文章目录(Table of Contents)
简介
本文会来介绍「注意力分数」的计算。特别的,这里我们会使用高维的 query ,key 和 value 来举例子。可以将「注意力分数」理解为 query 和 key 的相似度。
也就是,首先计算 query 和 key 的相似度,得到「注意力分数」,接着对「注意力分数」进行 softmax。有两种常见的「注意力分数」的计算方式,分别是(1)「加性注意力」,将 query 和 key 合并起来放在单层 MLP;(2)「内积注意力」,将 query 和 key 作内积运算;
参考资料
- Attention Mechanisms(注意力机制),本文的相关代码(包含「加性注意力」和「内积注意力」两个部分的代码);
- 动手学深度学习在线课程,包含完整的课程大纲;
- 65 注意力分数【动手学深度学习v2】,B 站视频;
注意力分数
回顾之前在一维数据的时候,计算 query 对应的 value,使用如下的式子:
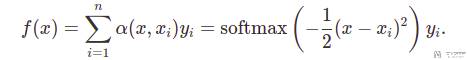
现在我们将数据扩展为高维,注意下面的 q,k,v 的长度可以全部不一样:

于是上面一维数据对应的式子会变为下面的式子:
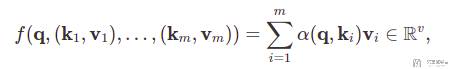
上面式子中的 α(q, k_i) 可以写为下面的式子:
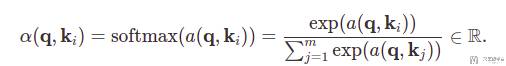
其中最关键的就是 a(q, k_i) 的计算(q,k 的长度可能是不一样的)。下面会介绍两种常见的a(q, k_i) 的计算方式,分别是「加性注意力(Additive Attention)」和「内积注意力(Scaled Dot-Product Attention)」。
加性注意力(Additive Attention)
加性注意力介绍
首先介绍「加性注意力」。这里可以学习的参数有三个,分别是:

于是上面的a(q, k_i)可以被写为下面的式子:
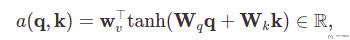
在上面的式子中,Wq得到一个长度为 h 的向量。Wk得到一个长度为 h 的向量。接着将这两者加起来,得到一个长度为 h 的向量。最后使用 w_v 与上面长度为 h 的向量相乘,输出大小为 1 的值。将上面的式子转换为流程图如下所示:
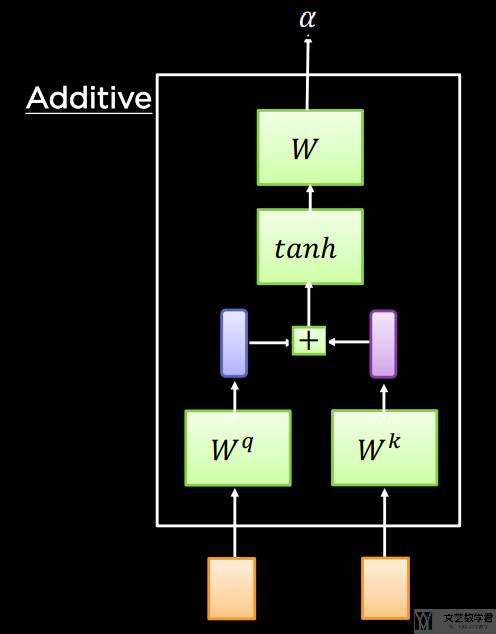
对于加性注意力,可以理解为将 key 和 query 首先并起来,然后放入一个隐藏层为 h,输出大小为 1 的单隐藏层 MLP。使用「加性的注意力」,q,k 和 v 三者之间可以是不一样的。
加性注意力数值例子
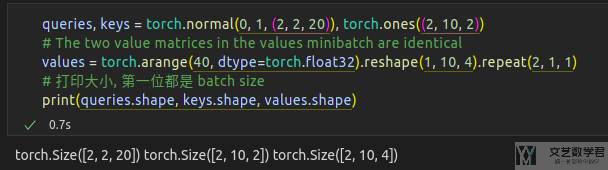
下面看一个具体的「加性注意力」的例子。现在 batch size=2,对于每一个 batch,我们有:
- 两个
query,每个query向量长度是20。 - 有
10个key-value pair,其中:key为长度为2的向量;value为长度为4的向量;
对于 key,value,query的生成如下所示:
首先我们将 query 和 key 都转换为长度一样的向量,这里全部转换为长度为 16的向量:

接着将 Wq与 Wk 相加。相当于每一个 query 会和一个 key 计算一个向量。一共有 2 个 query,每个 query 会和 10 个 key 得到一个向量: 
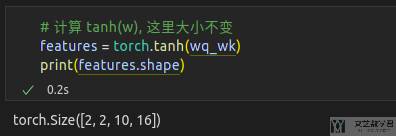
下一步计算 tanh的值,此时向量的大小是不会改变的:
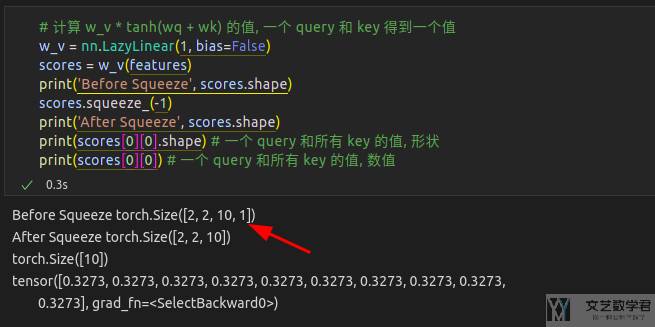
接着我们计算 w_v × tanh(wq + wk) 的值,计算每个 key 和 query 的注意力分数。此时就会把上面长度为 16 的向量转换为程度为 1 的值:
最后我们对上面的「注意力分数」进行归一化即可,使得一个 query 对所有 key 的值求和为 1 。
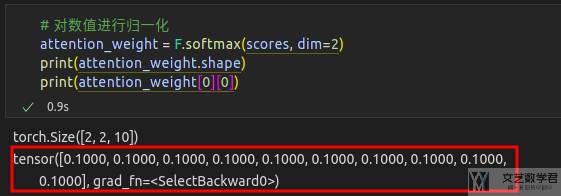
Masked Softmax
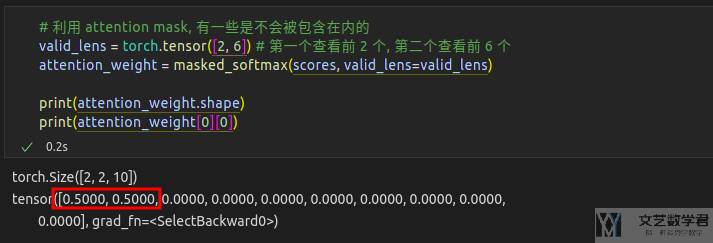
当然另外一种常见的情况是 masked softmax,也就是假设一些 key 是不会被用到的,于是归一化的时候可以不考虑这些值。下面的例子我们设置只考虑前面的两个 key-value pair:
内积注意力(Scaled Dot-Product Attention)
内积注意力介绍
如果我们的 key 和 query 的长度是一样的,例如他们的长度都是 d,那么 a(q, k_i) 可以被写为下面的式子:
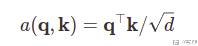
在上面的式子中,除根号 d 是使得 a(q, k_i) 对向量长度不敏感。上面这个式子是没有可以学习的参数的。
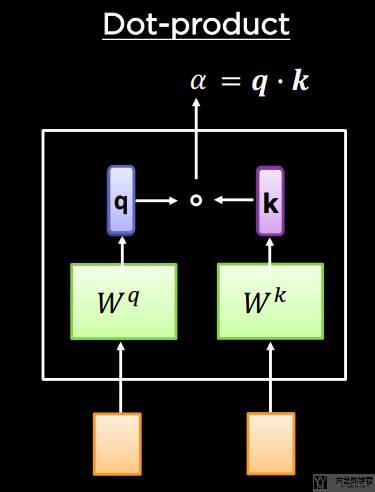
我们可以进一步扩展上面的「内积注意力」,加入可以训练的参数,同时也是可以处理 key 和 query 长度不同的情况。于是「内积注意力」整体的结构如下图所示:
内积注意力数值例子
下面我们通过一个具体的例子来看一下「内积注意力」是如何进行计算的。
现在 batch size=2,对于每一个 batch,我们有:
- 两个
query,每个query向量长度是2。 - 有
10个key-value pair,其中:key为长度为2的向量(这里query和key向量的长度是一样的);value为长度为4的向量;
对于 key,value,query的生成如下所示:
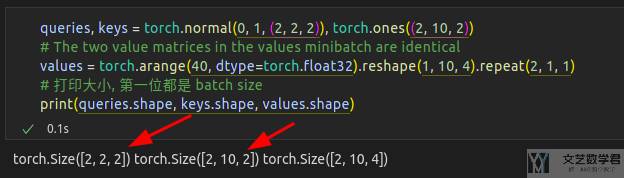
接着我们计算 q × k / sqrt(d) 的值。此时每个query 和一个 key会计算出一个相似度得分。
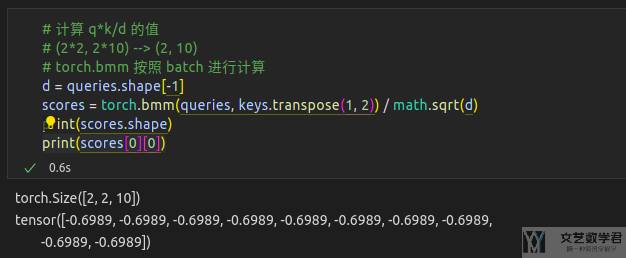
最后我们将上面的 scores 归一化即可,一个 query 对十个 key的得分求和要是 1:
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-









评论