文章目录(Table of Contents)
简介
在实际中,我们希望有一个这样的效果:给定相同的 queries、keys 和 values,我们希望模型可以学习到不同的内容,然后将这些内容给组合起来。
为了实现「多头注意力」,我们可以使用不同的变化去将 queries、keys 和 values 变为不同的值,接着利用变换后的去计算注意力。最后将 N 个注意力的输出拼接在一起,并通过另外一个可以学习的线性投影进行变化,以产生最终的输出。下图展示一个「多头注意力」模型结构:
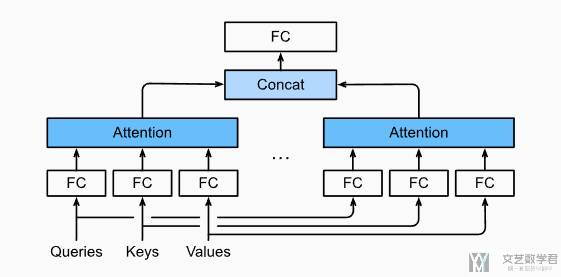
可以看到 queries、keys 和 values 通过不同的「全连接层」计算出不同的值,来计算「注意力」。最后将注意力 concat 在一起,在通过一个「全连接层」。
参考资料
- Multi-Head Attention,D2L 英文版 Multi-Head Attention 的内容;
- 多头注意力,D2L 中文版「多头注意力」的内容;
- 68 Transformer【动手学深度学习v2】, B 站视频,介绍「多头注意力」;
- Attention-mechanisms-and-transformers,本文对应的代码,multihead_attention 开头的;
多头注意力模型
模型描述--图解
下面我们以 2 个 heads 作为例子,看一下「多头注意力」模型。如下图所示,我们首先将同一个 query 乘不同的系数(q_i = W*q)得到不同的 q。keys 和 values 也进行类似的处理。此时相当于一个相同的 query,我们通过乘不同的系数得到了两个新的 query。
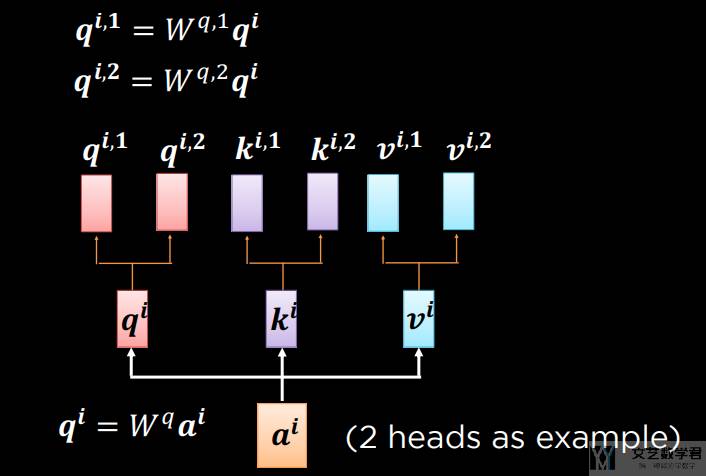
上面我们就得到了两组 queries、keys 和 values。接着我们分别计算注意力。下图首先使用一组进行注意力的计算。注意这里的 b 是加权之后的结果。
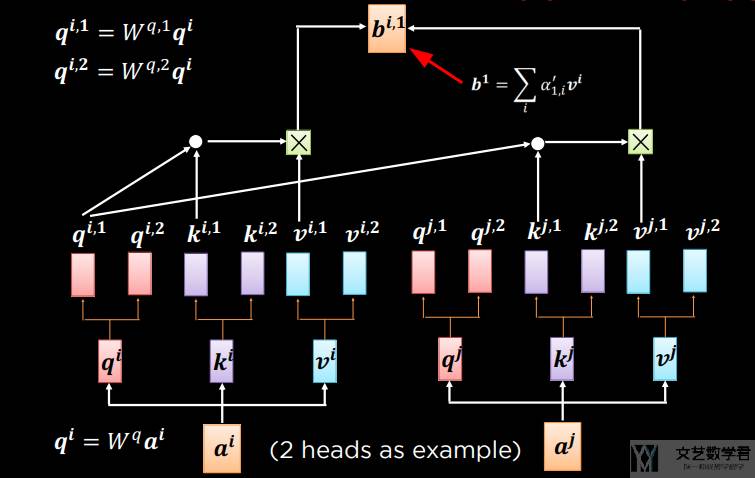
接下来计算另外一组的注意力。如下图所示,此时我们就有了 b1 和 b2。
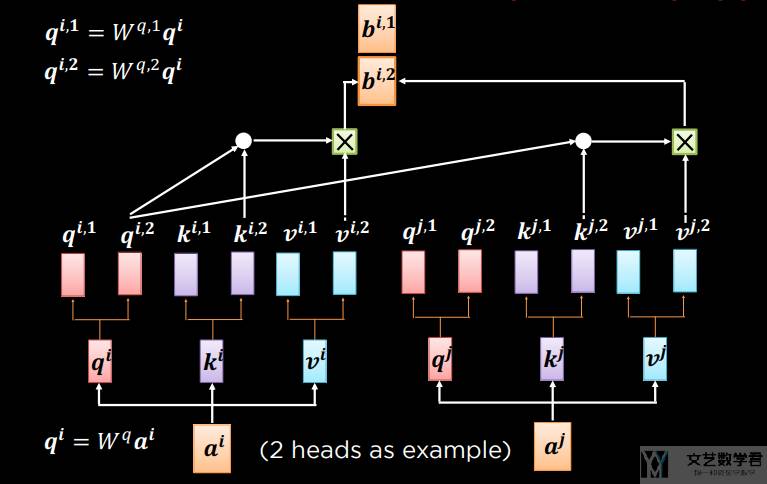
在有了 b1 和 b2 之后,我们将其合并,在通过一个「全连接层」来作为输出。
模型解释-数学语言
上面我们非常直观的看了「多头注意力」的计算方式。下面我们用数学语言将这个模型形式化地描述出来。给定「查询 q」,「键 k」和「值 v」,给个「注意力头 h」 的计算方式如下:
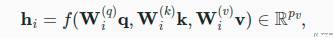
这里可以学习的参数有三个 W,以及注意力汇聚函数 f(这里 f 是加性注意力和缩放点积注意力)。多头注意力的输出需要经过另一个线性转换,如下所示,这里也有一个可以学习的参数 W。
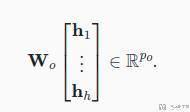
基于这种设计,每个头都可能会关注输入的不同部分, 可以表示比简单加权平均值更复杂的函数。
多头注意力代码实现
上面我们解释了「多头注意力」的机制,下面看一下代码的实现。具体计算的时候,为了可以并行运算,我们不会定义多组 W,而是会定义一个大的 W,然后进行拆分。
我们首先定义 query 和 key-value pair。共有 4 个 queries, 6 个 key-value pairs。且我们设置 heads 的数量为 5。
- batch_size = 2 # batch 数量
- num_heads = 5 # multi head 的数量
- num_queries = 4 # query 的数量为 4
- num_kvpairs = 6 # kvpair 的数量为 6
- valid_lens = torch.tensor([3, 2])
- X = torch.ones((batch_size, num_queries, 10)) # query
- Y = torch.ones((batch_size, num_kvpairs, 20)) # key, value
- print(X.shape, Y.shape)
- # torch.Size([2, 4, 10]) torch.Size([2, 6, 20])
上面我们提到「多头注意力」是需要使用不同的参数 W 去乘 「查询 q」,「键 k」和「值 v」。但是为了可以并行运算,比如一个参数 W 可以将其转换为 20 维的特征,一共有 5 个 heads,那么我们就直接使用转换为维度为 100,然后再进行切分,将 head 数据和 batch 数据放在一个维度。
我们首先定义函数 _transpose_qkv,目的是将 head 维度拆出来。例如本来是 (batch_size,查询或者“键-值”对的个数,num_hiddens),这里 num_hiddens 其实是包含所有 heads 的,于是函数 _transpose_qkv 可以将其转换为 (batch_size,查询或者“键-值”对的个数,num_heads,num_hiddens/num_heads),然后把 heads 和 batch 和在一起,变为 (batch_size*num_heads,查询或者“键-值”对的个数, num_hiddens/num_heads)。
- def _transpose_qkv(X, num_heads):
- """为了多注意力头的并行计算而变换形状, 不要因为 multi-head, 而多一个循环
- """
- # 输入 X 的形状:(batch_size,查询或者“键-值”对的个数,num_hiddens)
- # 输出 X 的形状:(batch_size,查询或者“键-值”对的个数,num_heads,num_hiddens/num_heads)
- # 有多少个 head, 做一下切分, 比如会从 torch.Size([2, 4, 100]) --> torch.Size([2, 4, 5, 20])
- X = X.reshape(X.shape[0], X.shape[1], num_heads, -1)
- # 输出X的形状:(batch_size,num_heads,查询或者“键-值”对的个数, num_hiddens/num_heads)
- # 交换维度, 将 num_heads 和 查询或者“键-值”对的个数 交换
- # 此时的大小为 torch.Size([2, 5, 4, 20])
- X = X.permute(0, 2, 1, 3)
- # 最终输出的形状:(batch_size*num_heads,查询或者“键-值”对的个数, num_hiddens/num_heads)
- # 最终大小变为 torch.Size([10, 4, 20])
- return X.reshape(-1, X.shape[2], X.shape[3])
具体「查询 q」,「键 k」和「值 v」的转换如下。batchsize=2,num_heads=5,最终输出的大小第一维为 10,也就是 batch_size*num_heads。
可以理解为,共有 10 组数据,每组数据有 4 个 query 和 6 和 key-value pairs。这些值的特征维度都是 20。要对这 4 个 query 计算特征。
- num_hiddens = 100
- W_q = nn.LazyLinear(num_hiddens, bias=False)
- W_k = nn.LazyLinear(num_hiddens, bias=False)
- W_v = nn.LazyLinear(num_hiddens, bias=False)
- queries = _transpose_qkv(X=W_q(X), num_heads=num_heads) # torch.Size([10, 4, 20])
- keys = _transpose_qkv(W_k(Y), num_heads=num_heads) # torch.Size([10, 6, 20])
- values = _transpose_qkv(W_v(Y), num_heads=num_heads) # torch.Size([10, 6, 20])
- print(queries.shape, keys.shape, values.shape)
- # torch.Size([10, 4, 20]) torch.Size([10, 6, 20]) torch.Size([10, 6, 20])
接下来计算这 10 组数据的注意力。最终 out 的大小为 (batch_size * num_heads, no. of queries, num_hiddens / num_heads)。
- attention = DotProductAttention(0.1)
- valid_lens = torch.repeat_interleave(valid_lens, repeats=num_heads, dim=0)
- output = attention(queries, keys, values, valid_lens)
- print(output.shape) # 计算每个 query 的值, 为 (10, 4, 20)
- # torch.Size([10, 4, 20])
我们相当于是将 multihead 的当作不同 batch 在计算,现在需要把 mutil-head 放回去。形状改变的代码如下所示,也就是将输入形状从 (batch_size * num_heads, no. of queries, num_hiddens / num_heads) 转换为 (batch_size , no. of queries, num_hiddens)。这里相当于已经是将不同 head 得到的结果进行了拼接了。
- def _transpose_output(X, num_heads):
- """逆转transpose_qkv函数的操作
- """
- # 将 num_heads 的维度信息从 batch size 中拿出来
- # 也就是 torch.Size([10, 4, 20]) --> torch.Size([2, 5, 4, 20]), 这里 num_head = 5
- X = X.reshape(-1, num_heads, X.shape[1], X.shape[2])
- # 交换 num_heads 与 查询或者“键-值”对的个数
- # 此时从 torch.Size([2, 5, 4, 20]) --> torch.Size([2, 4, 5, 20])
- X = X.permute(0, 2, 1, 3)
- # 最后将 num_head 的信息合并起来
- # 从 torch.Size([2, 4, 5, 20]) --> torch.Size([2, 4, 100])
- return X.reshape(X.shape[0], X.shape[1], -1)
我们对前面输出的 out 进行形状的变换。最终的大小从 (10, 4, 20) 变为 (2, 4, 100)。
- output_concat = _transpose_output(output, num_heads=num_heads)
- # 将 num_head 从 batch_size 中拿出来, torch.Size([10, 4, 20]) --> torch.Size([2, 4, 100])
- print(output_concat.shape)
- # 这里的 100 相当于是 multi-head 集和后的结果
最后再通过一个线性变换就可以得到最终的结果。也就是对应下面的式子:
实现起来就是多加一个全连接层即可。
- W_o = nn.LazyLinear(32, bias=False)
- result = W_o(output_concat)
- print(result.shape) # torch.Size([2, 4, 100]) --> torch.Size([2, 4, 32])
- # torch.Size([2, 4, 32])
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-









评论