文章目录(Table of Contents)
简介
这一部分是关于PyTorch的一些使用记录,自己经常使用的一些功能会记录在这里,方便自己的查找与使用。(建议直接使用Ctrl+F来进行查找)
Pytorch中的variable, tensor与numpy相互转化的方法
- import torch
- from torch.autograd import Variable
- import numpy as np
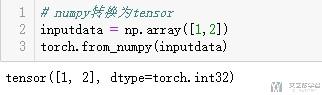
numpy转tensor
- # numpy转换为tensor
- inputdata = np.array([1,2])
- torch.from_numpy(inputdata)
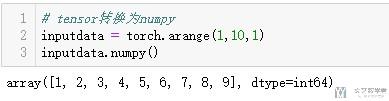
tensor转numpy
- # tensor转换为numpy
- inputdata = torch.arange(1,10,1)
- inputdata.numpy()
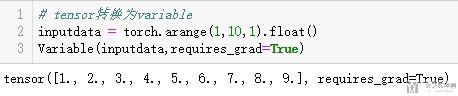
tensor转换为variable
- # tensor转换为variable
- inputdata = torch.arange(1,10,1).float()
- Variable(inputdata,requires_grad=True)
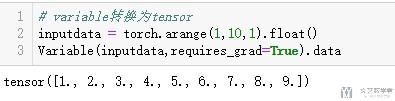
variable转换为tensor
- # variable转换为tensor
- inputdata = torch.arange(1,10,1).float()
- Variable(inputdata,requires_grad=True).data
Pytorch中tensor类型转换
直接在后面增加变量类型即可,下面简单举例。
- torch.ones(2,2).long()

Pytorch中分类损失函数--CrossEntropyLoss()
一次在使用CrossEntropyLoss()的时候,出现了如下的报错 :
RuntimeError: multi-target not supported at /opt/conda/condabld/pytorch_1518243271935/work/torch/lib/THNN/generic/ClassNLLCriterion.c:22
发现是target的dimension的问题。关于target的dimension, 不应该是(batchSize x 1),这样二维的。而应该是(batchSize, ),我们可以通过labels.squeeze_()来解决这个问题.
参考资料 : pytorch error: multi-target not supported in CrossEntropyLoss()
Pytorch中交换顺序--permute
这个是RNN中经常会有被使用到,因为RNN的输入的顺序需要是n_step × batch_size × n_inputs, 一般情况下我们的顺序是batch_size × n_step × n_inputs, 这个时候就需要进行顺序的交换了。
我们下面看一个简单的例子。测试数据如下:
- x_test = torch.from_numpy(np.array([[[1,2,1,2],[5,6,5,6],[8,9,8,9]],[[1,2,1,2],[5,6,5,6],[8,9,8,9]]]))
- x_test.size()
- # torch.Size([2, 3, 4])
- x_test
- """
- tensor([[[1, 2, 1, 2],
- [5, 6, 5, 6],
- [8, 9, 8, 9]],
- [[1, 2, 1, 2],
- [5, 6, 5, 6],
- [8, 9, 8, 9]]], dtype=torch.int32)
- """
我们交换顺序。
- # 我们交换一下顺序
- x_permute = x_test.permute(1,0,2)
- x_permute.size()
- # torch.Size([3, 2, 4])
- # 在将其交换回去
- x_permute = x_permute.permute(1,0,2)
- x_permute.size()
- # torch.Size([2, 3, 4])
- # 看一下最终的结果和一开始是否相同
- x_permute
- """
- tensor([[[1, 2, 1, 2],
- [5, 6, 5, 6],
- [8, 9, 8, 9]],
- [[1, 2, 1, 2],
- [5, 6, 5, 6],
- [8, 9, 8, 9]]], dtype=torch.int32)
- """
查看最终打印的结果,是和交换之前是一样的。
模型的保存
整个模型的保存
- # 保存和加载整个模型
- torch.save(model_object, 'model.pkl')
- model = torch.load('model.pkl')
保存模型参数
- # 仅保存和加载模型参数
- torch.save(model_object.state_dict(), 'params.pkl')
- model_object.load_state_dict(torch.load('params.pkl'))
保存checkpoint注意点
除了上面两种最基本的模型保存的情况, 有的时候我们需要保存更加详细的信息, 例如保存这个模型是在第几个epoch的, 方便我们暂停之后继续模型. 也可以记录当前的loss. 于是我们可以使用下面的方式进行存储.
- torch.save({
- 'epoch': epoch,
- 'model_state_dict': model.state_dict(),
- 'optimizer_state_dict': optimizer.state_dict(),
- 'loss': loss,
- ...
- }, PATH)
当要进行提取的时候, 我们不仅获得模型的参数, 还可以获得epoch等信息, 用于重启训练.
- # 初始化模型和优化器
- model = TheModelClass(*args, **kwargs)
- optimizer = TheOptimizerClass(*args, **kwargs)
- # 载入保存数据
- checkpoint = torch.load(PATH)
- model.load_state_dict(checkpoint['model_state_dict'])
- optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
- epoch = checkpoint['epoch']
- loss = checkpoint['loss']
- model.eval()
- # - or -
- model.train()
关于更多Pytorch save的资料, 可以参考Saving & Loading a General Checkpoint for Inference and/or Resuming Training
实际使用例子
在实际使用的时候, 我自己会首先定义以下的函数.
- # 定义模型保存函数
- def save_checkpoint(state, is_best, check_point=True, filename='checkpoint.pth.tar'):
- """
- Save the training model
- """
- if check_point:
- """对于checkpoint来说, 都要保存
- """
- torch.save(state, filename)
- elif is_best:
- """总的保存最好的一个模型
- """
- torch.save(state, filename)
这个函数的作用是保存一个最好的模型(测试集上结果最好的), 同时保存每一个节点的信息. 下面是在训练过程中的代码, 需要保存在测试集上最好的模型以及每一次checkpoint处的模型.
- for epoch in range(start_epoch, epochs):
- """Training Steps
- """
- # remember best prec@1 and save checkpoint
- is_best = prec1 > best_prec1 # 返回True/False
- best_prec1 = max(prec1, best_prec1) # 记录最好的一次
- # 每save_every步骤保存一次
- if epoch > 0 and (epoch % save_every) == 0:
- save_checkpoint({
- 'epoch': epoch + 1,
- 'state_dict': model.state_dict(),
- 'best_prec1': best_prec1,
- 'optimizer_state_dict': optimizer.state_dict(),
- 'is_best': is_best,
- }, is_best, check_point=True, filename=os.path.join(save_dir, 'checkpoint.th'))
- # 保存在测试集上最优的模型
- save_checkpoint({
- 'epoch': epoch,
- 'state_dict': model.state_dict(),
- 'best_prec1': best_prec1,
- 'is_best': is_best,
- }, is_best, check_point=False, filename=os.path.join(save_dir, 'model.th'))
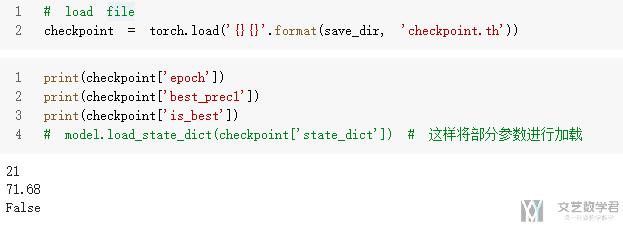
最后载入模型的时候, 我们可以打印一些信息来进行查看.
- # load file
- checkpoint = torch.load('{}{}'.format(save_dir, 'checkpoint.th'))
- # 打印一些信息
- print(checkpoint['epoch'])
- print(checkpoint['best_prec1'])
- print(checkpoint['is_best'])
- # model.load_state_dict(checkpoint['state_dict']) # 这样将部分参数进行加载
可以看一下下面的输出结果的图.
model.eval()与torch.no_grad()的区别
参考链接:model.eval() vs with torch.no_grad()
These two have different goals:
model.eval()will notify all your layers that you are in eval mode, that way, batchnorm or dropout layers will work in eval mode instead of training mode.torch.no_grad()impacts the autograd engine and deactivate it. It will reduce memory usage and speed up computations but you won’t be able to backprop (which you don’t want in an eval script).
所以在test的时候,我们通常会像下面这么书写
- model.eval()
- with torch.no_grad():
- correct = 0
- total = 0
- for data, labels in test_dataset:
- data = data.to(device)
- labels = labels.to(device)
- outputs = model(data)
- _, predicted = torch.max(outputs.data, 1)
- total += labels.size(0)
- correct += (predicted == labels).sum().item()
Tensor张量
view方法修改tensor形状
view方法前后元素总数一致;且新tensor和源tensor共享内存,改变其中一个,另一个也会进行改变。要注意的是:当某一维度为1的时候,会自动计算它的大小
首先是基本用法:

关于共享内存的说明:

squeeze与unsqueeze的使用
作用:从数组的形状中删除单维度条目,即把shape中为1的维度去掉
场景:在机器学习和深度学习中,通常算法的结果是可以表示向量的数组(即包含两对或以上的方括号形式[[]]),如果直接利用这个数组进行画图可能显示界面为空。我们可以利用squeeze函数将表示向量的数组转换为秩为1的数组,这样利用matplotlib库函数画图时,就可以正常的显示结果了。

clone的使用
我们看一下使用clone之后,改变原始值是否会对clone后的值进行改变。如下面的测试
- a = torch.from_numpy(np.array([[1,2,3],[4,5,6]])).float()
- b = a.clone()
- print(a)
- print(b)
- # 修改b, 测试a是否会改变
- print('====')
- b[0,1]=torch.tensor(30.0)
- print(a)
- print(b)

可以看到,对上面b的修改,不会改变a的值。
可视化方式
有的时候,我们需要将图像转换为tensor,或是将tensor转换为图像进行可视化,这里记录一下方法。首先导入库。
- from PIL import Image
- import torchvision.transforms as transforms
加载图片, 转换为Tensor
我们使用torchvision.transform来完成转换。 我们可以定义一个loader, 里面进行图片大小的修改和转换为Tensor.
- # 加载图片, 转换为tensor
- device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
- imsize = 512
- loader = transforms.Compose([
- transforms.Resize(imsize), # scale imported image
- transforms.ToTensor()]) # transform it into a torch tensor
- def image_loader(image_name):
- """图片load函数
- """
- image = Image.open(image_name)
- # fake batch dimension required to fit network's input dimensions
- image = loader(image).unsqueeze(0)
- return image.to(device, torch.float)
这样加载图片时,可以直接使用函数image_loader即可。
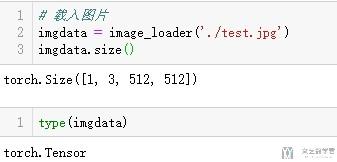
- # 载入图片
- imgdata = image_loader('./test.jpg')
- imgdata.size()
将Tensor转换为图片
这里我们使用transforms.ToPILImage进行转换.
- # 将tensor转换为图片
- image = imgdata.cpu().clone()
- image = image.squeeze(0)
- unloader = transforms.ToPILImage()
- unloader(image) # 转换为PIL image
图片压缩过了,有些看不清代码了,代码和上面是一样的。
PIL: Thumbnail and end up with a square image
使用PIL将图片保存为正方形的图像。
- from PIL import Image, ImageOps
- thumb = ImageOps.fit(image, size, Image.ANTIALIAS)
测试Max Pooling, Mean Pooling
使用Max Pooling
- # 测试Max Pooling
- m = nn.MaxPool2d(kernel_size=4,stride=4)
- maximgdata = m(imgdata)
- maximgdata.size()
- > torch.Size([1, 3, 128, 128])
- # 进行可视化
- # 可以看到使用maxpool后人眼大概观察是相同的
- unloader(maximgdata.cpu().squeeze(0))

- # 测试Average Pool
- m = nn.AvgPool2d(kernel_size=4,stride=4)
- avgimgdata = m(imgdata)
- avgimgdata.size()
- > torch.Size([1, 3, 128, 128])
- # 使用均值效果好像更好一些
- unloader(avgimgdata.cpu().squeeze(0))

hook的使用
我们可以简单理解一下,hook是用来获得网络中间的一些值的,主要有下面的两种。
参考链接 : pytorch中的钩子(Hook)有何作用?
关于hook的一个更加好的用法,可以查看这个链接(这里定义了类, 使用起来会更加方便) : CNN可视化Convolutional Features
register_hook
register_hook,是针对Variable对象的。
- import torch
- from torch.autograd import Variable
下面我们对下图中的表达式求梯度,其中y作为中间变量,pytorch是不会保存其梯度的。
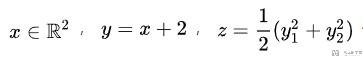
- x = Variable(torch.randn(2, 1), requires_grad=True)
- y = x+2
- z = torch.mean(torch.pow(y, 2))
- lr = 1e-3
- z.backward() # 计算梯度
- x.grad.data
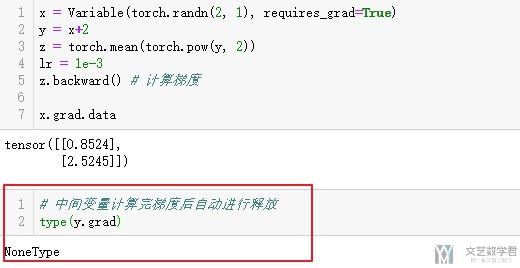
但是,我们可以使用register_hook来保存y的梯度.
关于register_hook的简单使用如下:
The hook will be called every time after forward() has computed an output. It should have the following signature:
- hook(grad) -> Tensor or None
具体的我们看一下下面的这个例子。
- # 我们可以定义一个hook来保存中间的变量
- def variable_hook(grad):
- print('y的梯度\n',grad)
- x = Variable(torch.randn(2, 1), requires_grad=True)
- y = x+2
- # 注册hook
- hook_handle = y.register_hook(variable_hook)
- z = torch.mean(torch.pow(y, 2))
- z.backward() # 计算梯度
- print('x的梯度\n',x.grad.data)
- # 使用完毕之后需要移除hook
- hook_handle.remove()
可以看到此时是可以打印出y的梯度的。
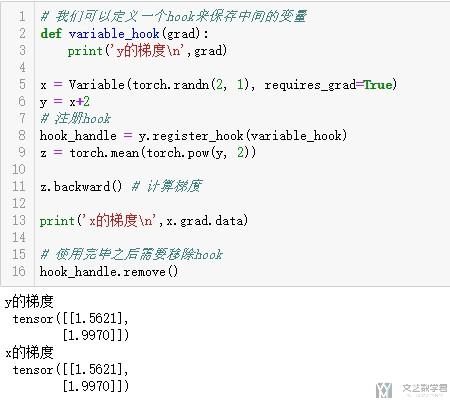
需要注意的是,在使用之后,需要移除hook,如果之后不需要使用的话.
hook module
除了上面可以hook变量外,我们还可以hook住nn.Module这个对象。下面是文档对该函数的介绍。
The hook will be called every time after forward() has computed an output. It should have the following signature:
- hook(module, input, output) -> None
我们还是看一下具体的例子。首先定义网络,我们定义一个简单的网络。
- class testModel(nn.Module):
- def __init__(self):
- super(testModel, self).__init__()
- self.linear1 = nn.Linear(2,2,bias=False)
- self.linear2 = nn.Linear(2,2,bias=False)
- def forward(self,x):
- out = self.linear2(self.linear1(x))
- return out
接着我们初始化模型,并进行参数的初始化(这一步是为了方便我们看最后的结果)
- # 模型初始化
- testmodel = testModel()
- # 打印初始参数
- print('====原始系数====')
- for num, (name, params) in enumerate(testmodel.named_parameters()):
- print(num,params.data.shape,'\n',params.data)
- # 参数初始化
- # 做初始化系数
- testmodel.linear1.weight.data = torch.FloatTensor([[1,2],[3,4]])
- testmodel.linear2.weight.data = torch.FloatTensor([[5,6],[7,8]])
- # 重新打印新的系数
- print('====更新系数====')
- for num, (name, params) in enumerate(testmodel.named_parameters()):
- print(num,params.data.shape,'\n',params.data)

接着我们定义hook,并注册hook。注意这里一定是需要return hook的,如果按照下面的这种写法。
- # 全局变量, 存储每一个的输出
- activation = {}
- # 定义hook
- def get_linear(name):
- """返回某一层的传播值
- """
- def hook(module,input,output):
- print('module:\n',module)
- print('input:\n',input)
- print('output:\n',output)
- activation[name]=output.detach()
- print('====')
- return hook
- # 注册hook
- hook_handle1 = testmodel.linear1.register_forward_hook(get_linear('linear1'))
- hook_handle2 = testmodel.linear2.register_forward_hook(get_linear('linear2'))
注意上面代码,有两部分。第一部分是定义了一个全局变量,用来存储每一次output的输出;另一个是把每一次的input和output都打印出来.
最后我们定义变量,并进行正向传播。
- # 定义变量
- input_data = Variable(torch.FloatTensor([[1,2]]))
- print(input_data)
- # 正向传播
- out = testmodel(input_data)
- print(out)
可以看到将每一步的值都进行了输出。
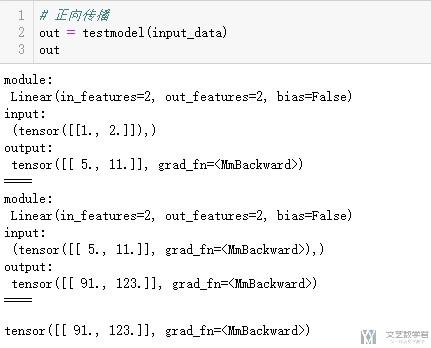
我们再看一下前面定义的全局变量,可以看到也是添加进了input的值。

最后我们注意要将hook进行移除(保持好的习惯)
- hook_handle1.remove()
- hook_handle2.remove()
网络传播过程去参数的初始化
还是使用上面hook例子中的网络结构,在下面再重复一遍。
- class testModel(nn.Module):
- def __init__(self):
- super(testModel, self).__init__()
- self.linear1 = nn.Linear(2,2,bias=False)
- self.linear2 = nn.Linear(2,2,bias=False)
- def forward(self,x):
- out = self.linear2(self.linear1(x))
- return out
网络权重的初始化
- # 模型初始化
- testmodel = testModel()
- # 打印初始参数
- print('====原始系数====')
- for num, (name, params) in enumerate(testmodel.named_parameters()):
- print(num,params.data.shape,'\n',params.data)
- # 参数初始化
- # 做初始化系数
- testmodel.linear1.weight.data = torch.FloatTensor([[1,2],[3,4]])
- testmodel.linear2.weight.data = torch.FloatTensor([[5,6],[7,8]])
- # 重新打印新的系数
- print('====更新系数====')
- for num, (name, params) in enumerate(testmodel.named_parameters()):
- print(num,params.data.shape,'\n',params.data)
正向传播
- # 定义变量
- input_data = Variable(torch.FloatTensor([[1,2]]))
- # 正向传播
- out = testmodel(input_data)
- out
- > tensor([[ 91., 123.]], grad_fn=<MmBackward>)
这一步相当于下面的矩阵运算, 注意一下上面权重初始化的时候的值。
- # 使用矩阵运算进行测试
- import numpy as np
- # 这里相当于 [[5,6],[7,8]] * [[1,2],[3,4]] * [1.2]
- x_input = np.array([1,2])
- x1_test = np.array([[1,2],[3,4]])
- x2_test = np.array([[5,6],[7,8]])
- np.dot(x2_test,np.dot(x1_test,x_input))
- > array([ 91, 123])
nn神经网络组件
MaxPool2d 与 MaxUnpool2d
原理解释
关于MaxUnpool2d的过程,可以简单看下面图的解释。关于Pytorch中的一些内容,可以查看下面的链接进行了解,About MaxPool and MaxUnpool
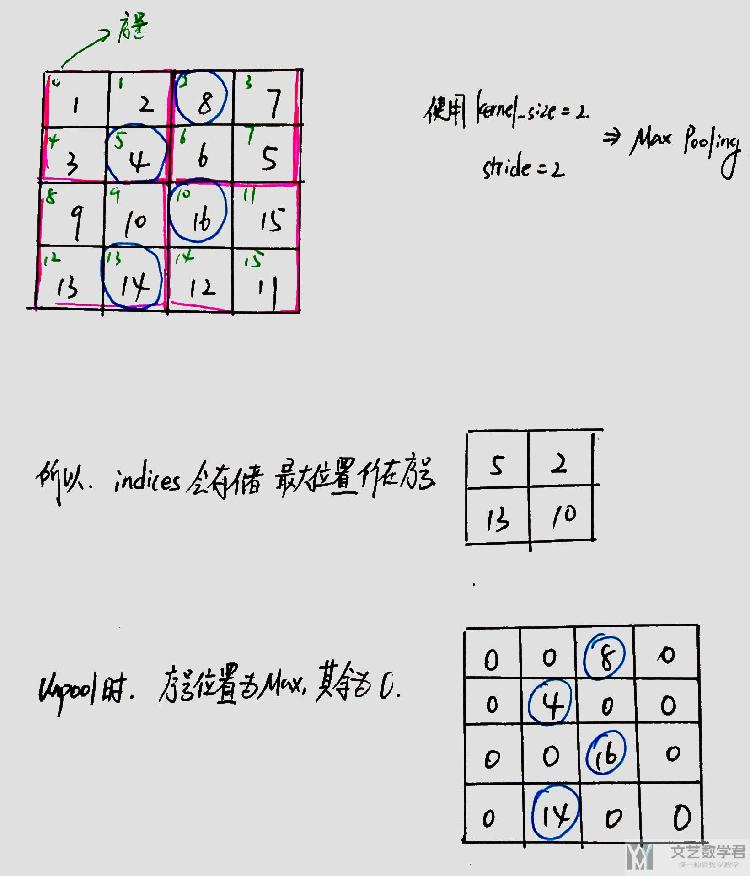
其中的indices会用来保存在MaxPool过程中最大点的序号;在还原的时候,序号位置为最大的值,其他位置均为0。(这是在Pytorch中MaxUnpool2d的实现的大概过程)
当然,这里会遇到一个问题,即这不是一个一一对应的关系,两个大小不同的矩阵,在经过Maxpool后大小可能是一样的,所以还原的时候需要指定output_size的大小。下面是一个简单的解释。
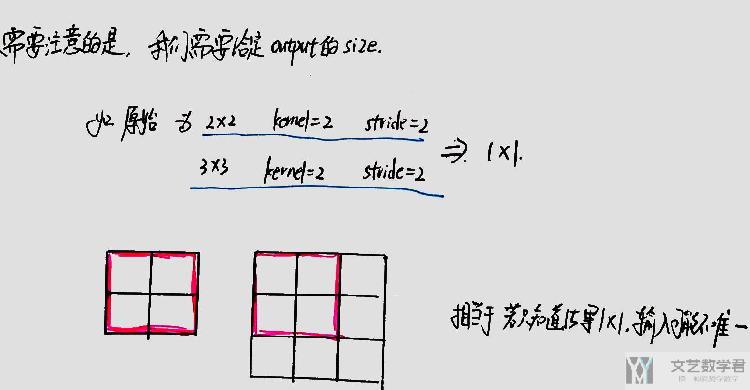
例子演示
下面看一下在Pytorch中具体的使用的方式。
- # MaxPooling的测试,这里一定要输出return_indices
- m = nn.MaxPool2d(kernel_size=2,stride=2,padding=0,return_indices=True)
- inputData = torch.tensor([[[[ 1., 2, 8, 7],
- [ 3, 4, 6, 5],
- [ 9, 10, 16, 15],
- [13, 14, 12, 11]]]])
- out,indices = m(inputData)
我们看一下池化后的矩阵与indices的值。
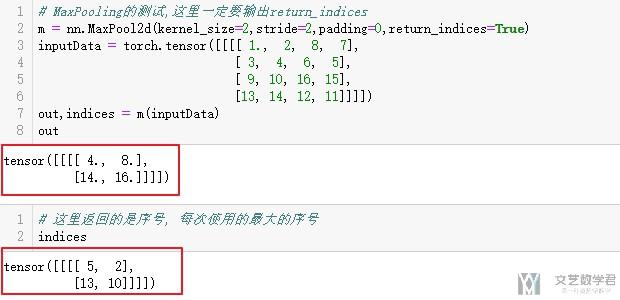
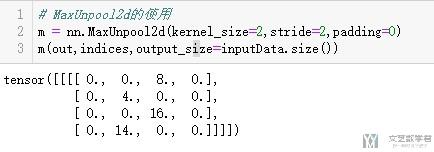
接着我们使用MaxUnpool2d来进行还原,注意还原的过程中需要输入indices和output_size。其余关于kernel_size和stride值得设置,只需要设置为和MaxPool2d时一样得即可.
- # MaxUnpool2d的使用
- m = nn.MaxUnpool2d(kernel_size=2,stride=2,padding=0)
- m(out,indices,output_size=inputData.size())
Conv2d使用介绍
新的pic的长宽可以通过下面的式子计算得到。

- m = nn.Conv2d(in_channels=3,out_channels=1,kernel_size=3,stride=1,padding=0)
- inputData = torch.ones(1, 3, 9, 9)
- out = m(inputData)
- out.size()
- > torch.Size([1, 1, 7, 7])
上面的例子中,我们输出的图片大小为399,经过卷积之后,变为177
ConvTransposed2d使用介绍
ConvTransposed2d其实就是进行卷积变换。直观可以参考下面链接的动态图的展示。
https://github.com/vdumoulin/conv_arithmetic
其中在Pytorch中,新的长宽可以由下面的式子计算得到:
- H_out = (H_in−1)×stride[0]−2×padding[0]+dilation[0]×(kernel_size[0]−1)+output_padding[0]+1
- W_out = (W_in−1)×stride[1]−2×padding[1]+dilation[1]×(kernel_size[1]−1)+output_padding[1]+1
我们可以看一下下面的这个例子,将上面经过卷积之后的结果进行还原。即原本是399,经过卷积之后为177,这里希望还原为399的大小。
- m = nn.ConvTranspose2d(in_channels=1,out_channels=3,kernel_size=3,stride=1,padding=0)
- inputData = torch.ones(1, 1, 7, 7)
- out = m(inputData)
- out.size()
- > torch.Size([1, 3, 9, 9])
上面例子是stride=1的情况,实际上在stride>1的时候,会出现和上面Pool一样的情况,即不是一一对应的关系。
还是同样的问题,原始大小为22与33的图像,在经过kernel=2,stride=2之后均为11的大小,所以在ConvTransposed2d的时候,有一个参数output_padding需要进行设置。我们看一下下面的这个例子。可以看到原始图像经过卷积后大小为11的
- m = nn.Conv2d(in_channels=3,out_channels=1,kernel_size=2,stride=2,padding=0)
- inputData = torch.ones(1, 3, 3, 3)
- out = m(inputData)
- out.size()
- > torch.Size([1, 1, 1, 1])
在output_padding=0的情况下,可以看到转换的结果为原始图片大小为2*2的。
- # output_padding=0的情况
- m = nn.ConvTranspose2d(in_channels=1,out_channels=3,kernel_size=2,stride=2,padding=0,output_padding=0)
- inputData = torch.ones(1, 1, 1, 1)
- out = m(inputData)
- out.size()
- > torch.Size([1, 3, 2, 2])
在output_padding=1的情况下,可以看到转换的结果为原始图片大小为3*3的。所以,我们需要通过output_padding来控制输出的大小。
- # output_padding=1的情况
- m = nn.ConvTranspose2d(in_channels=1,out_channels=3,kernel_size=2,stride=2,padding=0,output_padding=1)
- inputData = torch.ones(1, 1, 1, 1)
- out = m(inputData)
- out.size()
- > torch.Size([1, 3, 3, 3])
ConvTransposed2d与MaxUnpool2d结合
下面把两个结合看一下,放一个小的例子.首先定义encode和decode,还有input.
- # encode
- conv = nn.Conv2d(in_channels=3,out_channels=1,kernel_size=2,stride=2,padding=0)
- maxpool = nn.MaxPool2d(kernel_size=2,stride=2,padding=0,return_indices=True)
- # decode
- maxunpool = nn.MaxUnpool2d(kernel_size=2,stride=2,padding=0)
- convtranspose = nn.ConvTranspose2d(in_channels=1,out_channels=3,kernel_size=2,stride=2,padding=0,output_padding=1)
- # input
- inputdata = torch.ones(1,3,9,9)
接着就看一下输出和输出的大小即可。
- # encode
- conv_output = conv(inputdata)
- encode_output,indices = maxpool(conv_output)
- # decode
- decode_output = convtranspose(maxunpool(encode_output,indices,output_size=conv_output.size()))
- decode_output.size()
- > torch.Size([1, 3, 9, 9])
可以看到可以成功还原大小。
functional.pad使用说明
关于functional.pad的详细说明, 可以参考链接, functional.pad, 这个函数的作用就是可以对数组进行填充, 就是一个手动填充的过程
- to pad only the last dimension of the input tensor, then pad has the form (padding_left, padding_right), 如果pad只有前两个数字, 就表示要对左右进行pad, 我们后面会有一个例子;
- to pad the last 2 dimensions of the input tensor, then use (padding_left,padding_right, padding_top, padding_bottom), 同样pad四个数字, 就是对四周进行填充;
- to pad the last 3 dimensions, use (padding_left, padding_right, padding_top, padding_bottom, padding_front, padding_back), 这里是6个数字, 就是对三维进行填充;
下面我们来看一下例子.
- t4d = torch.ones(4, 4)
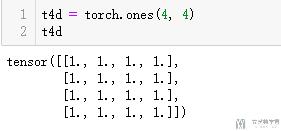
我们对上面的t4d进行填充, 首先填充左侧和右侧.
- torch.nn.functional.pad(t4d, (1,2), "constant", 0)
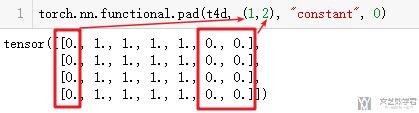
同时, 我们可以对其四周进行填充.
- torch.nn.functional.pad(t4d, (0,1,2,3), "constant", 0)
最终的结果如下所示.
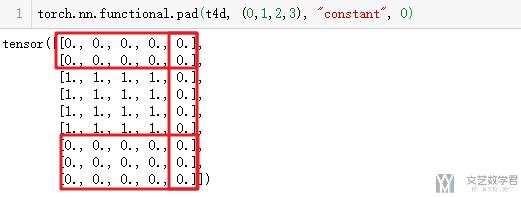
对于padding back和padding front, 我们就直接看一下最终的效果.

结语

- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论