文章目录(Table of Contents)
简介
这一篇是参考自Pytorch官网的教程, REINFORCEMENT LEARNING (DQN) TUTORIAL. 我对其中做了一些简化. 在原实验中是使用了CartPole-v0的环境, 但是因为在线上环境Google Colab里面无法渲染图像, 所以我选择使用Cliff Walking PlayGround.
这一篇主要概述一下使用Pytorch实现Deep Q-Learning的过程. 里面暂时不会涉及原理的介绍, 只会有DQN的整体算法流程.
参考资料
- 关于本实验的代码, 见Github仓库, 06_Deep_Q_Learning_Pytorch_CliffWalking.ipynb
- 关于环境的介绍, Reinforcement Learning(强化学习)-Cliff Walking Playground环境介绍.
DQN的整体步骤
在讲具体的实现之前, 我们先来简单聊一下DQN的训练步骤. 在DQN中会有两个网络, 分别叫做Policy Network和Target Network. 这两个network的结构是一样的, 只有网络的参数不同.
- Policy Network
- Policy Network会产生action
- Policy Network会在每一轮进行更新.
- Target Network
- 每过N轮, Target Network会直接拷贝Policy Network的参数.
下面是DQN的算法流程.
- 用Policy Network生成每一个action的概率, 接着根据epsilon-greedy策略选取一个action.
- 执行action, 将得到的{state, action, next_state, reward}存入memory中.
- 从memory中选取一个mini-batch进行训练.
- 按照下面的式子计算Loss, 并进行Policy Network的参数更新. (每N轮再更新Target Network)
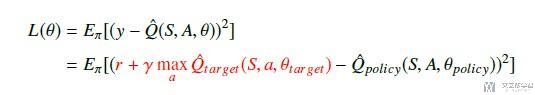
Pytorch实现DQN
环境介绍
在这次实验中, 我们使用的是Cliff Walking PlayGround, 环境如下所示:
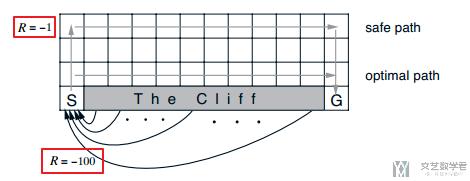
一共有48个状态, 每次环境返回的是state的编号, 也就是现在在哪个格点上面. 为了作为网络的输入, 我们将state转换为one-hot编码. 共48维. 来作为网络的输入. 下面是state转one-hot向量的函数.
- def get_screen(state):
- """这里我们就用state来作为例子, 不直接使用截图了
- """
- y_state = torch.Tensor([[state]]).long()
- y_onehot = torch.FloatTensor(1, 48) # 产生位置
- # In your for loop
- y_onehot.zero_() # 全部使用0进行填充
- y_onehot.scatter_(1, y_state, 1) # 返回one-hot
- return y_onehot
我们看一下例子, 假设现在在state=1上面, 查看返回的输出. 可以看到第2位上面是1, 其他位置是0.
- print(get_screen(1).shape)
- """
- torch.Size([1, 48])
- """
- get_screen(1)
- """
- tensor([[0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
- 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
- 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]])
- """
Replay Memory的定义
在DQN中, 会有一个memory来存储之间环境生成的值, 可以被用来反复使用. 这里会记录每一次action之后的, {state, action, next_state, reward}.
通过在memory里面随机采样进行训练, 可以改善DQN训练的稳定性. 我们首先定义一个namedtuple.
- Transition = namedtuple('Transition', ('state', 'action', 'next_state', 'reward'))
- Transition(24,1,25,1)
- """
- Transition(state=24, action=1, next_state=25, reward=1)
- """
接着定义ReplayMemory的类, 主要实现两个函数:
- 向memory里进行添加{state, action, next_state, reward};
- 从memory中进行随机采样;
- class ReplayMemory(object):
- def __init__(self, capacity):
- self.capacity = capacity # 允许存储多少状态
- self.memory = [] # 存入的状态
- self.position = 0 # memory的list的下标
- def push(self, *args):
- """Saves a transition."""
- if len(self.memory) < self.capacity:
- self.memory.append(None)
- self.memory[self.position] = Transition(*args)
- self.position = (self.position + 1) % self.capacity
- def sample(self, batch_size):
- return random.sample(self.memory, batch_size)
- def __len__(self):
- return len(self.memory)
定义Q Network
我们在这里使用全连接网络, 输入是48, 输出是4(对应四个action, 分别是上, 下, 左, 右). 网络的整体结构是48->24->12->4.
- class DQN(nn.Module):
- def __init__(self):
- super(DQN, self).__init__()
- self.l1 = nn.Linear(48, 24)
- self.l2 = nn.Linear(24, 12)
- self.l3 = nn.Linear(12, 4)
- def forward(self, x):
- x = F.relu(self.l1(x))
- x = F.relu(self.l2(x))
- x = self.l3(x)
- return x # Returns tensor([[left0exp,right0exp,down0exp,down0exp]...]).
我们对上面定义的网络做一下测试.
- model = DQN()
- model(get_screen(1)) # 返回的4个action的值的大小
- """
- tensor([[-0.0524, 0.0964, 0.1775, 0.1297]], grad_fn=<AddmmBackward>)
- """
动作选择函数
接着我们定义一个动作选择函数. 我们会根据Policy Network生成的动作的概率进行选择. 同时我们会希望一开始的时候探索率高一些, 之后逐渐降低. 下面是实现的是epsilon-greedy策略.
- def select_action(state, model, nA):
- """这里是包含探索的
- """
- global steps_done
- EPS_START = 0.9 # 初始的探索率
- EPS_END = 0.05 # 最终的探索了
- EPS_DECAY = 300 #进行200步骤, 到最终的探索率
- sample = random.random()
- eps_threshold = EPS_END + (EPS_START - EPS_END) * math.exp(-1. * steps_done / EPS_DECAY) # 计算实时探索率
- steps_done += 1
- if sample > eps_threshold:
- with torch.no_grad():
- return model(state).max(1)[1].view(1, 1) # 返回的最大动作的indice
- else:
- return torch.tensor([[random.randrange(nA)]], device=device, dtype=torch.long) # 随机选一个动作
定义训练函数
最后我们就定义总体训练的函数. 总的训练步骤就和我们上面说的是一样的. 我们做了一点点的修改, 将最后到达终点的reward修改成了100.
- def QNetwork(env, num_episodes, policy_net, target_net, memory, discount_factor=1.0):
- TARGET_UPDATE = 10 # target网络的更新论数
- BATCH_SIZE = 256
- # 环境中所有动作的数量
- nA = env.action_space.n # 环境的动作个数
- # 记录reward和总长度的变化
- stats = plotting.EpisodeStats(
- episode_lengths=np.zeros(num_episodes+1),
- episode_rewards=np.zeros(num_episodes+1))
- for i_episode in range(1, num_episodes+1):
- # 开始一轮游戏
- state = env.reset()
- state=get_screen(state) # 将state转换为oen-hot的tensor, 用作网络的输入.
- action = select_action(state, model=policy_net, nA=nA)
- for t in itertools.count():
- next_state, reward, done, _ = env.step(action.detach().item()) # 执行action, 返回reward和下一步的状态
- if done:
- reward = 100
- reward = torch.tensor([reward], device=device) # 转为tensor
- next_state_tensor = get_screen(next_state) # 转为tensor
- next_action = select_action(state=next_state_tensor, model=policy_net, nA=nA) # 选择下一步的动作
- # 计算统计数据(带有探索的策略)
- stats.episode_rewards[i_episode] += reward # 计算累计奖励
- stats.episode_lengths[i_episode] = t # 查看每一轮的时间
- if done:
- next_state_tensor = None
- # 这里不能直接break, 需要进行push和状态更新
- else:
- pass
- # 将信息存入memory
- memory.push(state, action, next_state_tensor, reward)
- # 状态更新
- state = next_state_tensor
- action = next_action
- # 模型更新
- if len(memory) > BATCH_SIZE: # 首先确保memory里足够sample
- transitions = memory.sample(BATCH_SIZE)
- batch = Transition(*zip(*transitions)) # 转换为如下效果, Transition(state=(5, 1), action=(6, 2), next_state=(7, 3), reward=(8, 4))
- non_final_mask = torch.tensor(tuple(map(lambda s: s is not None, batch.next_state)), device=device, dtype=torch.bool) # 确认哪些不是终点
- non_final_next_states = torch.cat([s for s in batch.next_state if s is not None]) # 将不是None的next_state连起来
- # 下面是将几个变量都转换为batch的类型
- state_batch = torch.cat(batch.state)
- action_batch = torch.cat(batch.action)
- reward_batch = torch.cat(batch.reward)
- state_action_values = policy_net(state_batch).gather(1, action_batch) # Q(s,a)的值
- next_state_values = torch.zeros(BATCH_SIZE, device=device)
- next_state_values[non_final_mask] = target_net(non_final_next_states).max(1)[0].detach()
- # Compute the expected Q values
- expected_state_action_values = (next_state_values * discount_factor) + reward_batch
- # Compute Huber loss
- loss = F.smooth_l1_loss(state_action_values, expected_state_action_values.unsqueeze(1))
- # Optimize the model
- optimizer.zero_grad()
- loss.backward()
- # for param in policy_net.parameters():
- # param.grad.data.clamp_(-1, 1)
- optimizer.step()
- if done:
- break
- if t > 500:
- break
- if i_episode % TARGET_UPDATE == 0:
- # target net更新参数
- target_net.load_state_dict(policy_net.state_dict())
- if i_episode % 50 == 0:
- print("\rEpisode {}/{}. | ".format(i_episode, num_episodes), end="")
- return stats
开始训练
最后我们训练2000个episode, 看一下最终的结果.
- env = CliffWalkingEnv() # 初始化环境
- policy_net = DQN().to(device)
- target_net = DQN().to(device)
- target_net.load_state_dict(policy_net.state_dict())
- target_net.eval()
- optimizer = optim.Adam(policy_net.parameters(), 0.002)
- memory = ReplayMemory(500)
- steps_done = 0
- stats = QNetwork(env, 2000, policy_net, target_net, memory, discount_factor=0.9)
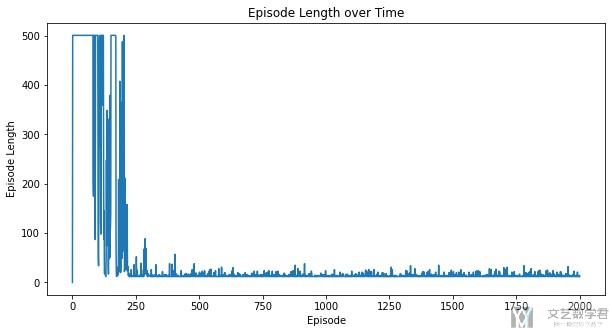
最终关于每一个episode需要走的步数变化如下所示, 大概在250轮之后模型收敛, 可以找到最优的解.
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论