文章目录(Table of Contents)
简介
这一篇做一下GAN的简单实验,主要参考资料如下: Generative Adversarial Networks (GANs) in 50 lines of code (PyTorch),这是GAN的第一个实验.
这一篇我们会使用GAN来生成服从高斯分布的数据,我会稍微对上面的代码进行修改.
完整的代码链接: GAN实验代码链接
实验的简单步骤
首先我们介绍一下这个实验的简单步骤。
- 我们的training dataset是服从mean=4, std=1.25的高斯分布, 这是用来训练D的真实的数据.
- 我们取50维的均匀分布, 用作G的输入, 用来生成虚假的高斯分布的数据.
- 最后, 我们会训练分类器D和生成器G.
实验过程
实验准备
我们首先做一下实验的准备工作, 首先导入库.
- import numpy as np
- from matplotlib import pyplot as plt
- import torch
- import torch.nn as nn
- import torch.optim as optim
- from torch.autograd import Variable
- from torch.optim import lr_scheduler
接着我们定义一个处理数据的函数, 这个函数输入时一组数据, 输出是这组数据的均值, 方差, 偏度和峰度, 我们用这四个数据来判断这组数据是否是服从高斯分布的数据.
- def get_moments(ds):
- """
- - Return the first 4 moments of the data provided
- - 返回一个数据的四个指标, 分别是均值, 方差, 偏度, 峰读
- - 我们希望通过这四个指标, 来判断我们生成的数据是否是需要的数据
- """
- finals = []
- for d in ds:
- mean = torch.mean(d) # d的均值
- diffs = d - mean
- var = torch.mean(torch.pow(diffs, 2.0))
- std = torch.pow(var, 0.5) # d的方差
- zscores = diffs / (std+0.001) # 对原始数据 zscores = (d-mean)/std
- skews = torch.mean(torch.pow(zscores, 3.0)) # 峰度
- kurtoses = torch.mean(torch.pow(zscores, 4.0)) - 3.0 # excess kurtosis, should be 0 for Gaussian
- final = torch.cat((mean.reshape(1,), std.reshape(1,), skews.reshape(1,), kurtoses.reshape(1,)))
- # 这里返回的是高斯分布的四个特征
- finals.append(final)
- return torch.stack(finals)
训练样本的准备
首先是用来生成服从高斯分布的样本, 即training set中的数据. 这个数据是生成真实的数据, 被用于模仿。
- def get_distribution_sampler(mu, sigma, batchSize, FeatureNum):
- """
- Generate Target Data, Gaussian
- Input
- - mu: 均值
- - sugma: 方差
- Output
- """
- return Variable(torch.Tensor(np.random.normal(mu, sigma, (batchSize, FeatureNum))))
我们生成500个数据样本进行绘图测试,代码如下
- data_mean = 4
- data_stddev = 1.25
- batch_size = 1
- featureNum = 500
- d_real_data = get_distribution_sampler(data_mean, data_stddev, batch_size, featureNum)
最终的分布如下图所示.
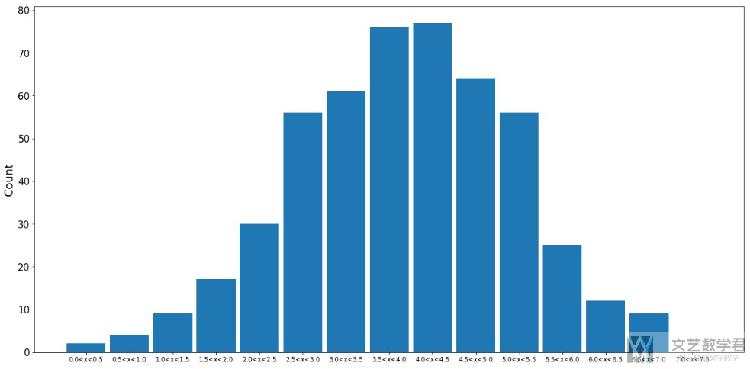
这是输入生成器G中的数据, 用来生成服从均匀分布的数据.
- def get_generator_input_sampler(m, n):
- """
- Uniform-dist data into generator, _NOT_ Gaussian
- Input
- - m: 表示batchsize
- - n: 表示feature count
- Output
- - 返回的是生成数据的分布
- """
- return torch.rand(m, n)
定义分类器和生成器
下面我们定义生成器和分类器。首先是定义生成器,下面是简单的介绍.
- generator是一个普通的前向传播网络
- generator使用的是tanh激活函数
- generator输入是均值分布(来自I的数据)
- generator的任务是输出模仿真实的高斯分布的数据
- class Generator(nn.Module):
- def __init__(self, input_size, hidden_size, output_size, f):
- super(Generator, self).__init__()
- self.map1 = nn.Linear(input_size, hidden_size)
- self.map2 = nn.Linear(hidden_size, hidden_size)
- self.map3 = nn.Linear(hidden_size, output_size)
- self.relu = nn.ReLU()
- self.f = f # 激活函数
- def forward(self, x):
- x = self.map1(x)
- x = self.relu(x)
- x = self.map2(x)
- x = self.relu(x)
- x = self.map3(x)
- return x
接着定义分类器, 下面是对分类器的简单介绍
- discriminator和generator一样, 也是简单的前向传播网络
- discriminator使用的是sigmoid函数
- discriminator使用真实数据和G产生的数据
- 最后的label是0与1, 从真实的高斯分布中的数据label是1, 从G中产生的数据label是0
- class Discriminator(nn.Module):
- def __init__(self, input_size, hidden_size, output_size, f):
- super(Discriminator, self).__init__()
- self.map1 = nn.Linear(input_size, hidden_size)
- self.map2 = nn.Linear(hidden_size, hidden_size)
- self.map3 = nn.Linear(hidden_size, output_size)
- self.relu = nn.ReLU()
- self.f = f
- def forward(self, x):
- x = self.relu(self.map1(x))
- x = self.relu(self.map2(x))
- x = self.f(self.map3(x))# 最后生成的是概率
- return x
模型开始训练
首先说明一下训练的简单步骤:
- 首先训练D, 我们使用real data vs. fake data, with accurate labels
- 接着我们训练G来使得其生成的数据无法被D正确分辨(这时候fix住D的参数, 使得G产生数据, 使得D预测的label是1)
- 接着重复上面的两个操作
对于代码的简单说明(这个很重要)
- 对于分类器来说, 输入维度是4, 表示一组数据的均值, 方差, 偏度和峰度, 输出是一维, 表示判断是真实数据或不是真实数据
- 对于生成器来说, 输入维度是50, 表示我们每次随机输入一个50维的均匀分布的数据, 输出是500, 表示我们希望产生500个数, 这500个数服从mean=4, std=1.25的高斯分布。
- d_input_size = 4
- d_hidden_size = 10
- d_output_size = 1
- discriminator_activation_function = torch.sigmoid
- g_input_size = 50
- g_output_size = 200
- g_output_size = 500
- generator_activation_function = torch.tanh
- featureNum = g_output_size # 一组样本有500个服从正太分布的数据
- minibatch_size = 10 # batch_size的大小
- num_epochs = 2001
- d_steps = 20 # discriminator的训练轮数
- g_steps = 20 # generator的训练轮数
- # ----------
- # 初始化网络
- # ----------
- D = Discriminator(input_size=d_input_size,
- hidden_size=d_hidden_size,
- output_size=d_output_size,
- f=discriminator_activation_function)
- G = Generator(input_size=g_input_size,
- hidden_size=g_hidden_size,
- output_size=g_output_size,
- f=generator_activation_function)
- # ----------------------
- # 初始化优化器和损失函数
- # ----------------------
- d_learning_rate = 0.0001
- g_learning_rate = 0.0001
- criterion = nn.BCELoss() # Binary cross entropy: http://pytorch.org/docs/nn.html#bceloss
- d_optimizer = optim.Adam(D.parameters(), lr=d_learning_rate)
- g_optimizer = optim.Adam(G.parameters(), lr=g_learning_rate)
- d_exp_lr_scheduler = optim.lr_scheduler.CosineAnnealingLR(d_optimizer, T_max = d_steps*5, eta_min=0.00001)
- g_exp_lr_scheduler = optim.lr_scheduler.CosineAnnealingLR(g_optimizer, T_max = g_steps*5, eta_min=0.00001)
- G_mean = [] # 生成器生成的数据的均值
- G_std = [] # 生成器生成的数据的方差
- for epoch in range(num_epochs):
- # -------------------
- # Train the Detective
- # -------------------
- for d_index in range(d_steps):
- # Train D on real+fake
- d_exp_lr_scheduler.step()
- D.zero_grad()
- # Train D on real, 这里的label是1
- d_real_data = get_distribution_sampler(data_mean, data_stddev, minibatch_size, featureNum) # 真实的样本
- d_real_decision = D(get_moments(d_real_data)) # 求出数据的四个重要特征
- d_real_error = criterion(d_real_decision, Variable(torch.ones([minibatch_size, 1]))) # 计算error
- d_real_error.backward() # 进行反向传播
- # Train D on fake, 这里的label是0
- d_gen_input = get_generator_input_sampler(minibatch_size, g_input_size)
- d_fake_data = G(d_gen_input)
- d_fake_decision = D(get_moments(d_fake_data))
- d_fake_error = criterion(d_fake_decision, Variable(torch.zeros([minibatch_size, 1])))
- d_fake_error.backward()
- # Optimizer
- d_optimizer.step()
- # -------------------
- # Train the Generator
- # -------------------
- for g_index in range(g_steps):
- # Train G on D's response(使得G生成的x让D判断为1)
- g_exp_lr_scheduler.step()
- G.zero_grad()
- gen_input = get_generator_input_sampler(minibatch_size, g_input_size)
- g_fake_data = G(gen_input) # 使得generator生成样本
- dg_fake_decision = D(get_moments(g_fake_data)) # D来做的判断
- g_error = criterion(dg_fake_decision, Variable(torch.ones([minibatch_size, 1])))
- G_mean.append(g_fake_data.mean().item())
- G_std.append(g_fake_data.std().item())
- g_error.backward()
- g_optimizer.step()
- if epoch%10==0:
- print("Epoch: {}, G data's Mean: {}, G data's Std: {}".format(epoch, G_mean[-1], G_std[-1]))
- print("Epoch: {}, Real data's Mean: {}, Real data's Std: {}".format(epoch, d_real_data.mean().item(), d_real_data.std().item()))
- print('-'*10)
我们就使用上面的代码进行训练。
结果分析
我们绘制出生成器产生的服从正太分布的数据.
- # ----------------------
- # 计算每个范围的数据个数
- # ----------------------
- binRange = np.arange(0,8,0.5)
- hist1,_ = np.histogram(g_fake_data.squeeze().detach().numpy(), bins=binRange)
- # --------
- # 绘制图像
- # --------
- fig, ax1 = plt.subplots()
- fig.set_size_inches(20, 10)
- plt.set_cmap('RdBu')
- x = np.arange(len(binRange)-1)
- w=0.3
- # 绘制多个bar在同一个图中, 这里需要控制width
- plt.bar(x, hist1, width=w*3, align='center')
- # 设置坐标轴的标签
- ax1.yaxis.set_tick_params(labelsize=15) # 设置y轴的字体的大小
- ax1.set_xticks(x) # 设置xticks出现的位置
- # 创建xticks
- xticksName = []
- for i in range(len(binRange)-1):
- xticksName = xticksName + ['{}<x<{}'.format(str(np.round(binRange[i],1)), str(np.round(binRange[i+1],1)))]
- ax1.set_xticklabels(xticksName)
- # 设置坐标轴名称
- ax1.set_ylabel("Count", fontsize='xx-large')
- plt.show()
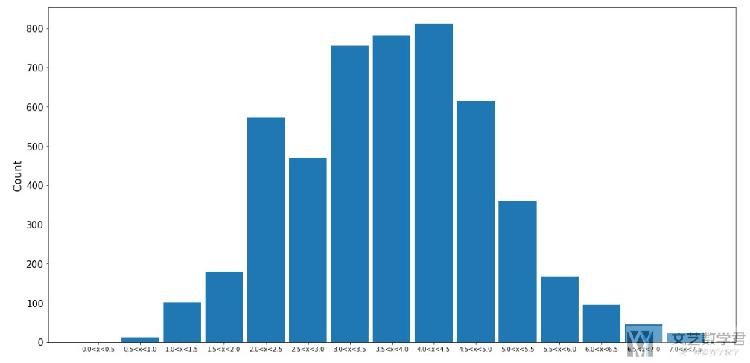
最终的实验结果如下图所示,可以看到基本上还是挺像的。
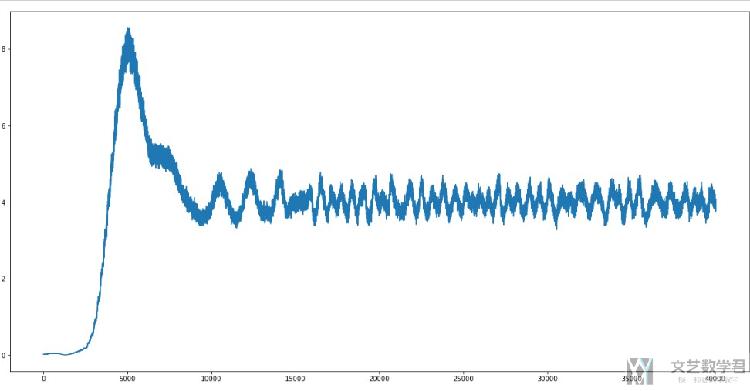
我们绘制出均值和方差的变化情况。均值的变化如下, 可以看到最后会在4左右徘徊,是符合正确数据的均值的。
同样,方差最后也是会趋于1.25,如下图所示。
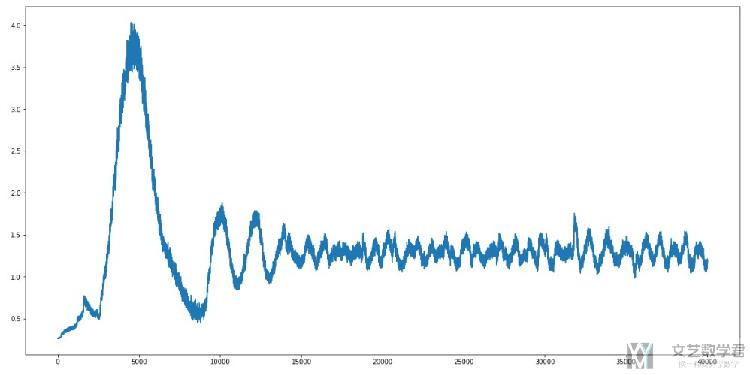
所以,总体来说,生成器生成的结果还是不错的.
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论