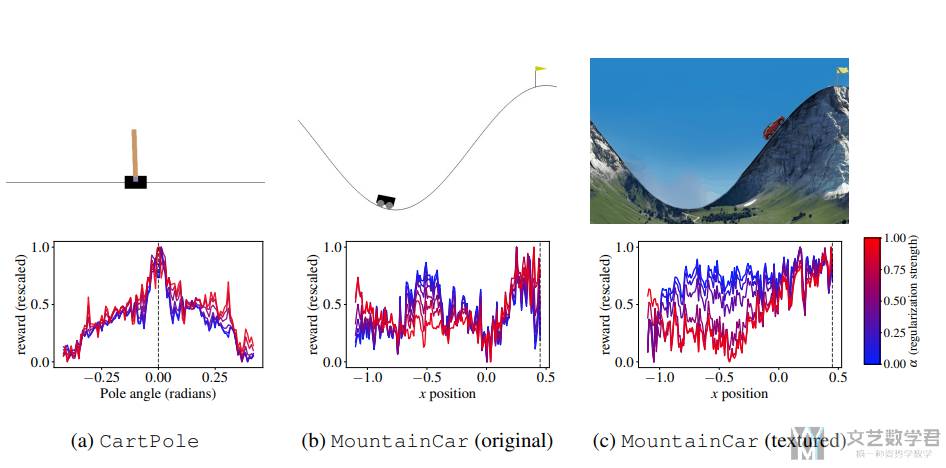
同时作者也是比较了不同模型大小的 VLM 会对结果的影响,最终结果如下所示。可以看到增大模型的大小是可以显著改善成功率的:

- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论