文章目录(Table of Contents)
前言
最近在提取文本相关特征的时候,用到了TF-IDF,在这里做一下简单的介绍。
TF-IDF含义
这一部分的内容来自百度百科 : tf-idf
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术。
- TF意思是词频(Term Frequency)
- IDF意思是逆文本频率指数(Inverse Document Frequency)
下面举一个简单的例子来说明TF-IDF。
TF-IDF例子
在某个一共有一千词的网页中 "原子能"、"的" 和 "应用" 分别出现了2 次、35 次和5次,那么它们的词频就分别是 0.002、0.035 和0.005。 我们将这三个数相加,其和 0.042 就是相应网页和查询"原子能的应用"相关性的一个简单的度量。概括地讲,如果一个查询包含关键词 w1,w2,...,wN, 它们在一篇特定网页中的词频分别是: TF1, TF2, ..., TFN. (TF: term frequency)。 那么,这个查询和该网页的相关性就是:TF1 + TF2 + ... + TFN。(概括来说,这里就是简单使用词汇的频率相加)
但是显然,单独使用频率的相加是会出现问题的。在上面的例子中,词"的"占了总词频的 80%以上,而它对确定网页的主题几乎没有用。我们称这种词叫"应删除词"(停用词, Stopwords),也就是说在度量相关性是不应考虑它们的频率。在汉语中,停用词还有"是"、"和"、"中"、"地"、"得"等等几十个。忽略这些应删除词后,上述网页的相似度就变成了0.007,其中"原子能"贡献了 0.002,"应用"贡献了 0.005。(概括来说, 这一步去除了停用词)
但如果只是去除停用词,其实还是会存在一些其他的问题。如在网页搜索中,"应用"是个很通用的词,而"原子能"是个很专业的词,后者在相关性排名中比前者重要。因此我们需要给汉语中的每一个词给一个权重,这个权重的设定必须满足下面的条件:
一个词预测主题能力越强,权重就越大,反之,权重就越小。我们在网页中看到"原子能"这个词,或多或少地能了解网页的主题。我们看到"应用"一次,对主题基本上还是一无所知。因此,"原子能"的权重就应该比"应用"大。
那么如何来计算权重呢,如何体现出"原子能"比"应用"要重要。于是我们就计算"原子能"在所有网页中出现的次数。
概括地讲,假定一个关键词w在Dw个网页中出现过,那么Dw越大,w的权重越小,反之亦然。在信息检索中,使用最多的权重是"逆文本频率指数"(Inverse document frequency 缩写为IDF),它的公式为log(D/Dw), 其中D是全部网页数。
比如,我们假定中文网页数是D=10亿,应删除词"的"在所有的网页中都出现,即Dw=10亿,那么它的IDF=log(10亿/10亿)= log (1) = 0。
假如专用词"原子能"在两百万个网页中出现,即Dw=200万,则它的权重IDF=log(500) =2.7。
又假定通用词"应用",出现在五亿个网页中,它的权重IDF = log(2)则只有 0.3。也就是说,在网页中找到一个"原子能"的匹配相当于找到九个"应用"的匹配。
利用 IDF,上述相关性计算的公式就由词频的简单求和变成了加权求和,即TF1IDF1 + TF2IDF2 +... + TFN*IDFN。在上面的例子中,该网页和"原子能的应用"的相关性为 0.0069,其中"原子能"贡献了 0.0054,而"应用"只贡献了0.0015。这个比例和我们的直觉比较一致了。
TF-IDF计算公式
所以,我们总结一下上面讲的例子,来总结出TF-IDF的计算公式。
公式介绍(基本的计算) :

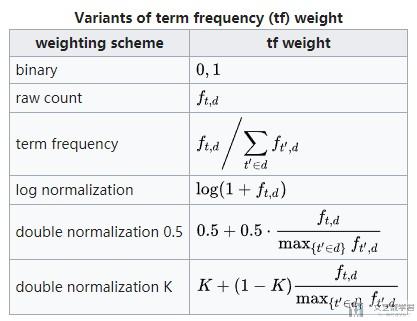
其中关于TF的计算,简单可以写成下面这个样子。

其中关于IDF的计算,简单可以写成下面这个样子。
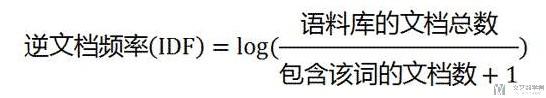
TF的计算方式(详细) :
IDF的计算方式(详细) :

TF-IDF实际计算
在实际的使用的过程中,可能不需要我们手动来进行计算。我们可以使用sklearn来进行计算。
详细的使用可以点击下面链接 : sklearn.feature_extraction.text.TfidfVectorizer
下面我们看一个简单的例子:
使用sklearn计算TF-IDF
关于更多更加详细的内容,可以参考这个链接 : sklearn: TfidfVectorizer 中文处理及一些使用参数
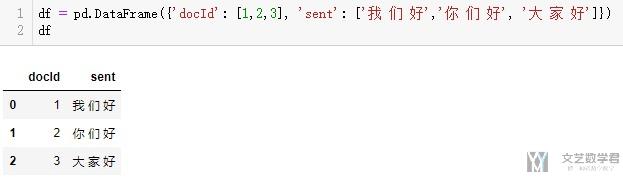
我们首先创建一下测试的样本。我们会介绍使用pandas.DataFrame和TF-IDF进行结合来进行计算。
这个例子参考自链接 : What is the simplest way to get tfidf with pandas dataframe?
- df = pd.DataFrame({'docId': [1,2,3], 'sent': ['我 们 好','你 们 好', '大 家 好']})
- df
接着我们来计算TF-IDF,下面会计算出每个字的TF-IDF。在这里,我们需要注意的是要设置token_pattern,这个参数接受正则表达式。默认情况下会忽略1个字符(但是在中文的情况下就不能忽略一个字符)
- token_pattern(默认参数) : r"(?u)\b\w\w+\b"
- token_pattern(修改之后) : r"(?u)\b\w+\b"
其中默认参数的两个\w决定了其匹配长度至少为2的单词,所以这边减到1个。
- v = TfidfVectorizer(token_pattern=r"(?u)\b\w+\b")
- x = v.fit_transform(df['sent'])
- x.toarray() # 3*7(三句话, 一共六个单词)

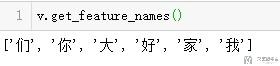
我们查看一下权重与字符的对应的关系。(上面的权重对应下面字符的顺序)
- v.get_feature_names()
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论