文章目录(Table of Contents)
介绍
有的时候,在给定数据集进行分类的时候,我们希望从中挑选出一些重要的原始特征,对分类起到至关重要的作用(因为是需要原始的特征,不能是转换之后的特征,所以不能使用PCA,或是AutoEncoder的方法)。
下面介绍几种在这个时候可以使用的方法。
测试数据集
我在这里使用的是NSL-KDD的数据集,从中挑选出smurf攻击和normal的数据,各选2646个数据集作为测试。
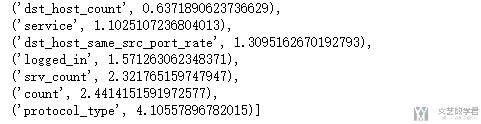
挑选出数据中最能识别出smurf攻击的特征。(这个很重要,是识别器用来识别smurf攻击的特征,不是smurf有攻击特性的特征)
方法介绍
类间距与类内方差

我们可以认为k值越大:
- 可能是两类间距较大,即m1-m2的值比较大(分子比较大)
- 或是每类之间的方差比较小, 即每一类的特征都比较紧凑(分母比较小)
- # DataProcessScale为原始数据集经过离散值处理和标准化之后的量
- # 计算normal类的均值和方差
- normalMean = DataProcessScale[DataProcessScale['labels']=='normal'].mean().values
- normalVar = DataProcessScale[DataProcessScale['labels']=='normal'].var().values
- # 计算smurf类的均值和方差
- smurfMean = DataProcessScale[DataProcessScale['labels']=='smurf'].mean().values
- smurfVar = DataProcessScale[DataProcessScale['labels']=='smurf'].var().values
- # 计算k值, +0.0001防止分母为0
- ks = abs(normalMean-smurfMean)/(normalVar+smurfVar+0.0001)
- # 将k值与label对应, 保存为dict格式
- k_value = {}
- for name,k in zip(DataProcessScale.columns,ks):
- k_value[name]=k
- # 将k值从大到小给出排序
- sorted(k_value.items(), key=lambda d: d[1])
下面是提取到的一些有区分度的特征,可以看到protocal_type, count, srv_count等有很大的区分度,其实从攻击的角度也是可以进行理解的。
- smurf攻击主要是icmp协议
- 同时service主要是echo
- 同时是一种DoS攻击,所以count数会比较多
单变量预测
第二种方法是我们每次只使用一个变量去进行Logistic Regression, 查看每个变量最后预测的准确率, 最后根据准确率排序,选出最好的几个特征。
- from sklearn.linear_model import LogisticRegression
- import seaborn as sns
- import matplotlib.pyplot as plt
- %matplotlib inline
- # 找出labels
- labels = pd.DataFrame((DataProcessScale['labels']=="normal").astype("int64"), columns=["labels"])
- # 计算每个特征的准确率
- accury = [] # 保存每个特征的准确率
- columns_names = DataProcessScale.columns.values[:41]
- for name in columns_names:
- data = DataProcessScale[name].values
- lr = LogisticRegression(solver='liblinear')
- lr.fit(data.reshape(-1,1), labels.values.squeeze())#进行拟合
- acc = lr.score(data.reshape(-1,1),labels.values.squeeze()) # 进行预测
- accury.append(acc) # 存储准确率
- # 保存为字典类型
- acc_name = {}
- for name,acc in zip(columns_names,accury):
- acc_name[name]=acc
- # 从大大小进行排序
- acc_name_sort = sorted(acc_name.items(), key=lambda d: d[1], reverse=True)
- # 进行绘图
- fig = plt.figure(figsize=(17,15))
- ax = fig.add_subplot(1,1,1)
- bar_data = [i[1] for i in acc_name_sort]
- bar_labels = [i[0] for i in acc_name_sort]
- plt.barh(range(len(bar_data)), bar_data, tick_label=bar_labels)
- plt.show()
可以查看大图,没压缩。
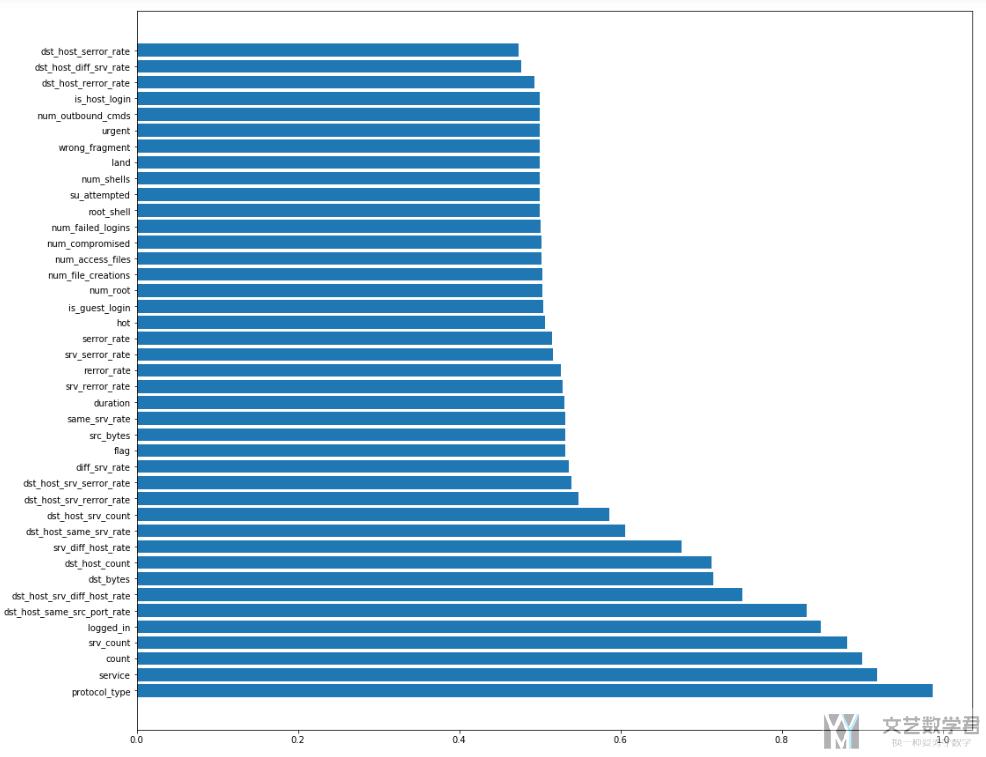
可以看到,具有区分性的特征和上面的方式分析出的差不多。有一下的几个特征是比较重要的。
- protocol_type : 协议类型(icmp)
- service : 目标主机的网络服务类型(ecr_i)
- count : 过去两秒内,与当前连接具有相同的目标主机的连接数
- srv_count : 过去两秒内,与当前连接具有相同服务的连接数
- logged_in : 成功登录则为1,否则为0(数据包内容)=>在smurf攻击中, 所有的logged_in都是0.
- dst_host_same_src_port_rate : 前100个连接中,与当前连接具有相同目标主机相同源端口的连接所占的百分比
相关系数计算
上面我们挑选出一些比较重要的特征,下面求这些特征的相关系数矩阵,并画出图。
上面选出的特征有如下:
- protocol_type : 协议类型
- service : 目标主机的网络服务类型(Smurf攻击主要是icmp)
- count : 过去两秒内,与当前连接具有相同的目标主机的连接数
- srv_count : 过去两秒内,与当前连接具有相同服务的连接数
- logged_in : 成功登录则为1,否则为0(数据包内容)=>Smurf所有的logged都是0
- dst_host_same_src_port_rate : 前100个连接中,与当前连接具有相同目标主机相同源端口的连接所占的百分比=>Smurf所有的值都是0
- dst_host_srv_diff_host_rate : 前100个连接中,与当前连接具有相同目标主机相同服务的连接中,与当前连接具有不同源主机的连接所占的百分比=>Smurf所有的值都是0
我们绘制出相关系数的矩阵的图像:
- corrData = DataProcessScale[DataProcessScale['labels']=='smurf'][['protocol_type','service','count','srv_count','logged_in','dst_host_same_src_port_rate','dst_host_srv_diff_host_rate']]
- # 绘制图像
- plt.subplots(figsize=(9, 9)) # 设置画面大小
- sns.heatmap(corrData.corr(),square=True, cmap="Blues")
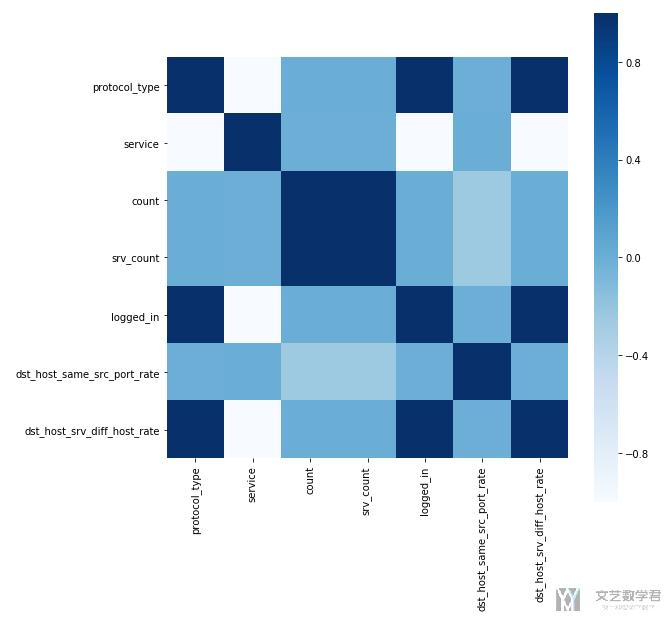
做到这一步,需要对相关性进行分析,为什么这两个变量有相关性。我这里具体就不说了,但是这一步是很重要的步骤。
结语
没什么结语了,放个图片呀。这些图片都是游戏demo中的原画,一个很好玩的游戏呀。

- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












2019年8月3日 下午11:24 1F
还有几种更常见的,比如算IV值,用随机森林之类的是吧?有一个问题,是为什么一定要用原始特征呢?原始特征的话,即使挑出来了强相关因子,也要考虑因子间共线性的吧?