文章目录(Table of Contents)
简介
重要性抽样(importance sampling)是一种近似的抽样方法, 他通过一些小的数学上的变化, 使得可以对一些不好抽样的分布进行抽样和估计. 这个会在强化学习中的off-policy的方法中用到, 从一个策略进行抽样, 更新另外一个策略(关于强化学习的内容, 之后专门来讲).
在这篇文章中, 我们就着重于importance sampling, 我们将从下面的几个点进行书写:
- 什么是importance sampling (什么是重要性抽样), 背景知识和数学转换;
- importance sampling的例子, 分析方差;
参考资料
- 这一篇的内容基本都是从这里来的: Importance Sampling Introduction
- 关于这一篇所有试验内容, 可以参考, 重要性采样试验 (importance sampling)
Importance Sampling简单介绍
背景介绍
假设现在我们要计算f(x)的期望, 其中x~p(x), 那么E[f(x)]的计算如下所示:
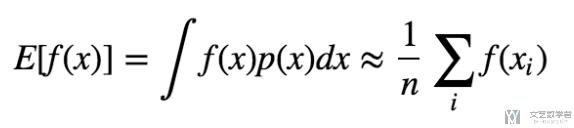
我们可以使用蒙特卡洛采用的方法, 首先从分布p(x)中抽样得到x, 接着将所有的f(x)求平均, 来近似f(x), x~p(x)的期望.
存在的问题与解决方法
上面的采用方法很简单, 但可能存在一个问题, 如果我们无法从分布p(x)中抽样, 或者从中抽样的成本很高, 那么我们还可以求E[f(x)]吗.
答案是可以的, 我们可以从一个简单的分布q(x)中进行抽样得到x, 接着乘上一个系数, 就可以来近似计算f(x), x~p(x)的期望.
我们可以通过下面一个简单的数学式子来是的从分布q(x)中进行抽样的数据来估计f(x), x~p(x)的期望.
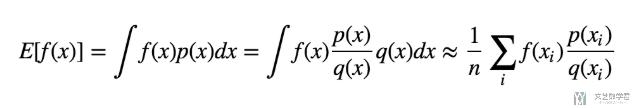
上式中最后的连加, 其中, x~q(x), 同时q(x)!=0. 也就是在分布q(x)中进行抽样, 接着乘上p(x)/q(x)来修正从不同分布采用的概率.
这样就完成了从分布q(x)中进行抽样, 来估计E[f(x)],x~p(x).
估计的方差
上面我们讲完了如何从分布q(x)中进行抽样, 来估计E[f(x)],x~p(x). 这里我们来说明一下估计的方差. 因为方差的计算公式是Var(x)=E[x^2]-E[x], 这里的x=f(x)*p(x)/q(x), 所以一旦p(x)/q(x)比较大(也就是两个分布的差异比较大), 那么方差也是会比较大.
当p(x)和q(x)比较接近的时候, 这个时候方差就会比较小. 我们下面来看一个例子.
Importance Sampling的例子
这一部分所有的代码如链接, 重要性采样试验 (importance sampling).
下面就放一些比较重要的部分. 首先我们来定义函数f(x). 定义的函数如下:
- # 定义f(x)
- def f_x(x):
- return 1/(1 + np.exp(-x))
该函数的曲线如下所示:
实验一---当p(x)与q(x)比较接近
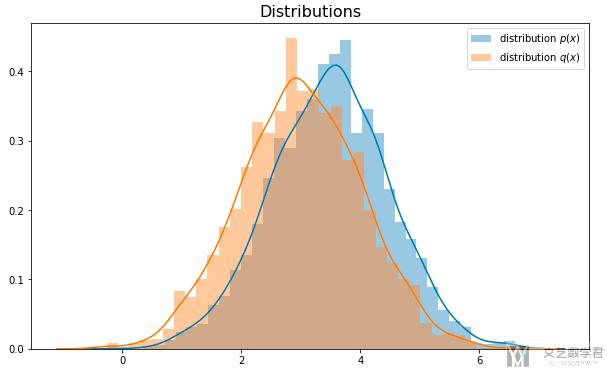
首先进行第一个实验, p(x)与q(x)比较接近. 下面我们来定义分布p(x)和q(x). 这两个分布的均值比较接近. 我们从每一个分布中抽样3000个数据.
- # p(x)
- mu_target = 3.5
- sigma_target = 1
- p_x = [np.random.normal(mu_target, sigma_target) for _ in range(3000)]
- # q(x)
- mu_appro = 3
- sigma_appro = 1
- q_x = [np.random.normal(mu_appro, sigma_appro) for _ in range(3000)]
接着我们绘制出分布图.
- fig = plt.figure(figsize=(10,6))
- ax = fig.add_subplot(1,1,1)
- # 画出两个分布的图像
- sns.distplot(p_x, label="distribution $p(x)$")
- sns.distplot(q_x, label="distribution $q(x)$")
- plt.title("Distributions", size=16)
- plt.legend()
最终这两个分布如下所示:
接着我们计算E[f(x)],x~p(x). 首先我们看一下当x~p(x)的结果.
- # 当x~p(x)时, E[f(x)]
- np.mean([f_x(i) for i in p_x])
最终的的均值为0.9552. 接着来看一下当x~q(x)的情况下的计算, E[f(x)] = mean(p(x)/q(x) * f(x)).
- # 当x~q(x), E[f(x)] = mean(p(x)/q(x)*f(x))
- p_pdf = stats.norm(mu_target, sigma_target)
- q_pdf = stats.norm(mu_appro, sigma_appro)
- print(np.mean([p_pdf.pdf(i)/q_pdf.pdf(i) * f_x(i) for i in q_x]), np.var([p_pdf.pdf(i)/q_pdf.pdf(i) * f_x(i) for i in q_x]))
最终的结果为mean, 0.9657; var,0.32068.
实验二---当p(x)与q(x)相差比较远
总体的代码和上面的类似, 这两个分布如下图所示:
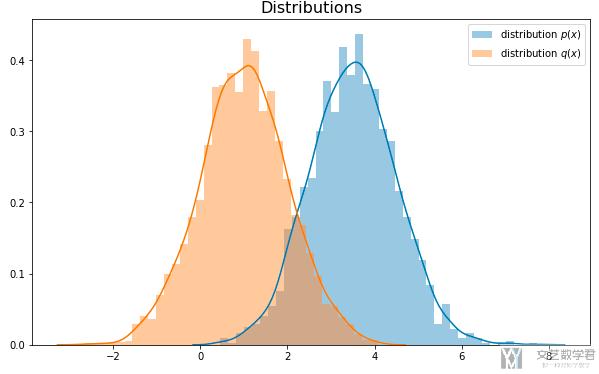
因为p(x)没有变, 所以如果计算E[f(x)],x~p(x), 那么均值还是约为0.9552. 接着我们来看x~q(x)的情况, 当p(x)和q(x)相差比较大的时候, 结果会怎么样.
- 如果采样数量是3000, 最终的结果为, mean, 0.8034; var,29.6346.
- 如果采样数量是5000, 最终的结果为, mean, 0.76752; var,24.0317.
- 如果采样数量是10000, 最终的结果为, mean, 0.87405; var,69.76793.
- 如果采样数量是100000, 最终的结果为, mean, 0.86416 var,79.40022.
可以看到, 当两个分布差的比较多的时候, 我们需要更多的采样, 来获得mean较准确的估计, 但是同时也可以看到估计的方差比较大.
这个方差的来源为p(x)/q(x), 因为两个分布相差比较大, 所以p(x)/q(x)值就会比较大, 最终会导致方差比较大.
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












2020年7月2日 下午2:10 1F
plt.legend()
plt.show() 需要加上
2020年7月4日 下午8:29 B1
@ fatalfeel 是的, 上面链接有notbook, 可以直接进行查看.