文章目录(Table of Contents)
前言
从这一篇开始会介绍Generative Adversarial Network, 也就是GAN。在这一篇的内容里,我们会介绍最基础的GAN的计算步骤, 这个作为主要内容.
参考资料
我会将所有关于GAN的参考资料都放在这里, 包括后面会讲的WGAN. 还有各种应用的代码, 这里算是一个小的汇总.
GAN的相关介绍
介绍性文章, 介绍为什么GAN比较难训练: GAN — Why it is so hard to train Generative Adversarial Networks!
GAN的简单介绍-1: GAN — A comprehensive review into the gangsters of GANs (Part 1)
GAN的简单介绍-2: GAN — A comprehensive review into the gangsters of GANs (Part 2)
介绍了提升GAN的小技巧(这里有各种损失函数的汇总): GAN — Ways to improve GAN performance
这里介绍了GAN的一些好玩的应用, 和这些应用的原理介绍: GAN — Some cool applications of GANs.
GAN的一些理论
关于GAN中原始的loss不好的证明(数据不重合时, 不管距离远近, 都是log2): GAN:两者分布不重合JS散度为log2的数学证明
应用
使用Pytorch实现CycleGAN的例子(这个最终做出来的效果很好): Image-to-Image Translation in PyTorch
使用Pytorch实现CycleGAN, 这个例子的代码比较简单(容易理解的一个版本): A clean and readable Pytorch implementation of CycleGAN
Pytorch生成动漫人物头像(这里包括数据集的介绍): A simple PyTorch Implementation of Generative Adversarial Networks, focusing on anime face drawing.
GAN的计算步骤
这一部分会介绍一下GAN的计算步骤,整体的结构如下图所示:
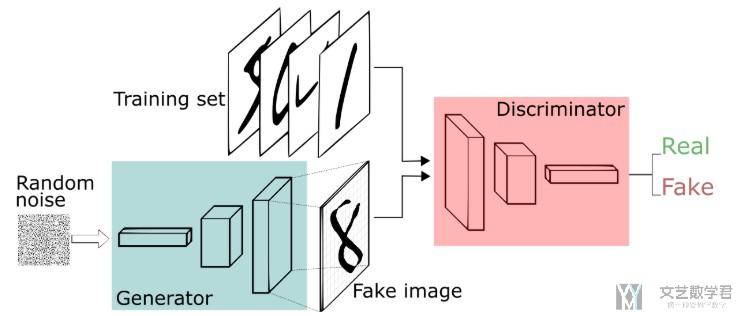
图片来源: A Beginner's Guide to Generative Adversarial Networks (GANs)
粗略的查看步骤
- 初始化generator(生成器)和discriminator(判别器)
- 每一个iteration中, 进行如下的操作
- 固定generator(生成器), 训练discriminator(判别器)
- 训练方式: 我们使用training set和generator(生成器)产生的数据作为训练数据. 告诉discriminator(判别器)对于training set中数据为真, 对于generator(生成器)产生的数据为假, 于是discriminator(判别器)训练为一个二分类器, 用来判断数据是generator(生成器)生成的还是真实的数据.
- 固定discriminator(判别器), 训练generator(生成器)
- 训练方式: 我们使用generator(生成器)来生成图片, 告诉discriminator(判别器)这些图片是真, 反向传播, 从而来对generator(生成器)进行训练.
详细的算法
上面是我们使用文字进行了说明, 下面结合符号, 写得更加完善一些. 但是基础的思想就是上面文字叙述的部分. 内容来自: Machine Learning and having it deep and structured (2018,Spring)
- 0). 现有生成器G和判别器D, 两者都进行参数的初始化
- 1). 从dataset中随机抽取m个数据, {x1, x2, x3, ..., xm}, 这是用来训练discriminator的.
- 2). 从random noise中随机抽取m个数据, {z1, z2, z3, ..., zm}, 这是输入generator的.
- 3). 通过计算G(z_i)来产生图片, 这时产生了如下数据
- 4). 接下来就是更新discriminator, 我们使用如下的方式进行更新.
- 4.1). 简单解释一下下面的式子: 式子的左侧log(D(xi))表示的计算一张真实图片经过D(分类器)的得分, 然后对m张图片求和取平均, 我们希望左侧越大越好, 也就是真实图片分类器结果出来接近1(D(x)的取值范围是0-1, 所以log(D)的取值范围是<0);
- 4.2). 式子的右侧log(1-D(xi))表示假的图片的得分, 然后对m张图片求和取平均, 我们希望假的图片经过分类器的得分D(xi)越接近0越好, 此时1-D就接近1.
- 4.3). 所以总的来说, 我们希望下式中的V越大越好, 下面式子V最大能取到0. 也就是说: real的数据分类器结果是1,fake的数据分类器结果是0.
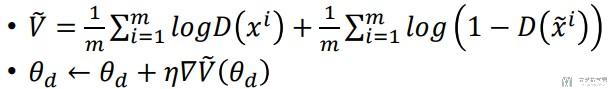
- 5). 接着从random noise中再随机抽取m个数据, {z1, z2, z3, ..., zm}
- 6). 接着对generator进行更新
- 6.1). 简单解释一下下面的式子. G(zi)表示生成器生成的图片
- 6.2). D(G(zi))表示分类器对生成器生成的图片的打分.
- 6.3). 对于下面的式子来说, 我们希望V的值越大越好, 也就是使得生成器生成的数据判别器判别是真的, 无法分辨出是生成器生成的, real的分类器结果是接近1的.
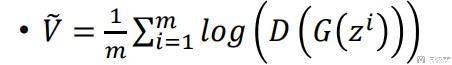
上面1,2,3,4是对discriminator进行训练, 后面5,6是对generator进行训练.
注意: 对于上面的两个损失函数, 是和BCELoss是一样的含义, 其损失函数如下所示.
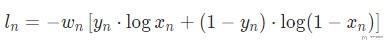
y实际的取值就是0或是1, 当y取0和1的时候, 进行化简可以化简为上面的式子. 上面是求v的最大值, 这里由于BCELoss有负号, 于是转换为求最小值的问题.
一些问题
- generator中初始的随机数, 使用不同的分布, 会对结果有什么影响
- 为什么generator使用tanh来作为激活函数
- 为什么discriminator使用sigmoid作为激活函数: 只需要确保输出值的范围是0-1即可.
- 如何判断模型训练的好坏, 是否可以根据D(G(z))的值, 也就是对生成器生成的样本分类器分类的准确率作为标准, 如果模型训练的好, 是否D(G(z))能趋近于1.
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论