文章目录(Table of Contents)
交叉检验技术简介
交叉检验原因
我们认为使用模型在做一次检查存在随机性,所以我们希望进行多次实验,来获得同一个model在不同数据集上的err的均值和方差(看一下是不是err的均值一直很大,说明模型不能很好的表达你的问题。如果err的方差很大,说明模型每次在不同数据集上训练的结果相差很大,很可能模型过于复杂,存在过拟合的可能),从而来判断模型的好坏,来选择一个好的模型。于是,就有了交叉检验的方法。(我的简单的理解)
具体步骤
- 将training set 分为N分, 其中1/N作为测试集;
- 使用不同的model(不同的参数)进行N此训练, 并在测试集上测试, 计算误差;
- 根据误差的均值与标准差, 选择出最好的模型;
- 将找出的model在整个training set上进行训练;
在下图中可以看到,我们将training set分成三份,每次两份作为训练集。将三个model分别进行训练和测试,这样会进行9次训练,接着计算三个model误差的均值与方差,选出最好的一个模型。
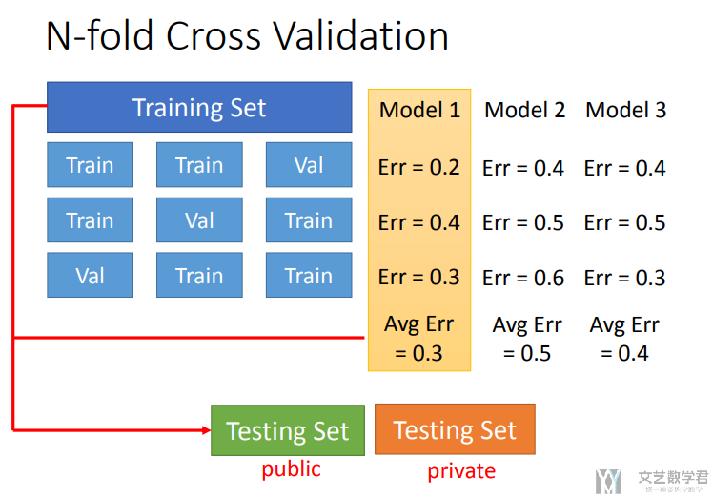
交叉检验实验
RepeatedKFold的使用
关于CV的实验,接下来会使用sklearn中的RepeatedKFold进行完成。下面先简单看一下如何进行使用。
- X = np.array([[1, 2], [3, 4], [5, 6], [7, 8]])
- y = np.array([0, 0, 1, 1])
- rkf = model_selection.RepeatedKFold(n_splits=2, n_repeats=1, random_state=777)
- for train_index, test_index in rkf.split(X):
- print("train_index:{};\ntest_index:{}".format(train_index,test_index))
- X_train, X_test = X[train_index], X[test_index]
- y_train, y_test = y[train_index], y[test_index]
- print("X_train:\n{}\n---\n".format(X_train))
他会输出list的index,在使用的时候,只需要使用X[index]这种形式即可。我们看一下最终的输出结果。

生成数据集
我们还是自己生成一些模拟的数据集,为了方便后面的测试;
- # 生成随机数据
- np.random.seed(7)
- x = np.linspace(1, 30, 30)
- y = 2*x + 0.7*x**2 - 20*np.sin(x) - 20*np.cos(x) + 5*np.random.rand(30)
- plt.style.use("ggplot") # 使用美观的样式
- plt.scatter(x, y)
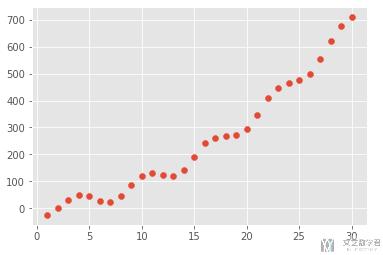
模型的选择
我们想通过CV(交叉检验)的方式选择出最好的参数,在这里我们希望选择出最好的惩罚系数的大小。
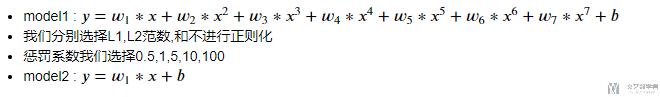
生成测试模型
- alpha_list = [0.5,1,5,10,100]
- model_list_Lasso = [Lasso(alpha=i,normalize=True) for i in alpha_list]
- model_list_Ridge = [Ridge(alpha=i,normalize=True) for i in alpha_list]
模型的测试与选择
我们以LASSO模型为例,详细代码查看文末链接地址。我们每次根据不同的数据集进行训练,同时计算每个模型的误差的均值与标准差。
- err_list_Lasso = [] # Lasso回归的误差
- Polynomia_7 = PolynomialFeatures(degree=7)
- rkf = model_selection.RepeatedKFold(n_splits=5, n_repeats=50, random_state=777) # 这里返回的是index
- for model in model_list_Lasso:
- # 每次选出一个模型
- err_list = []
- for train_index, test_index in rkf.split(x):
- # 计算每次的误差
- # 模型的拟合
- x_polynomia7 = Polynomia_7.fit_transform(x[train_index].reshape(-1,1)) # 数据的转换(训练集)
- model.fit(x_polynomia7,y[train_index]) # 计算模型参数
- # 模型的测试
- x_test_polynomia7 = Polynomia_7.fit_transform(x[test_index].reshape(-1,1)) # 数据的转换(测试集)
- model_pre = model.predict(x_test_polynomia7) # 在测试集上预测
- err = mean_squared_error(model_pre,y[test_index]) # 计算误差
- err_list.append(err)
- err_list_Lasso.append(err_list)
模型的均值与方差如下所示:
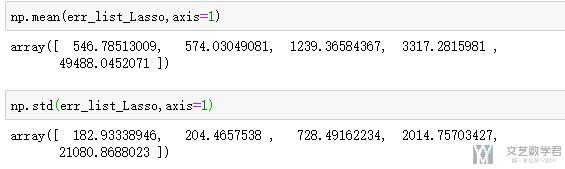
我们依次可以对剩下的模型进行同样的操作,之后可以绘制出如下的箱线图。
模型的选择
上面的所有误差可以绘制出的箱线图如下所示:
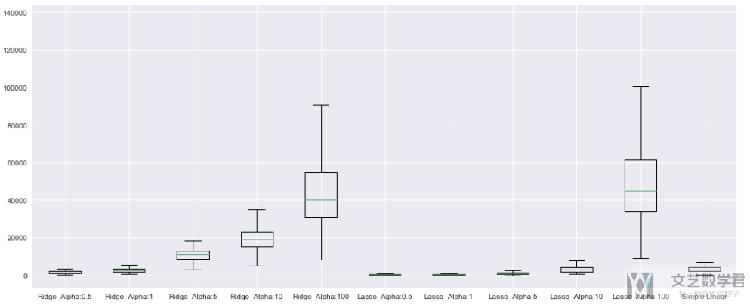
由于当惩罚系数是100时,方差太大,最后绘制出的图像不好看,我们把惩罚系数是100去掉再看一下。
- plt.style.use('seaborn')
- fig = plt.figure(figsize=(17,7))
- ax = fig.add_subplot(1, 1, 1)
- err_lists = err_list_Ridge+err_list_Lasso+[err_list_simple]
- pic_labels = ["Ridge_Alpha:{}".format(i) for i in alpha_list] + ["Lasso_Alpha:{}".format(i) for i in alpha_list] + ['Simple Linear']
- ax.boxplot(err_lists, labels=pic_labels)
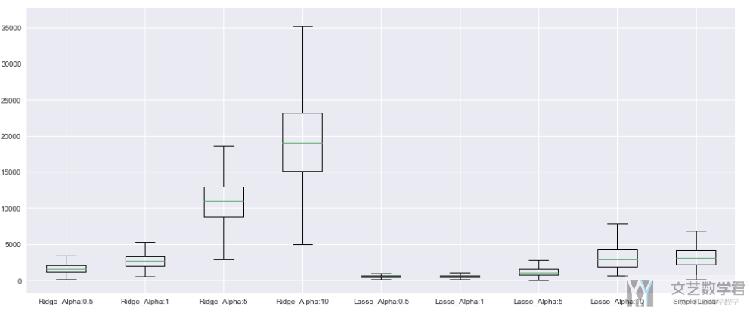
可以看到惩罚系数选择较小的时候模型效果还是不错的,总体的误差不大,且浮动也不大。下面我们将选择出最好的模型绘制出来。
结果的绘制
我们绘制一些延拓的效果。
- # ---------
- # 模型的定义
- # ---------
- model_lasso = Lasso(alpha=0.5,normalize=True)
- model_Ridge = Ridge(alpha=0.5,normalize=True)
- model_linear = LinearRegression()
- # ----------------------------------
- # 模型的训练, 使用整个训练集进行训练
- # ----------------------------------
- x_polynomia7 = Polynomia_7.fit_transform(x.reshape(-1,1))
- model_lasso.fit(x_polynomia7,y)
- model_Ridge.fit(x_polynomia7,y)
- model_linear.fit(x.reshape(-1,1),y)
- # ---------
- # 预测的数据集
- # ---------
- x_test = np.linspace(1, 42, 42)
- y_test = 2*x_test + 0.7*x_test**2 - 20*np.sin(x_test) - 20*np.cos(x_test) + 5*np.random.rand(42)
- x_test_polynomia7 = Polynomia_7.fit_transform(x_test.reshape(-1,1))
- # ----
- # 绘图
- # ----
- plt.style.use('seaborn')
- fig = plt.figure(figsize=(13,7))
- ax = fig.add_subplot(1, 1, 1)
- model1_pre = model_lasso.predict(x_test_polynomia7)
- model2_pre = model_Ridge.predict(x_test_polynomia7)
- model3_pre = model_linear.predict(x_test.reshape(-1,1))
- plt.scatter(x_test,y_test,c='red',label='real') # 画出原图
- plt.plot(x_test,model1_pre,c='green',label='Lasso') # 未使用正则化
- plt.plot(x_test,model2_pre,c='blue',label='Ridge') # l1范数
- plt.plot(x_test,model3_pre,c='darkviolet',label='None') # l2范数
- plt.legend()
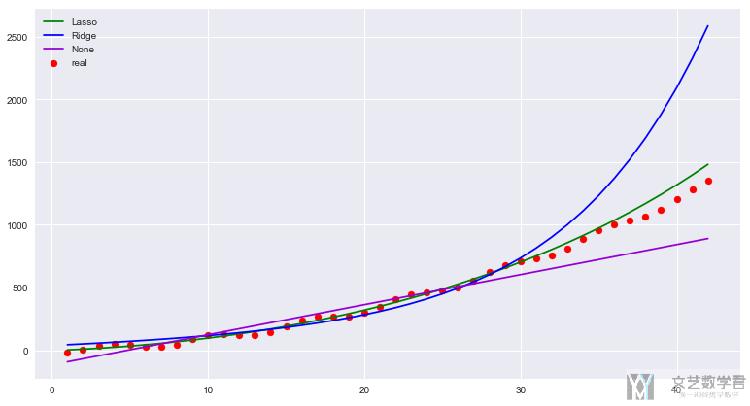
其实总体上来看,LASSO的效果还是可以的。看一下模型最后的系数,可以看到LASSO回归比Ridge回归少一个高次项的系数,所以向后延拓的时候不会高太快。(之前在数据生成的时候只用到了最高是2次)

项目链接
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论