文章目录(Table of Contents)
简介
这一篇文章主要介绍分类器结果的可视化. 也就是我们希望可以绘制出分类器的分类的边界. 当然, 我们在二维的平面上进行绘制, 关于如何将数据降2维, 可以使用PCA等方法, 具体步骤参考: 主成分分析(Principal component analysis, PCA)例子–Python
主要思想
关于绘制分类器边界的主要思想其实很简单, 就是将一个区域内的所有点都放入分类器, 来得到分类器的分类的结果, 从而就可以绘制出分类器的边界了.
参考链接
主要参考链接来自sklearn的官方的教程: Plot the decision boundaries of a VotingClassifier
我在下面讲例子的时候会进行一些修改, 即进行颜色的自定义和加上legends.
案例实验
导入需要使用的库
首先我们导入需要使用的库.
- from itertools import product
- import numpy as np
- import matplotlib.pyplot as plt
- from sklearn import datasets
- from sklearn.tree import DecisionTreeClassifier
- from sklearn.neighbors import KNeighborsClassifier
- from sklearn.svm import SVC
- from sklearn.ensemble import VotingClassifier
导入数据集
我们使用iris数据集作为例子, 接着我们导入需要使用的数据集. 为了可视化的方便, 我们就只使用前两个维度的特征. 一共有150个数据.
- # Loading some example data
- iris = datasets.load_iris()
- X = iris.data[:, [0, 2]]
- y = iris.target
- # 查看数据大小
- X.shape, y.shape
- """
- ((150, 2), (150,))
- """
模型的训练
接着我们训练我们需要使用的分类器, 我们使用SVM, RF, KNN来训练三个分类器, 接着使用投票的方式将三个分类器进行综合.
- # Training classifiers
- clf1 = DecisionTreeClassifier(max_depth=5)
- clf2 = KNeighborsClassifier(n_neighbors=7)
- clf3 = SVC(gamma=.1, kernel='rbf', probability=True)
- eclf = VotingClassifier(estimators=[('dt', clf1), ('knn', clf2), ('svc', clf3)],voting='soft', weights=[2, 1, 2])
- clf1.fit(X, y)
- clf2.fit(X, y)
- clf3.fit(X, y)
- eclf.fit(X, y)
- """
- VotingClassifier(estimators=[('dt', DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=7,
- max_features=None, max_leaf_nodes=None,
- min_impurity_decrease=0.0, min_impurity_split=None,
- min_samples_leaf=1, min_samples_split=2,
- min_weight_fraction_leaf=0....',
- max_iter=-1, probability=True, random_state=None, shrinking=True,
- tol=0.001, verbose=False))],
- flatten_transform=None, n_jobs=None, voting='soft',
- weights=[2, 1, 2])
- """
分类器边界的绘制
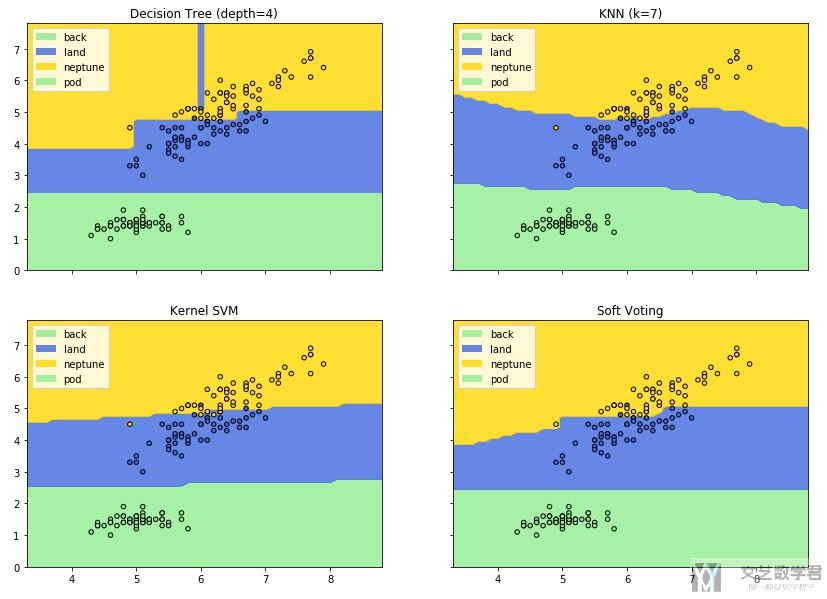
接下来我们要绘制分类器的边界. 绘制边界最简单的想法就是将平面内的数据点都放入预测模型进行预测, 对返回的结果标上不同的颜色. 所以我们首先要做的事情就是取点.
- # Plotting decision regions
- x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
- y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
- xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1), np.arange(y_min, y_max, 0.1)) # 产生所有需要用来预测的数据点
接着我们将上面生成的点放入上面训练好的预测模型中, 得到预测值, 最后进行绘图, 即可以完成. 注意, 我们这里和官方的教程会有一些不同, 我们加上了颜色的控制和加上了Legends. 看一下代码.
- f, axarr = plt.subplots(2, 2, sharex='col', sharey='row', figsize=(14, 10)) # 一个需要画出四张图
- colors = ['lightgreen', 'royalblue', 'gold'] # 每一种分类的颜色
- index2colors = {0:'lightgreen', 1:'royalblue', 2:'gold'}
- for idx, clf, tt in zip(product([0, 1], [0, 1]), [clf1, clf2, clf3, eclf], ['Decision Tree (depth=4)', 'KNN (k=7)','Kernel SVM', 'Soft Voting']):
- print(idx)
- # clf表示分类器
- # tt表示图像的名字
- Z = clf.predict(np.c_[xx.ravel(), yy.ravel()]) # 展平所有的xx和yy, 接着拼接在一起, 当作输入进行预测
- Z = Z.reshape(xx.shape)
- axarr[idx[0], idx[1]].contourf(xx, yy, Z, levels=[-0.5,0.5,1.5,2.5,3.5], colors=colors, alpha=0.8)
- # 绘制图例
- proxy = [plt.Rectangle((0,0), 1, 1, fc = pc.get_facecolor()[0]) for pc in axarr[idx[0], idx[1]].collections]
- axarr[idx[0], idx[1]].legend(proxy, ['back', 'land', 'neptune', 'pod', 'smurf', 'teardrop'])
- # 绘制散点图
- axarr[idx[0], idx[1]].scatter(X[:, 0], X[:, 1], c=[index2colors.get(i) for i in y], s=20, edgecolor='k')
- axarr[idx[0], idx[1]].set_title(tt)
- plt.show()
注意一下在绘制散点图的时候, 我们对color的指定的方法, 我们把每一个点的label都转换成了他对应的颜色. 最终绘制出的效果如下所示.
仓库代码
最后是github的链接, 源文件可以在这上面进行下载: Github--分类器可视化(二维平面)
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-










评论