文章目录(Table of Contents)
简介
这一篇介绍关于"网络加密流量分类"的论文写作的相关内容. 参考国内的一些硕士和博士的论文, 给出每一个部分书写的内容.
文章的主体结构大致分为下面的几个部分.
- 研究背景 (Introduction)
- 相关工作 (Related works)-这里说一下传统的流量分类的方法
- Port-based approach
- Payload inspection techniques
- Statistical and machine learning approach
- Raw data
- 背景知识 (Background on deep neural networks)
- 提出的方法 (Methodology)
- 首先放出一张整体的结构图, 包含数据处理和后面的网络结构, 然后后面依次叙述. 这里没有小标题.
- Dataset
- Pre-processing
- Architectures (上面提到的网络的具体的结构)
- 实验设计与结果分析 (Experimental results)
- 评价指标介绍 (metrics)
- compare with previous results
- Discussion
下面就是摘录一下每一个部分书写的相关内容(以下所有的内容都是别人论文里的原句, 不能直接进行抄袭).
研究背景 (Introduction)
随着计算机网络技术的高速发展,互联网己经覆盖了社会生活的各个方面。如今,网络技术在经济、军事、教育等各社会领域都有着非常广泛而深入的应用。与其他科学技术一样,网络技术也是一把双刃剑。它的快速发展和广泛应用,一方面推动着社会经济的快速发展,另一方面也带来了前所未有的挑战。
网络流量分类作为一种有效的防护手段,可以帮助网络安全人员进行网络的防御。网络流量分类的主要任务是预测网络数据流的协议和应用类型。随着高吞吐流量需求的快速增长,流量分类任务对于网络管理和服务质量而言至关重要。而且对于运营商和服务商而言,实现网络流量分类意味着其可以对主干网和服务网实现很好的认知和管控,可以对所有的用户实现合理的收费和管理,也就意味着对其QoS服务质量保障起到至关重要的作用。另外,网络流量分类还可以帮助解决网络安全监控等问题,实现对异常流量的识别和监控。(首先说明网络流量的分类很重要)
目前网络流量分类问题面临越来越大的挑战, 加密流量呈现爆发式的增长. 近些年来随着保护传输数据和用户隐私等需求的迅速增加, 越来越多的应用和协议使用加密方法传输数据, 网络中加密流量的比例急剧上升。这个给传统的流量分类带来了较大的困难. (接着说明因为目前网络上加密流量变多, 所以我们要做加密流量的分类)
按照所在ISO/OSI协议层的不同,流量加密分为应用层加密、表示层加密和网络层加密。(接着简单介绍加密流量的种类, 有下面的三种情况)
- 应用层加密是指网络应用在应用层实现专用的加密传输协议,例如BitTorrent, Skype,这种方式在某些文献中也称为常规加密。
- 表示层加密和网络层加密是指在各自协议层对上层数据包进行整体加密,代表技术分别是TLS和IPsec,例如VPN之类的隧道技术就采用了上述加密技术,这种方式在某些文献中也称为协议封装(ProtocolEncapsulation).
- 有时,流量会在常规加密后进行进一步协议封装,例如通过VPN通信的Skype流量。
这里再次强调一下, 这种多样化的加密方式更是给流量的分类任务造成了巨大的困难.
按照具体业务需求不同,加密流量分类任务分为五种。
- 将流量分为未加密流量和加密流量,又称为加密流量识别。
- 识别加密流量使用的协议
- 将加密流量分为各种服务类型,例如聊天应用、视频流应用等,又称为流量特性刻画。
- 将加密流量分类至具体的某个网络应用。如微信,QQ等具体的应用。
- 对异常的加密流量进行识别
其中,加密流量识别相对简单,技术相对成熟。由于网络应用种类繁多且版本复杂,将加密流量分类至具体某个网络应用的任务相对困难。本文主要的研究方向是(说明加密流量分类目前的主要研究方向, 和自己这一篇文章的研究方向)
传统的网络流量分类方法主要分四类基于端口的方法、基于DPI(深度报文检测,DeepPacketInspection)的方法、基于统计的方法、基于行为的方法等。(目前主要使用的方式)
- 其中,基于端口的方法准确性较低,基于DPI的方法无法处理加密流量且计算复杂度较高。
- 目前研究较多的是基于统计和基于行为的方法。这两种方法都是基于机器学习的思路。
- 首先设计一组流量特征集,然后针对这组流量特征集进行建模和训练,训练好的模型可以对新流量进行判别和分类。
- 这两种方法不需要查看端口和解析流量,对加密流量同样适用,计算复杂度相对不高,还能发现许多复杂的流量模式,近年来受到学术界越来越多的关注。
但是,这两种方法具有传统机器学习方法普遍存在的一个问题,即需要设计一组能准确反映流量特性的特征集。特征集质量直接影响分类性能。
尽管近年来很多研宄人员都针对此问题开展工作但如何设计一组合适的流量特征集仍是一个尚未解决的研究课题。
分类效果很大程度上依赖于人工提取特征的好坏,很可能当前提取的特征并不是最佳的。而且对于不同的流量类型而言,需要很强的领域内先验知识才可以构建出一个分类效果比较好的流量分类模型。除此之外,这种方法的迁移成本太高,对于每个数据集都分别训练多个分类器,需要很大的人力成本。(目前的方式存在的问题)
提出自己的解决方法, 并说明自己方式的优势 (下面是一些例子):
Validated by simulation, our analysis reveals that the PSO-SMOTETomek method is efficient under a small dataset, and the accuracy of personality recognition is improved by up to around 10%. The results are better than those of previous similar studies. The average accuracies of the plain text dataset and the non plain text dataset are 75.34% and 78.78%, respectively. The average accuracies of the short text dataset and the long text dataset are 75.34% and 64.25%, respectively
相关工作
下面给出了不同文献对于加密流量的不同的分类方法. 加密流量分类方法分为基于载荷的分类方法和基于特征的分类方法。
基于载荷的分类方式
这种方法对应的基于端口的方法和基于深层包检测的方法。由于不同的加密方法都有其固定的协议格式,因此采用模式匹配的方式检查数据包的包头格式能够判断其是否为加密流量,即识别加密流量。但是,这种方式不能进一步分类加密流量的具体种类,因此其使用范围比较受限。
基于特征的分类方式
这种方法使用的特征主要有两类:
- 网络流特征,例如流持续时间、每秒流比特数等;
- 数据包特征,例如包大小、包的时间间隔等。根据文献对加密流量分类研究文献的统计;
按照流量加密方式划分,针对常规加密流量的分类研宄相对较多。例如,Wang等Coull等分别对P2P流量, IMessage流量, WebRTC流量进行了分类研宄,使用的特征依次为流特征、包特征、流特征,使用的分类器依次为决策树、朴素贝叶斯、随机森林等。
相对而言,针对协议封装流量的研宂较少,Aghaei等使用流特征和决策树对代理服务器流量进行了分类。Dmper-Gil等提出了一种时间流特征分类方法,在两类流量上都取得了较好效果。
背景知识(使用的方法的介绍)
这一部分需要介绍深度学习的理论基础, 包括常用的模型. 如全连接神经网络, 卷积神经网络. 下面是具体到一些可以书写的内容(可以挑一些来写).
全连接网络
- 深度学习的基本概念和发展历史
- 全连接网络的基本概念(基本结构)
- 反向传播算法
- 激活函数(介绍一下本文会使用的激活函数)
- 优化函数的介绍
卷积神经网络
- 卷积神经网络的发展历史
- 典型的CNN的结构
- 1D CNN和2D CNN的介绍(可以介绍1D CNN在NLP领域的应用, 然后可以转到对于流量的应用)
- 一些常见的CNN的结构(这个也可以放在发展史中来写)
提出的模型的框架
可以先给出一个模型的整体框架, 接着对这个框架进行解释. 结尾句的时候可以写成下面这个样子, The dataset, implementation and design details of the pre-processing phase and the architecture of proposed NNs will be explained in the following.
之后可以在这一部分详细说明数据集, 数据预处理, 模型的结构这三个部分.
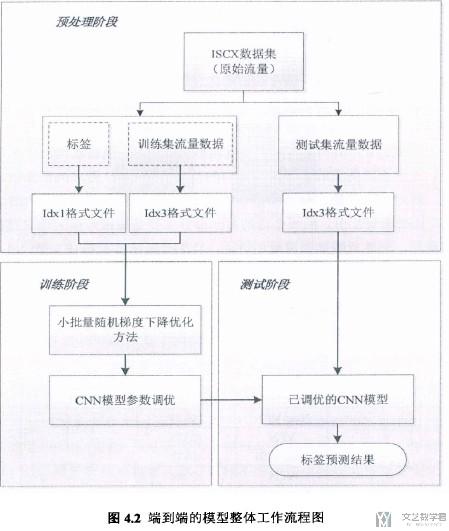
实验内容与结果
数据集介绍 (这个数据集介绍可以放在上面一部分或者实验部分)
关于数据集的介绍, 参考: 网络加密流量的相关研究-VPN-nonVPN dataset (ISCXVPN2016)
Experiment Setup
这里介绍实验简单的设置, 包括使用什么来训练网络, batchsize的大小, 优化器的选择, 学习率, 训练集和测试集的划分等. 下面是一个简单的例子.
The TensorFlow is used as experiment software framework which runs on Ubuntu 14.04 64bit OS. Server is DELL R720 with 16 cores CPU and 16GB memory. An Nvidia Tesla K40m GPU is used as accelerator. One tenth of data were randomly selected as test data, the rest is training data. The mini-batch size is 50 and the cost function is cross entropy. Gradient descent optimizer built in TensorFlow is used as optimizer. The learning rate is 0.001, training time is about 40 epochs.
评价指标介绍
实验结果比较
The results suggest that Deep Packet has outperformed other proposed approaches mentioned above, in both application identification and traffic characterization tasks.
这里就是对自己上面设计的框架和实验进行总结.
结论
为什么可以使用深度学习来解决加密流量的问题, 这是因为, "Unlike DPI methods, Deep Packet does not inspect the packets for keywords. In contrast, it attempts to learn features in traffic generated by each application. Consequently, it does not need to decrypt the packets to classify them."
同时能识别出来的原因, 可能是因为不同的App使用不同的加密算法, 有不同的伪随机数的发生器, 于是会出现特征, 也就是有pattern. (Moreover, each application employs different (non-ideal) ciphering scheme for data encryption. These schemes utilize different pseudo-random generator algorithms which leads to distinguishable patterns.)
一些可以投的期刊杂志
IEEE Communications Magazine, 有一篇综述的文章, Deep Learning for Encrypted Traffic Classification: An Overview
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论